scrapy爬取用户信息 ---崔志才
这个实例还是值得多次看的
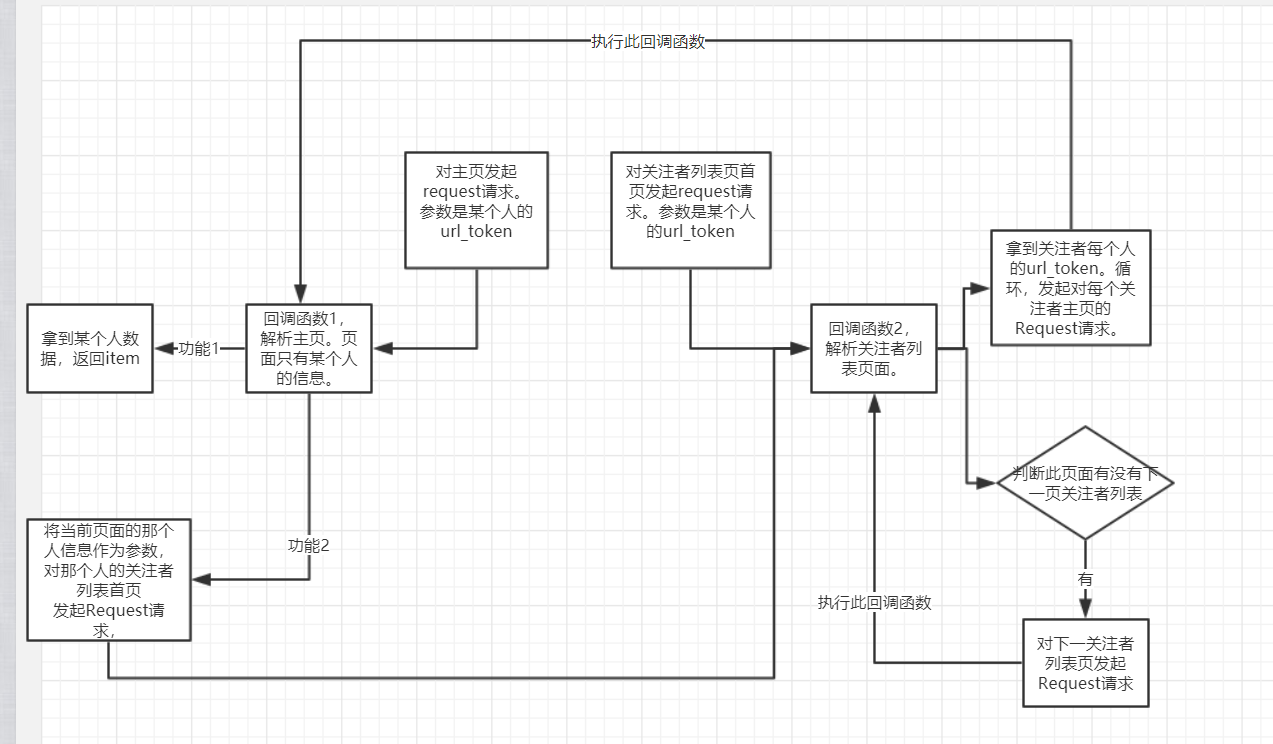
其流程图如下,还是有一点绕的。
总结:
1 Requst(rul=' xxx ',callback= ' '),仅仅发起 某个网页 的访问请求,没啥了。剩下的交给回调函数
2 parse_()。对 某个页面 经过下载后的 数据 进行处理,包括逻辑判断,有可能比较复杂,提取想要的数据等等。最终,返回item,或 Request对象,也可以两者都返回。 有的回调函数返回一个request对象,这个request对象调用本身这个回调函数。如:判断是否有下一页的情况就可以写成递归函数。猜想:这种情况下,肯定有条件判断,来终止递归的执行。
3 回调函数可以有很多个。回调函数也是函数,实现不同的功能,对不同的response执行不同的逻辑,所以肯定是有多个回调函数的。
4 同时,回调函数既然是函数,函数之间可以互相调用,回调函数之间同样也可以互相调用。
5 乍一看,回调函数可以回返回很多Request对象,不要慌,不要紧张,随他去,所有的request对象都叫个调度器管理。每个request都只是对某个页面的请求而已。request对象固然多,一个一个来,慢慢来。顺序是由调度器决定,一个request到了,经过下载器,然后在执行回调函数。这就是一个request的流程。走完后,它的功能已经实现了。
不要管回调函数返回的是啥,可能是item,也可能是request对象。这个时候这里的request对象是一个完全新的request对象,它有他自己的流程。它在调度器里等,直到调度器安排说,到你了,出来吧。
6 即便是用scrapy框架写,也最好思路明确。耦合性要低。别想着一个start_requests,一个paser就能搞定。
上代码
pipeline.py
文档中有现成的代码
稍微修改了下,理由upsert方法,实现对数据的去重。item本身就是一个字典。所以 {'$set':item},是没有问题的。
import pymongo class MongoPipeline(object): collection_name = 'userinfo' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE', 'items') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): # print(item) if item['url_token']: self.db[self.collection_name].update({'url_token':item['url_token']},{'$set':item},True) return item
zhihu.py
from scrapy import Spider,Request from zhihu.items import * import json class ZhihuUserinfoSpider(Spider): name = 'zhihu' allowed_domains = ['www.zhihu.com'] # start_urls = ['http://www.zhihu.com/'] start_user = 'https://www.zhihu.com/api/v4/members/{}?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics' start_followee = 'https://www.zhihu.com/api/v4/members/{}/followees?offset={}&limit={}' # 随便填一个注册过的名字url_token,都是可以的。都会都json数据返回。 def start_requests(self): ''' 对某个用户页面,对某个用户其关注者的页面发起请求。Request,只管发起请求,可以这样简单理解。 :return: ''' yield Request(url=self.start_user.format('valarmorghulis'),callback=self.parse_user) yield Request(url=self.start_followee.format('valarmorghulis',0,20),callback=self.parse_followees,) def parse_user(self,response): ''' 解析 页面--->某个用户信息进行解析。只管对拿到的response数据进行解析。哪个Request的回调函数是它,它就解析这个Request生成的数据。 :param response: :return: ''' result = json.loads(response.text) item = UserInfoItem() for field in item.fields: if field in result.keys(): item[field] = result.get(field) yield item url_token = result.get('url_token') yield Request(url=self.start_followee.format(url_token,0,20),callback=self.parse_followees) def parse_followees(self,response): ''' 有时候回调函数就是自己,这个就是个很好的例子。 解析某一页的数据,拿到用户的url_token,对每个url_token发起请求,调用self.parse_user。并判断是否有下一页。 如果有,发起访问请求,拿到这一页数据,解析这一页数据。。。递归调用自己 :param response: :return: ''' result = json.loads(response.text) if result.get('data'): for data in result.get('data'): url_token = data.get('url_token') yield Request(url=self.start_user.format(url_token),callback=self.parse_user) if result.get('paging') and result.get('paging').get('is_end') == False: next = result.get('paging').get('next') yield Request(url=next,callback=self.parse_followees)
settings.py
user_agent肯定是要有的。
authorization 这应该就是反扒措施。服务器要求必须有的一个字段。如果没有,会报401错误。自己试了好久,没试出来。自己试了cookie,以及其它的一些key。长点心吧。
来源是百度的解释:
您的Web服务器认为,客户端(例如您的浏览器或我们的 CheckUpDown 机器人)发送的 HTTP 数据流是正确的,但进入网址 (URL) 资源 , 需要用户身份验证 , 而相关信息 1 )尚未被提供, 或 2 )已提供但没有通过授权测试。这就是通常所知的“ HTTP 基本验证 ”。 需客户端提供的验证请求在 HTTP 协议中被定义为 WWW – 验证标头字段 (WWW-Authenticate header field) 。
DEFAULT_REQUEST_HEADERS = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36', 'authorization': 'Bearer 2|1:0|10:1523006417|4:z_c0|92:Mi4xU2lGZ0FBQUFBQUFBOE8taEQ2Um1EU1lBQUFCZ0FsVk4wWW0wV3dDcFItSkVsME8ycEs2SHRWaG9xdWJvY3VBdzRR|f54e22b627da25b200b9467fef2702fa0f57be6961389f62f4f0d39520f8fe1b', }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号