
selenium模块基本使用操作及复杂爬虫项目
首先导入模块:
from selenium import webdriver
获取属性
tag.get_attribute('src')
获取标签ID,位置,名称,大小
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size)
模拟浏览器前进后退
from selenium import webdriver import time bro=webdriver.Chrome() bro.get('https://www.taobao.com/') time.sleep(3) bro.forward() #往前进页面 time.sleep(1) bro.back()#往后退页面 time.sleep(1)

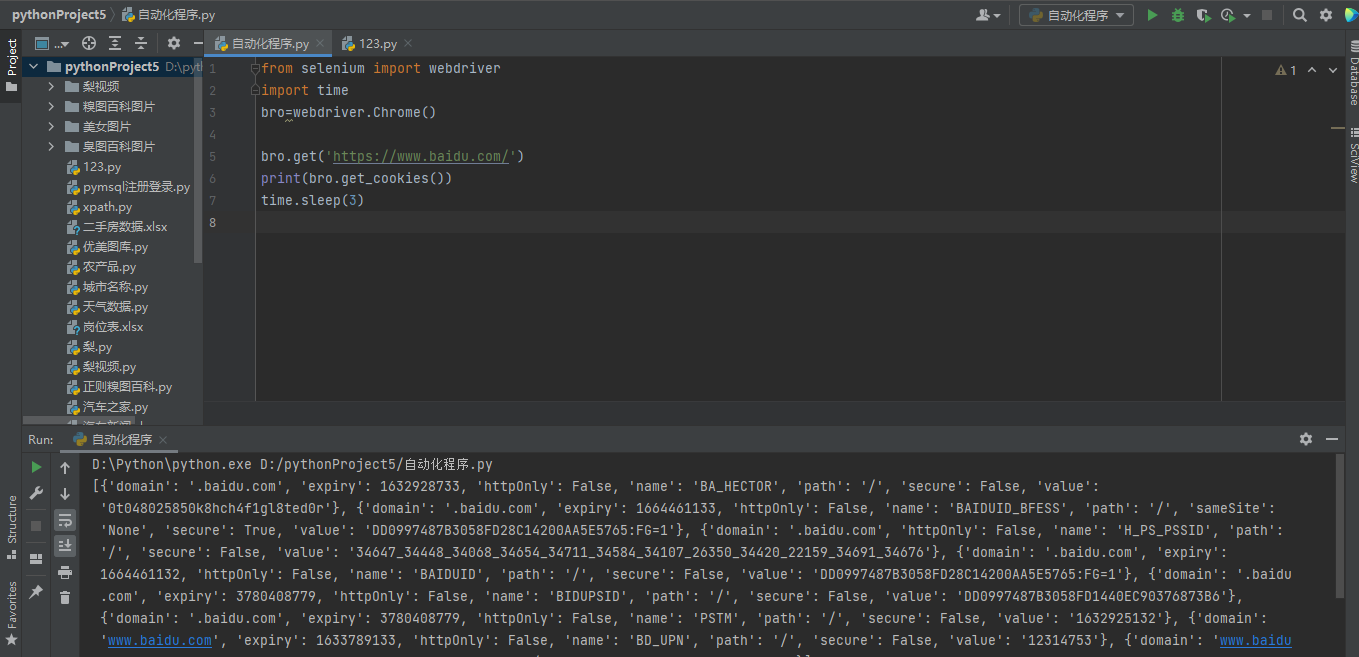
cookies管理
from selenium import webdriver import time bro=webdriver.Chrome() bro.get('https://www.baidu.com/') print(bro.get_cookies()) time.sleep(3)
控制滚轮移动
from selenium import webdriver import time bro=webdriver.Chrome() bro.get("http://www.baidu.com") bro.execute_script('window.scrollTo(0,200)') # 鼠标滚轮移动xt坐标系值 time.sleep(5)
选项卡管理
选项卡就是你打开的各个网页

控制打开关闭以及切换
import time from selenium import webdriver browser=webdriver.Chrome() browser.get('https://www.baidu.com') browser.execute_script('window.open()') print(browser.window_handles) # 获取所有的选项卡 browser.switch_to_window(browser.window_handles[1]) browser.get('https://www.taobao.com') time.sleep(3) browser.switch_to_window(browser.window_handles[0]) browser.get('https://www.sina.com.cn') browser.close()
动作链
页面嵌套页面
# 动作链(页面上嵌套页面>>>iframe) from selenium import webdriver from selenium.webdriver import ActionChains import time driver = webdriver.Chrome() driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') driver.switch_to.frame('iframeResult') # 必须要指定iframe标签 sourse = driver.find_element_by_id('draggable') target = driver.find_element_by_id('droppable') # 方式一:基于同一个动作链串行执行(速度太快不合理) # actions = ActionChains(driver) # 拿到动作链对象 # actions.drag_and_drop(sourse, target) # 把动作放到动作链中,准备串行执行 # actions.perform() # 方式二:不同的动作链,每次移动的位移都不同 actions = ActionChains(driver) actions.click_and_hold(sourse) distance = target.location['x'] - sourse.location['x'] track = 0 while track < distance: actions.move_by_offset(xoffset=2, yoffset=0).perform() track += 5 time.sleep(0.5) actions.release() driver.close()
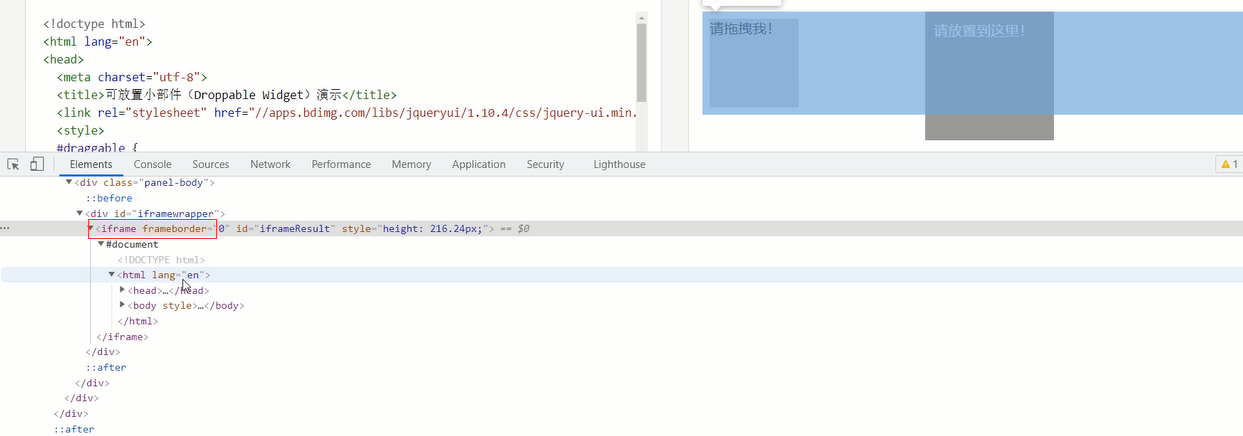
嵌套标签 iframe
关于iframe:
经常会碰到页面上会叠加一个页面,这个叠加的页面一般都是iframe标签,内部也有完整的html文档结构
无界面操作即不显示浏览器 实际后台运行
from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') bro = webdriver.Chrome(chrome_options=chrome_options) bro.get('https://www.baidu.com')
针对selenuim防爬 其实就是为了伪装成正常的浏览器步骤访问网站不被程序分辨
from selenium.webdriver import ChromeOptions option = ChromeOptions() option.add_experimental_option('excludeSwitchers',['enable-automation']) bro = webdriver.Chrome(options=option)
import requests from selenium import webdriver import time import json # 使用selenium打开网址,然后让用户完成手工登录,再获取cookie # url = 'https://account.cnblogs.com/signin?returnUrl=https%3A%2F%2Fwww.cnblogs.com%2F' # driver = webdriver.Chrome() # driver.get(url=url) # time.sleep(30) # 预留时间让用户输入用户名和密码 # driver.refresh() # 刷新页面 # c = driver.get_cookies() # 获取登录成功之后服务端发返回的cookie数据 # print(c) # with open('xxx.txt', 'w') as f: # json.dump(c, f) cookies = {} with open('xxx.txt', 'r') as f: di = json.load(f) # 获取cookie中的name和value,转化成requests可以使用的形式 for cookie in di: cookies[cookie['name']] = cookie['value'] # # 使用该cookie完成请求 # response = requests.get(url='https://i-beta.cnblogs.com/api/user', cookies=cookies) # response.encoding = response.apparent_encoding # print(response.text) """ seleuinm拿cookie requests拿cookie去模拟爬取数据 """
思路1: 完全使用代码破解 但是会有识别误差 图像识别技术 软件:Tesseract-ocr 模块:pytesseract 思路2: 打码平台 花钱买第三方服务 先使用代码识别如果不对 后台其实还有一帮员工肉眼识别 思路3: 自己人工智能识别
""" 先爬取视频的画面 再爬取视频的音频部分 总共分为两个爬取内容 这其实也是一种防爬手段 需要安装ffmpeg来进行视频拼接 """
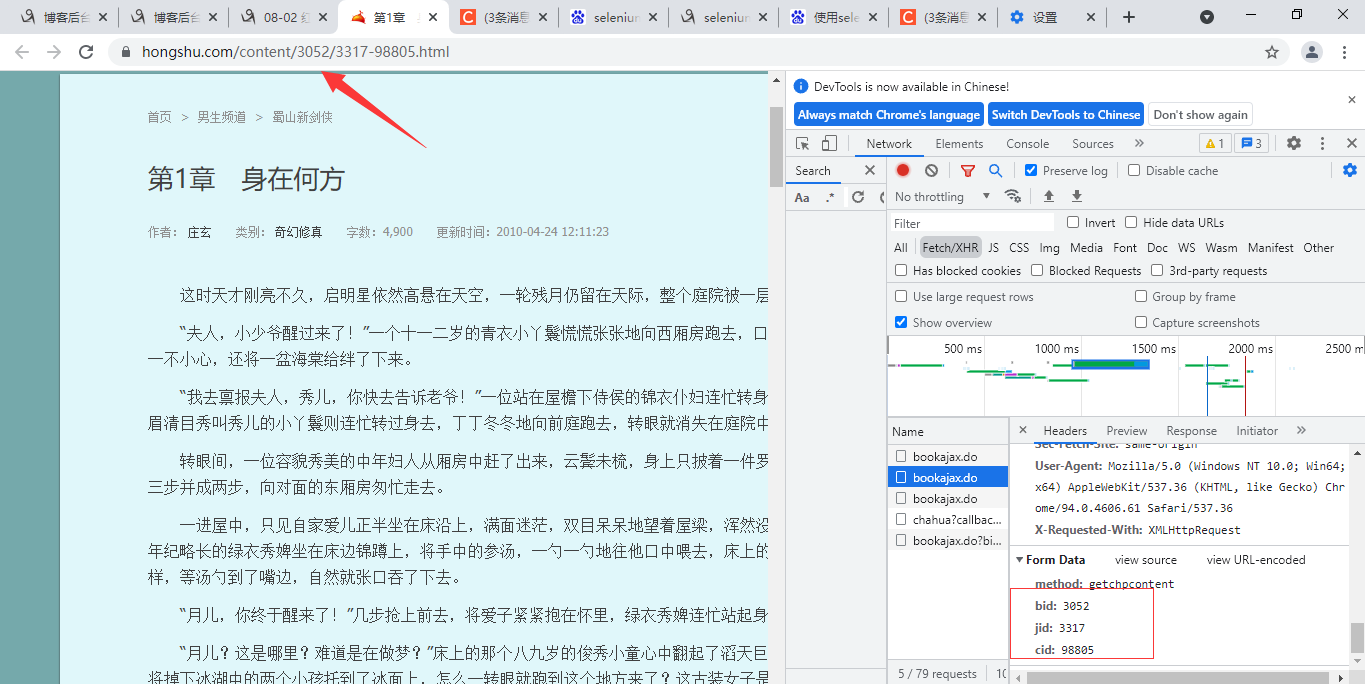
爬取红薯网小说案例(思路)https://www.hongshu.com/content/3052/3317-98805.html(地狱级难度)
1.首先 左右键无法使用 只能使用fn键+f12来调出network
2.文字不是直接加载,查找相关二次请求数据
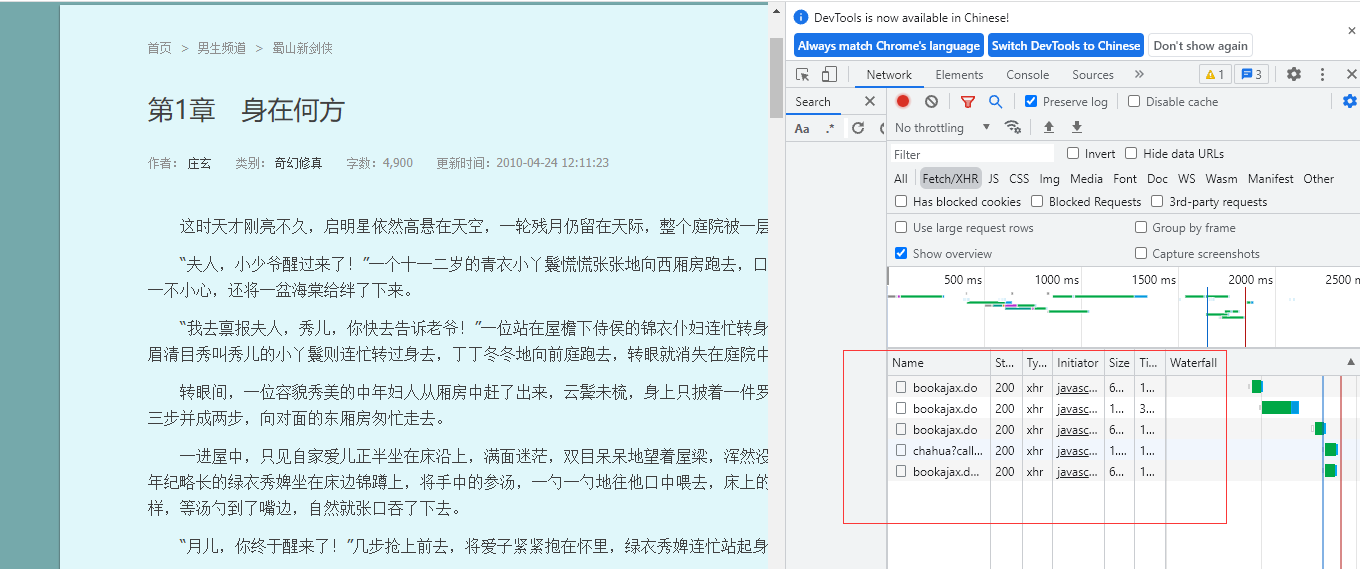
检查五个中的内容
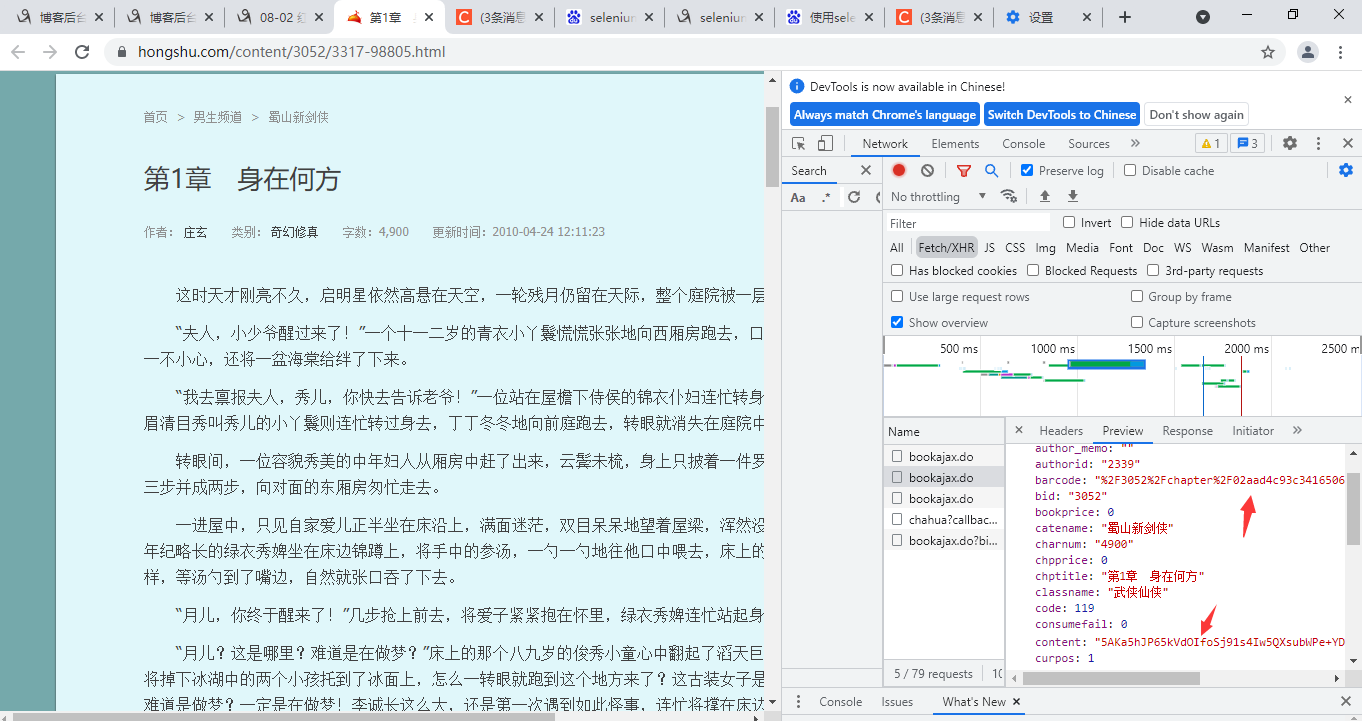
其中第二个有可疑的加密数据
以及在网址内部的数字
4.文字内容的解密过程发送在浏览器本地
涉及到数据解密肯定需要写js代码 并且一般都会出现关键字decrypt
通过浏览器查找相应的js代码
文字主要内容的界面
utf8to16(hs_decrypt(base64decode(data.content), key))
解密之后仍然存在数据缺失的情况
utf8to16(hs_decrypt(base64decode(data.other), key))
解密之后是一段js代码
5.自己新建一个html文件
将content内部拷贝只body内
将js代码引入到该html文件夹

 浙公网安备 33010602011771号
浙公网安备 33010602011771号