intellij-idea打包Scala代码在spark中运行
、创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容:
<properties>
<spark.version>2.1.1</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
其中保存之后,需要点击下面的import change,这样相当于是下载jar包
二、编写一个Scala程序,统计单词的个数
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object WordCount { def main(args: Array[String]) { if (args.length == 0) { System.err.println("Usage: spark.example.WordCount <input> <output>") System.exit(1) } val input_path = args(0).toString val output_path = args(1).toString val conf = new SparkConf().setAppName("WordCount") conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") val sc = new SparkContext(conf) val inputFile = sc.textFile(input_path) val countResult = inputFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) .map(x => x._1 + "\t" + x._2) .saveAsTextFile(output_path) } }
三、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
然后填写定义的类名,选择copy to..选项(打包这一个类)

点击ok之后,然后build->build Artifacts->build,等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包

四、运行在spark集群上面
1. 把jar包放到能访问spark集群的机器上面
2. 运行
/usr/local/spark/bin/spark-submit --class WordCount --master spark://master:7077 /data/wangzai/package/WordCount.jar \ hdfs://master:9000/spark/test.data hdfs://master:9000/spark_output/spark_wordcount \ --executor-memory 1G \ --executor-cores 1 \ --num-executors 10
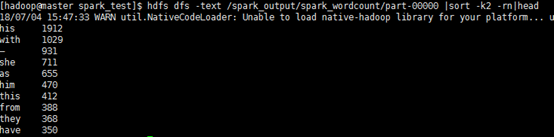
3. 结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号