

数据清洗
数据清洗
数据清洗概念:
数据分析过程:
明确需求>>>收集采集>>>数据清洗>>>数据分析>>>数据报告(数据可视化)

数据清洗专业定义:
数据清洗是从记录表,表格,数据库中检测,纠正或删除损坏或者不正确的记录的过程

专业名词解释:
脏数据:没有经过处理自身含有一定问题的数据(缺失,异常,重复)
干净的数据:可以直接带人模型的数据(或者是已经处理过的数据)
处理数据的常见方式:
1.读取外部数据:
read_csv();read_excel();read_html();read_sql()
2.数据概览:
data.index 概览行索引

data.columns 查看有哪些列字段

data.head() 查看前五条数据
data.tail() 查看后五条数据
data.shape() 查看有几行几列

data.describe() 概览数据
data.info() 查看表格数据
data.dtypes() 查看各个列字段的数据类型

3.简单处理 (移除收尾空格,大小写转换)
4.重复值处理
duplicated()查看是否含有重复数据
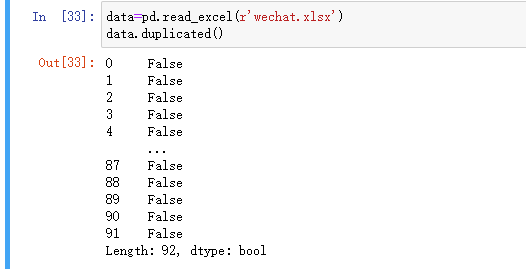
当中的省略部分可以通过.sum()求和查看是否有重复值

通过drop_duplicates()删除重复数据
5.缺失值的处理
fillna() 填充缺失值
dropna()删除缺失值
isnull()/notnull() 查看是否有缺失值
6.异常值的处理
删除异常值,修正异常值
7.字符串处理
切割,填充,筛选
8.时间格式处理
Y (year 年) m(month 月) d(day 日) H(hour 小时)M(minute 分)S(second 秒)
# 步骤三到步骤八没有固定顺序
实战练习:
现有文件: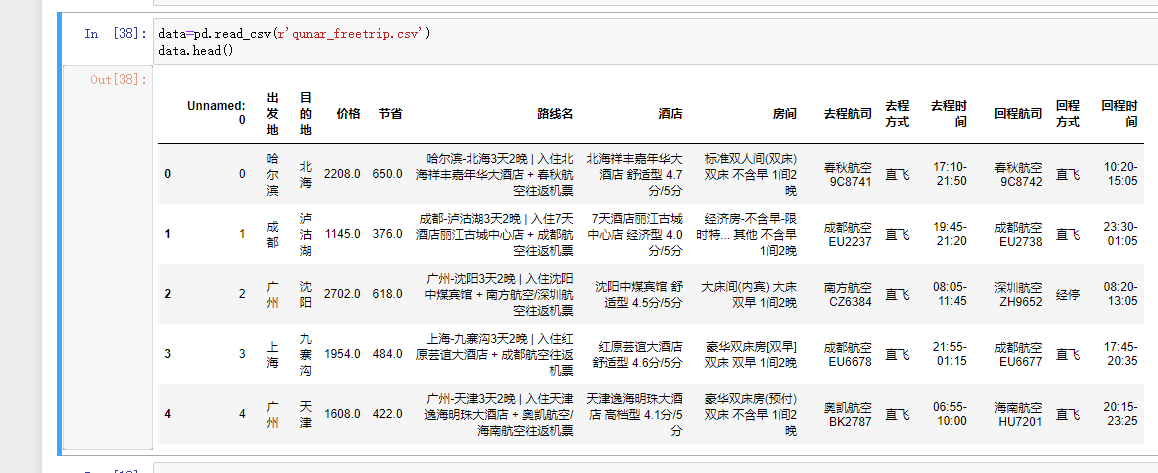
进行数据概览



处理表格数据:
①删除列字段:无用字段
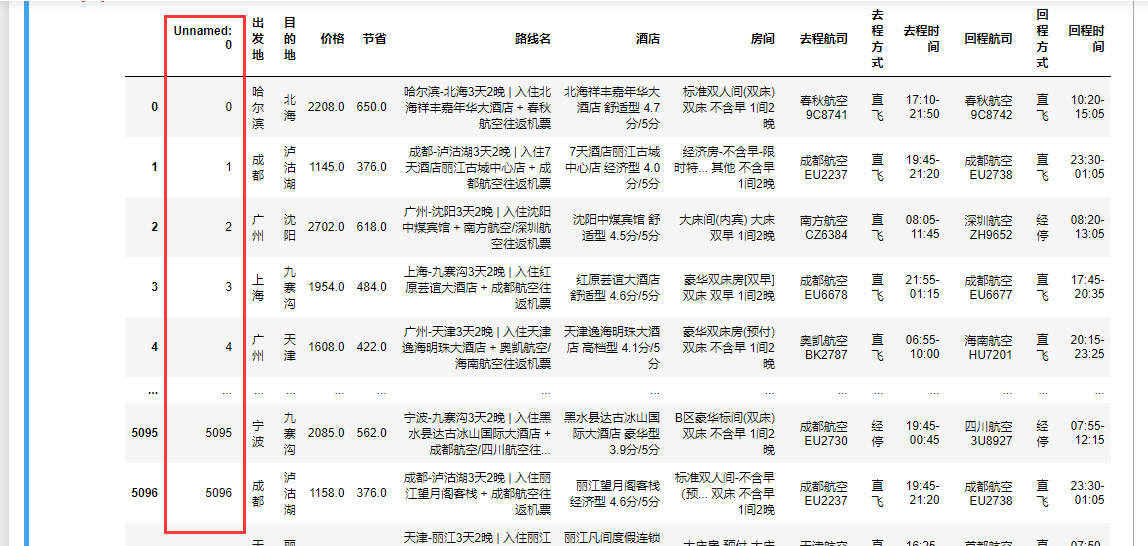
data.drop(columns='Unnamed:0')

直接有结果显示 需要加上参数 inplace=True 提交修改

②:去除列字段收尾的空格

data=pd.read_csv(r'qunar_freetrip.csv') res1=[] # 定义一个新列表 res=data.columns.values #获取colums列字段的值 for i in res: # 将res的内容循环写入i res1.append(i.strip()) # 写入空列表 并通过.strip()移除首尾空格 data.columns=res1 data.columns

③:重复值处理:
先查看有无重复值
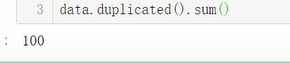
再删除重复值:

删除重复项后 出现index序号混乱的情况:
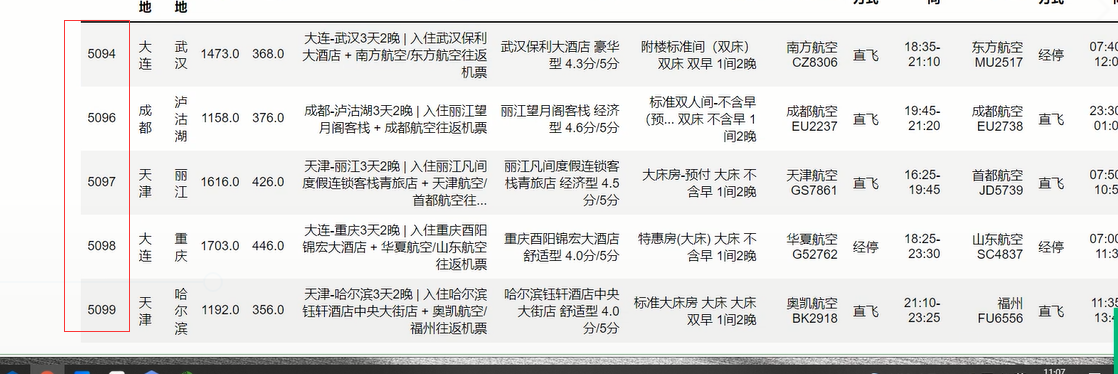
重置index即可

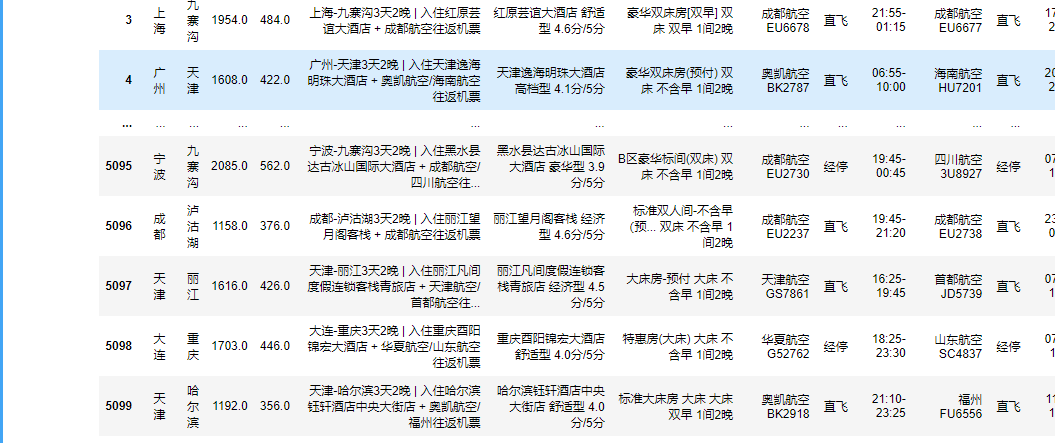
④异常值处理:
通过data.describe()查看数据概览
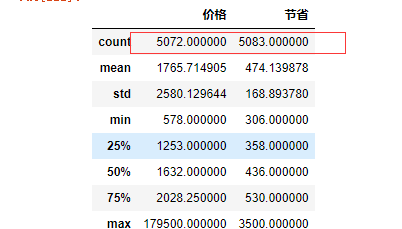
发现消费金额小于打折金额 这是明显不符合常理的
直接使用
df[df['节省'] > df['价格']]
来查看节省大于价格的字段
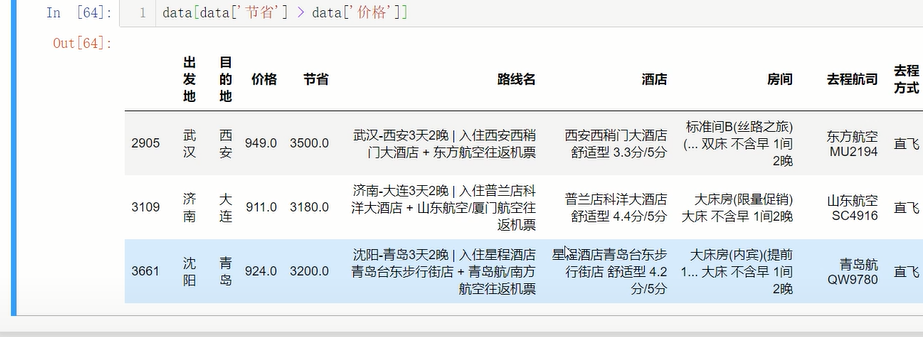
以及通过公式计算得出的一个数据
sd = (df['价格'] - df['价格'].mean()) / df['价格'].std()
df[(sd > 3)|(sd < -3)]
df[abs(sd) > 3]

拼接成一个大列表

最后删除

最后再重置一下索引

⑤缺失值处理:
查看缺失值

查看出发地缺失值数据:
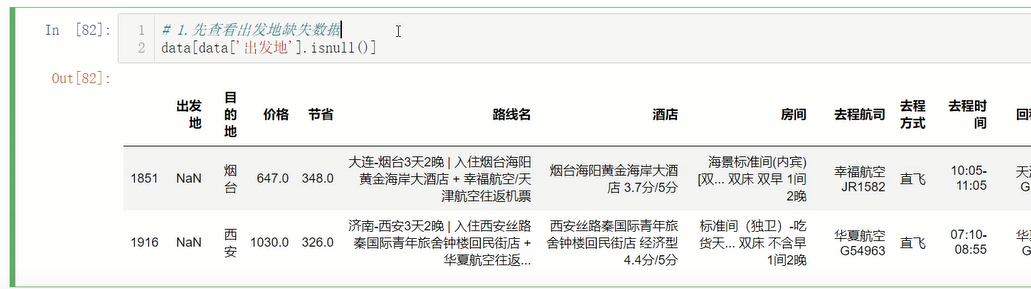
在通过路线名填充

获取路线名的值

这里可以通过正则来获取大连和济南这两个字段并且正则是保证不会错的
将这两段文字复制并赋值d1 和d2
首先需要导入模块
import re

最后获取到大连以及济南
也可以通过字符串的切割获取 比较简单
df.loc[df.出发地.isnull(),'出发地'] = [i.split('-')[0] for i in df.loc[df.出发地.isnull(),'路线名'].values]
针对目的地的缺失值处理:

也是相同的步骤
re.findall('(.*?)\d',d3)
需要注意的是匹配到数字就停止 即\d就是
同样写入
df.loc[df.目的地.isnull(),'目的地'] = [re.findall(reg_exp,i) for i in df.loc[df.目的地.isnull(),'路线名'].values]
价格及节省的缺失值处理
这里可以直接使用平均数填充即可
计算这两个数的均值

然后在进行填充
df['价格'].fillna(round(df['价格'].mean(),1),inplace=True) df['节省'].fillna(round(df['节省'].mean(),1),inplace=True) # round 1是指保留小数后一位
填充完毕后再次验证
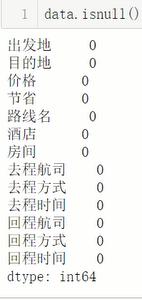
完成.
练习:
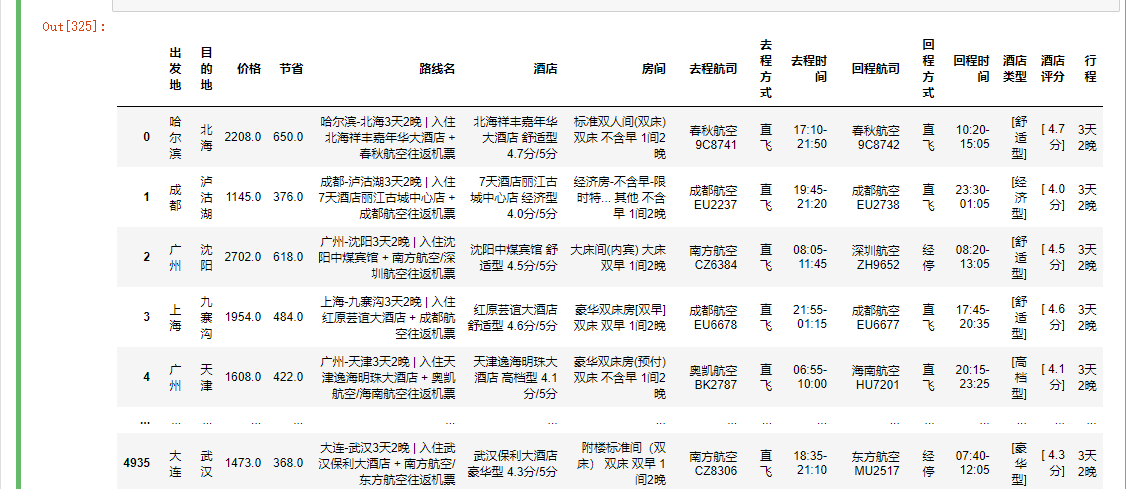
2.新增三个列
分别是酒店类型、酒店评分、游玩时间
import numpy as np import pandas as pd import matplotlib.pyplot as plt import re hotel_level=[] hotel=df['酒店'] #获取酒店列字段所有数据 for i in hotel: #循环读取这些数据 hotel_level.append(re.findall(' (.*?) ',i)) #通过正则匹配 以空格开始 空格结束 df['酒店类型']=hotel_level # 新增新列字段酒店类型 score=[] for a in hotel: score.append(re.findall('型(.*?)/',a)) df['酒店评分']=score time=[] plan=df['路线名'] for b in plan: b1=b.split('|')[0][-5:-1] time=b1 df['行程']=time df

 浙公网安备 33010602011771号
浙公网安备 33010602011771号