【Python数据挖掘】第六篇--特征工程
一、Standardization
方法一:StandardScaler
from sklearn.preprocessing import StandardScaler sds = StandardScaler() sds.fit(x_train) x_train_sds = sds.transform(x_train) x_test_sds = sds.transform(x_test)
方法二:MinMaxScaler 特征缩放至特定范围 , default=(0, 1)
from sklearn.preprocessing import MinMaxScaler mns = MinMaxScaler((0,1)) mns.fit(x_train) x_train_mns = mns.transform(x_train) x_test_mns = mns.transform(x_test)
二、Normalization 使单个样本具有单位范数的缩放操作。 经常在文本分类和聚类当中使用。
from sklearn.preprocessing import Normalizer normalizer = Normalizer() normalizer.fit(x_train) x_train_nor = normalizer.transform(x_train) x_test_nor = normalizer.transform(x_test)
三、Binarization 特征二值化是将数值型特征变成布尔型特征。
from sklearn.preprocessing import Binarizer bi = Binarizer(threshold=0.0) # 设置阈值默认0.0 大于阈值设置为1 , 小于阈值设置为0 XX = bi.fit_transform(x_train["xx"]) # shape (1行,X列) x_train["XX"] = XX.T # x_train["XX"] = XX[0,:]
四、连续性变量划分份数
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False) x:array-like # 要分箱的数组 bin:int # 在x范围内的等宽单元的数量。
pd.cut(df["XXX"],5)
进行分箱操作后得到得值是字符串,还需要进行Encoding categorical features
五、one-hot Encoding / Encoding categorical features
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False) dummy_na=False # 是否把 missing value单独存放一列 pd.get_dummies(df , columns = ['xx' , 'xx' , ... ])
六、Imputation of missing values 缺失值处理
①、将无限大,无限小,Missing Value (NaN)替换成其他值;
②、sklearn 不接收包含NaN的值;
class sklearn.preprocessing.Imputer(missing_values='NaN', strategy='mean', axis=0, verbose=0, copy=True) strategy : (default=”mean”) # median , most_frequent axis : (default=”0”) # 表示用列上所有值进行计算 from sklearn.preprocessing import Imputer im =Imputer() im.fit_transform(df['xxx'])
③、使用无意义的值来填充,如-999。
df.replace( np.inf , np.nan ) # 先用NaN值替换,再用-999填充NaN值。 df.fillna(-999) df.fillna(-1) # 注意: -1与标准化的数值可能有意义关系
七、Feature selection 特征选择
①:基于 L1-based feature selection

from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(xdata,ydata)
lasso.coef_ # 查看特征系数
array([ 1.85720489, 0. , -0.03700954, 0.09217834, -0.01157946,
-0.53603543, 0.72312094, -0.231194 , 1.26363755, -0. ,
0. , -0. , 0. , 0. , 0. ,
-0. , -0. , -0. , 0. , -0. ,
0. , 5.21977984, -0. , -0. , 7.00192208,
-0. , 0. , 0. , -0. ])
可以发现,经过One-hot Encod的变量都变成0 , 需要手工进一步筛选 , 不能去掉One-hot的变量 !
利用模型进行筛选的方法:
class sklearn.feature_selection.SelectFromModel(estimator, threshold=None, prefit=False) from sklearn.feature_selection import SelectFromModel model = SelectFromModel(lasso,prefit=True) x_new = model.transform(xdata)
②:基于 Tree-based feature selection
采用 Random Forests
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(xdata,ydata)
rf.feature_importances_
array([ 8.76227379e-02, 4.41726855e-02, 2.12394498e-02,
1.98631826e-01, 1.75612945e-02, 6.72095736e-02,
4.25518536e-01, 3.50132246e-02, 7.23241098e-02, ... ]
非线性模型, 没有系数, 只有变量重要性!!!!
变量重要性大,放前面, 小的删除或者放后面
③:基于Removing features with low variance 移除所有方差不满足阈值的特征
class sklearn.feature_selection.VarianceThreshold(threshold=0.0) from sklearn.feature_selection import VarianceThreshold v = VarianceThreshold(1) v.fit_transform(xdata)
④:基于Univariate feature selection 单变量特征选择
1、SelectKBest 移除得分前 k 名以外的所有特征
class sklearn.feature_selection.SelectKBest(score_func=<function f_classif>, k=10) score_func : 统计指标函数 K : 个数
模型衡量指标:

导入相应的函数即可!
from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_regression skb = SelectKBest(f_regression,k=10) skb.fit_transform(xdata,ydata) xdata.shape
2、移除得分在用户指定百分比以后的特征
class sklearn.feature_selection.SelectPercentile(score_func=<function f_classif>, percentile=10) score_func:采用统计指标函数 percentile:百分数
推荐使用 Feature importtance , Tree-base > L1-base > ... //
八、Dimensionality reduction 减少要考虑的随机变量的数量
方法一:PCA ,主成分分析 , 计算协方差矩阵
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None) # n_components : 设置留下来几列 from sklearn.decomposition import PCA pca = PCA(15) newdata = pca.fit_transform(xdata) newdata.shape
univariate feature selection 与 PCA 区别:
1/ 计算每一个feature 统计量 , 然后选择前几个
2/ PCA 是考虑整个数据集 , 列与列存在关系 , 计算整个矩阵方差共线,
pca.explained_variance_ # 可解释的方差 pca.explained_variance_ratio_ # 百分比
注意:PCA 前先将数据进行标准化!!!
from sklearn.preprocessing import StandardScaler ss = StandardScaler() pca.fit_transform(ss.fit_transform(xdata))
方法二:TruncatedSVD
TruncatedSVD 原来N列 可以选择指定保留k列 , 降维
SVD 产生N*N矩阵 , 没有降维
sklearn.decomposition.TruncatedSVD(n_components=2, algorithm='randomized', n_iter=5, random_state=None, tol=0.0) n_components:int , 输出数据的期望维度。
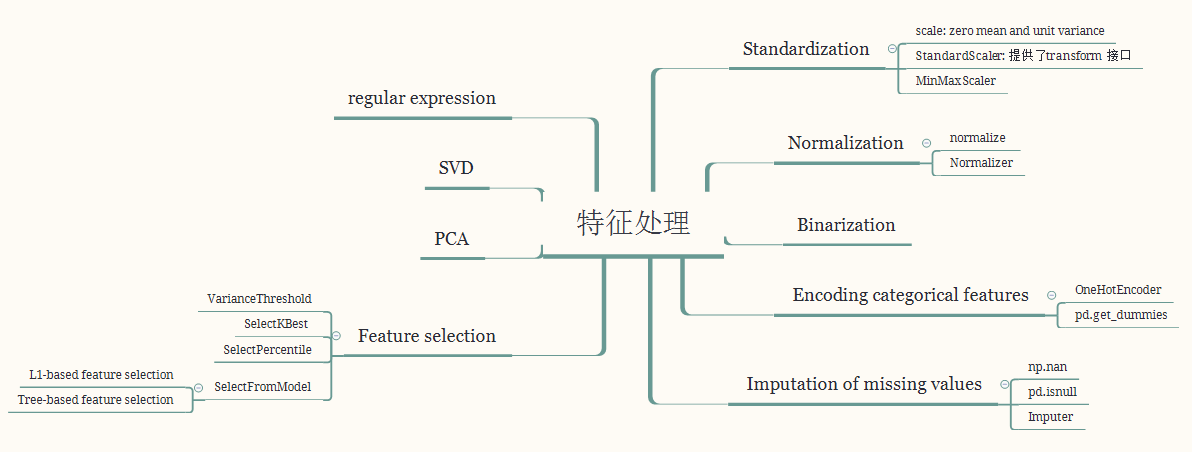
九、思维导图
十、fit、fit_transform和transform的区别
我们使用sklearn进行文本特征提取/预处理数据。可以看到除训练,预测和评估以外,处理其他工作的类都实现了3个方法:fit、transform和fit_transform。
从命名中可以看到,fit_transform方法是先调用fit然后调用transform,我们只需要关注fit方法和transform方法即可。
transform方法主要用来对特征进行转换。从可利用信息的角度来说,转换分为无信息转换和有信息转换。
-
无信息转换是指不利用任何其他信息进行转换,比如指数、对数函数转换等。
-
有信息转换从是否利用目标值向量又可分为无监督转换和有监督转换。
-
无监督转换指只利用特征的统计信息的转换,统计信息包括均值、标准差、边界等等,比如标准化、PCA法降维等。
-
有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征、LDA法降维等。
-
通过总结常用的转换类,我们得到下表:
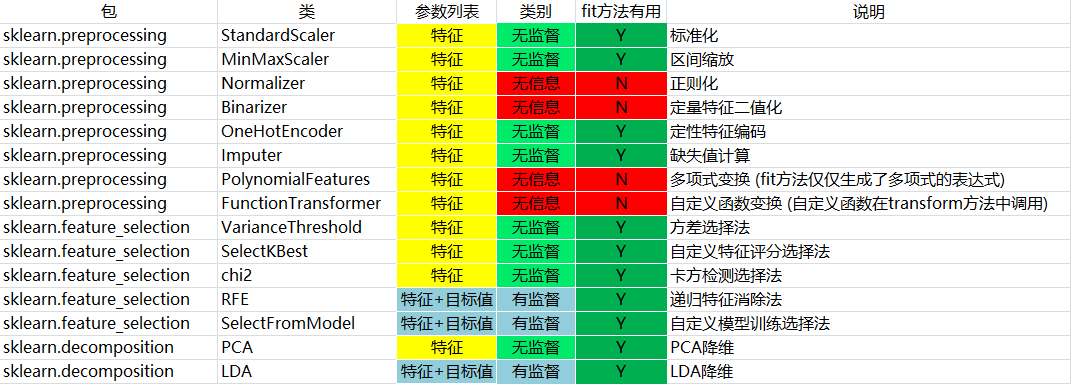
fit方法主要对整列,整个feature进行操作,但是对于处理样本独立的操作类,fit操作没有实质作用!
十一、特征工程选择
-
时间
-
空间
-
比率值
-
变化率





变化率例子: 10月 : (20% - 10%) / 10% = 100%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号