Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
包括集群资源管理器(Cluster Manager)、多个运行作业任务的工作结点(Worker Node)、每个应用的任务控制结点(Driver)和每个工作结点上负责具体任务的执行进程(Executor)。
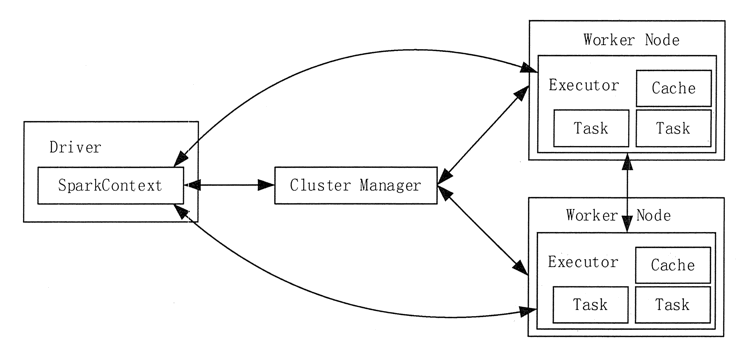
2.请详细阐述Spark的几个主要概念及相互关系:RDD,DAG,Application, job,stage,task,Master, worker, driver,executor,Claster Manager
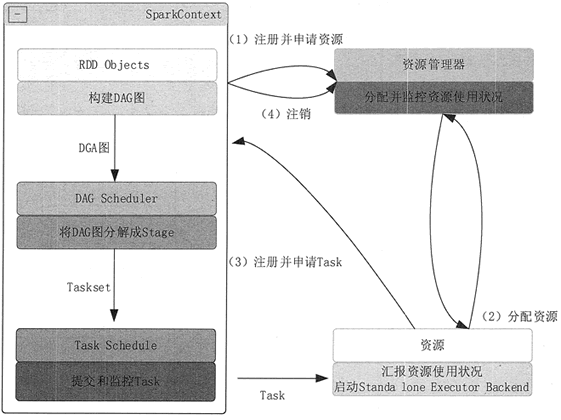
1)构建 Spark Application 的运行环境(启动 SparkContext),SparkContext 向 Cluster Manager 注册,并申请运行 Executor 资源。
2)Cluster Manager 为 Executor 分配资源并启动 Executor 进程,Executor 运行情况将随着“心跳”发送到 Cluster Manager 上。
3)SparkContext 构建 DAG 图,将 DAG 图分解成多个 Stage,并把每个 Stage 的 TaskSet(任务集)发送给 Task Scheduler (任务调度器)。Executor 向 SparkContext 申请 Task, Task Scheduler 将 Task 发放给 Executor,同时,SparkContext 将应用程序代码发放给 Executor。
4)Task 在 Executor 上运行,把执行结果反馈给 Task Scheduler,然后再反馈给 DAG Scheduler。运行完毕后写入数据,SparkContext 向 ClusterManager 注销并释放所有资源。
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、Structured Streaming、MLlib和GraphX等组件,各个组件的具体功能如下:
Spark Core:Spark Core包含Spark最基础和最核心的功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等,主要面向批数据处理。
Spark SQL:Spark SQL是用于结构化数据处理的组件,允许开发人员直接处理RDD,同时也可查询Hive,HBase等外部数据源。
Spark Streaming:Spark Streaming是一种流计算框架,可以支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。
Structrued Streaming:Structured Streaming是一种基于Spark SQL引擎构建的、可扩展且容错的流处理引擎。
MLlib:MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只需具备一定的理论知识就能进行机器学习的工作。
GraphX:GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写和优化,GraphX性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
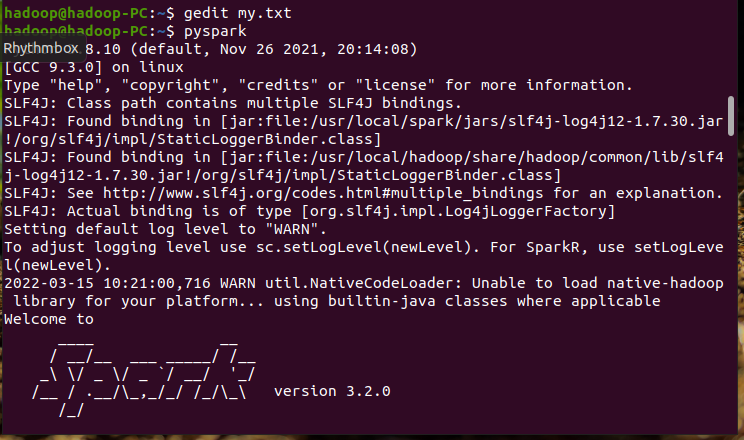
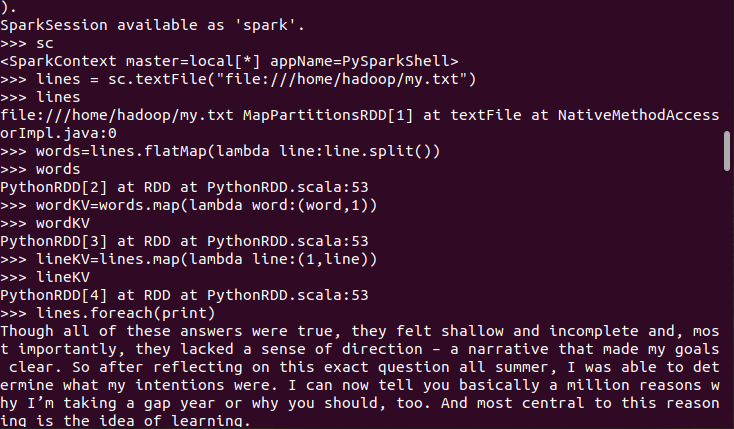
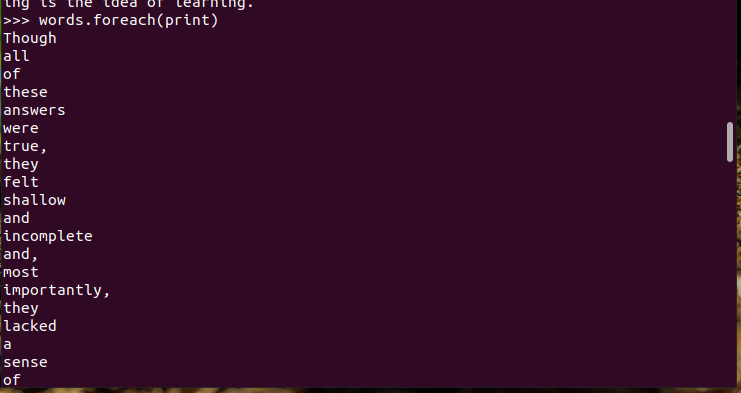
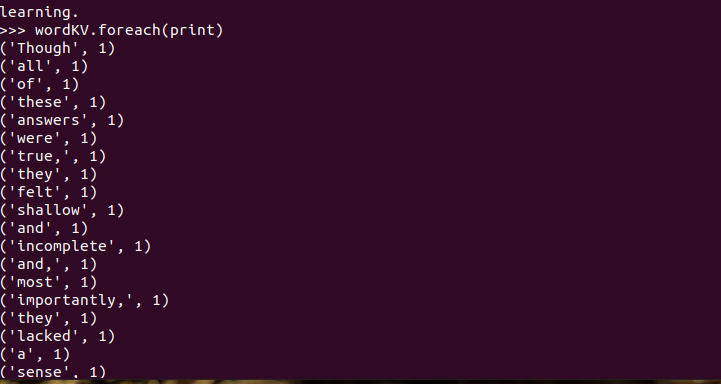
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
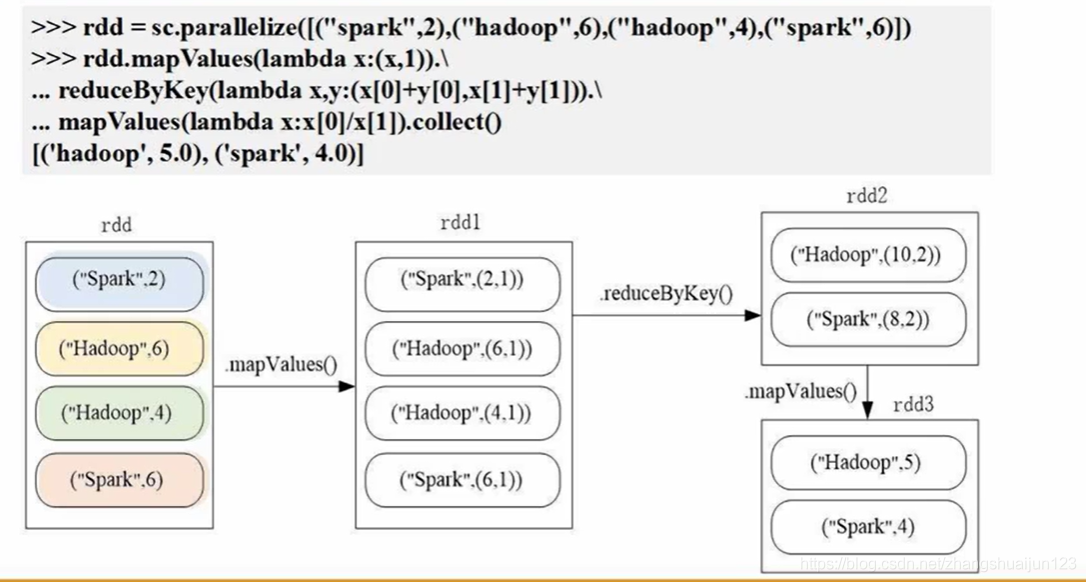
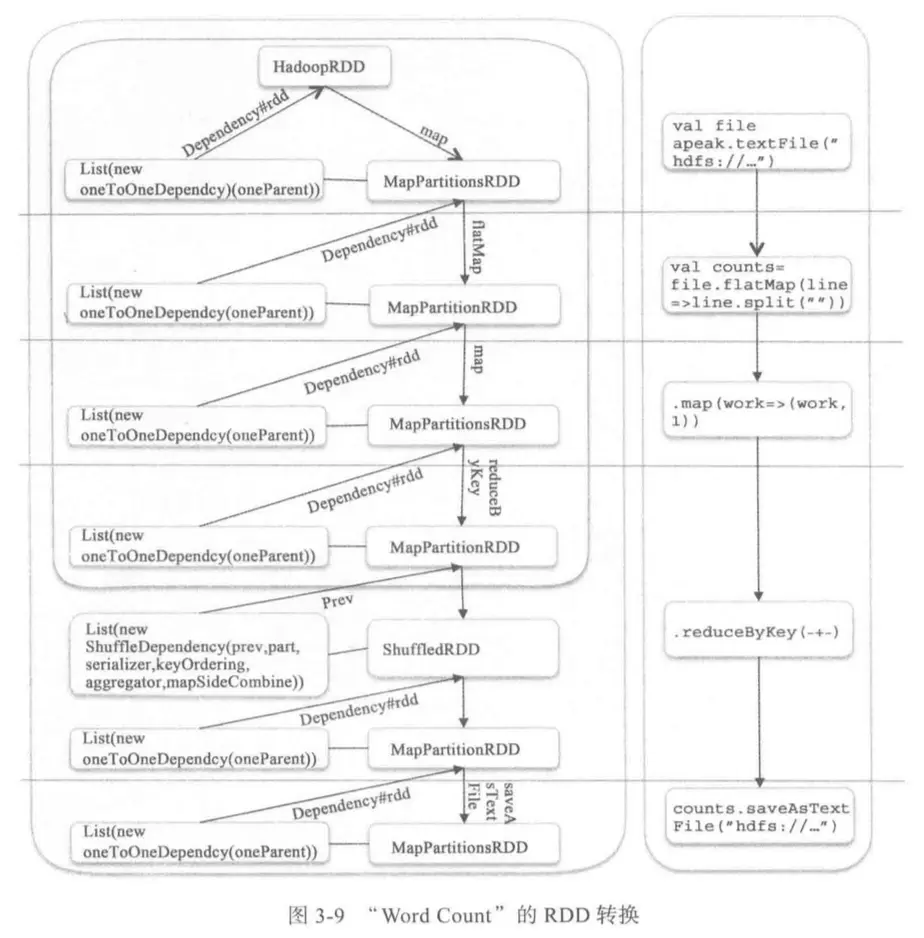
具体操作如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号