

爬取梨视频网站详细过程
爬取娱乐分类视频为例:
https://www.pearvideo.com/category_4
打开网页后观察网页将滚轮条下拉后网站会自动加载
通过检查网页发现每次动态加载一次都会网该网站发送请求
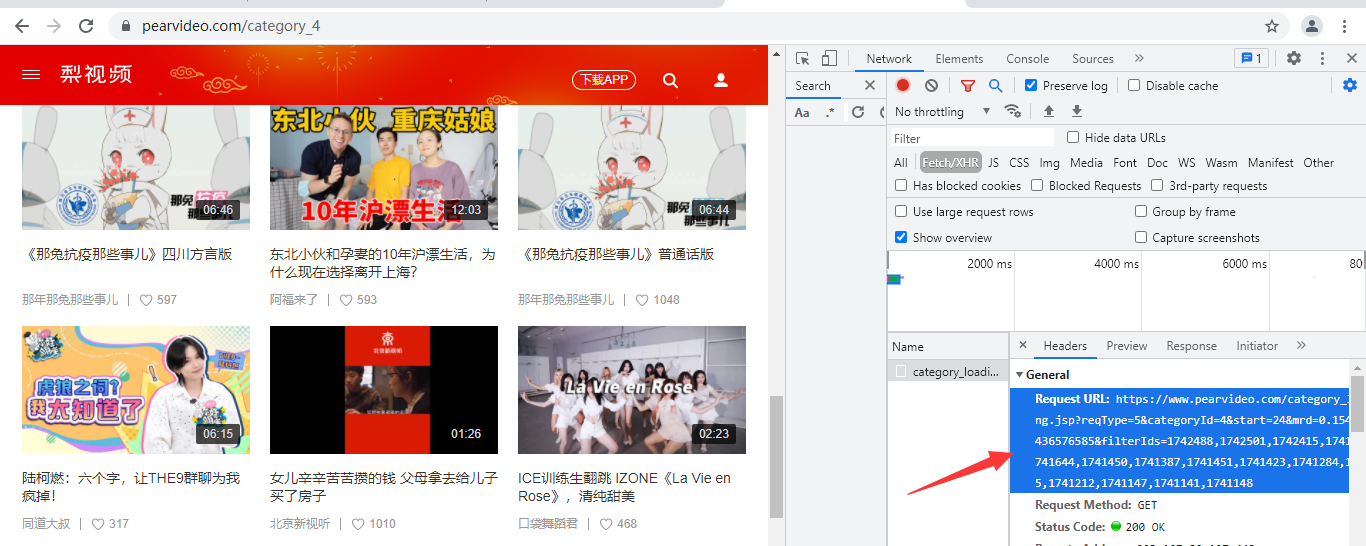
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=4&start=24&mrd=0.15494354436576585&filterIds=1742488,1742501,1742415,1741645,1741644,1741450,1741387,1741451,1741423,1741284,1741275,1741212,1741147,1741141,1741148
再观察下一页的网址
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=4&start=36&mrd=0.8505082367958983&filterIds=1742488,1742501,1742415,1740962,1740897,1740140,1740132,1740022,1740011,1739906,1739797,1739790,1739721,1739702,1739683
可以将start=36/24后面的内容全部删除之后
得出结论 该网页每次加载一次start=的数字都出现12的倍数
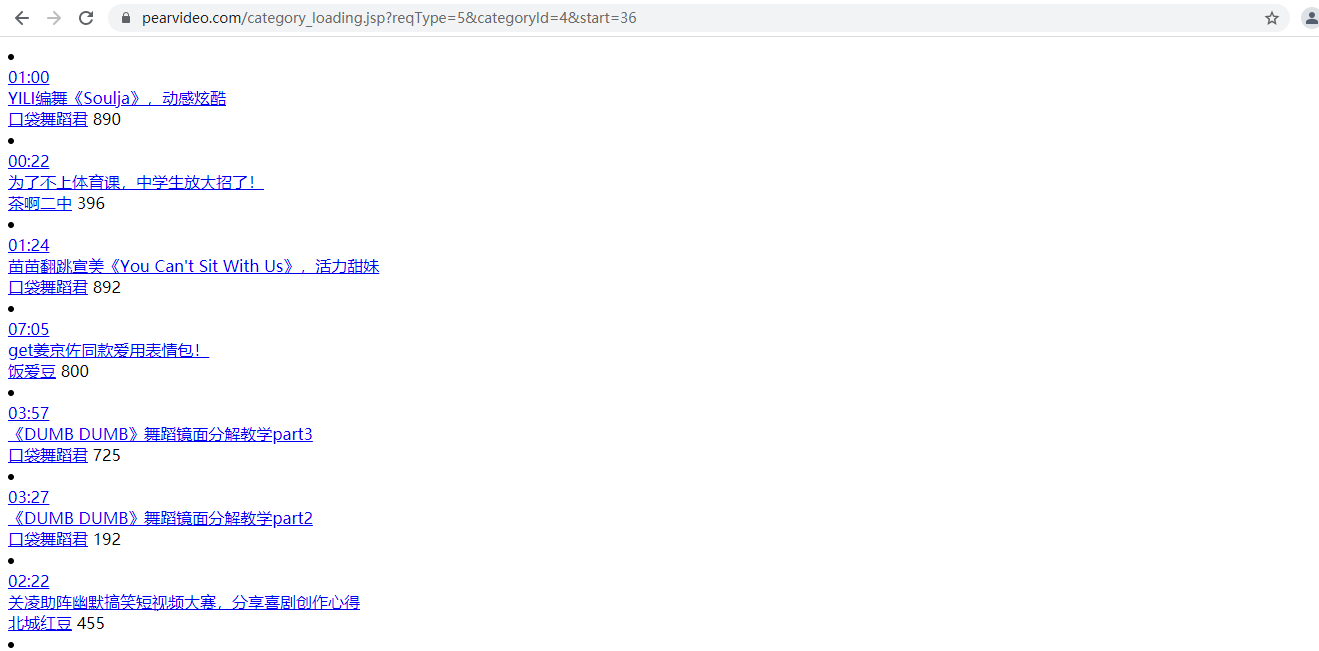
并且是可以打开的

点开之后出现的是视频详情页
再观察每个视频的详情页中的网址为
而向主页发送请求后观察网页源码中有一行标签为
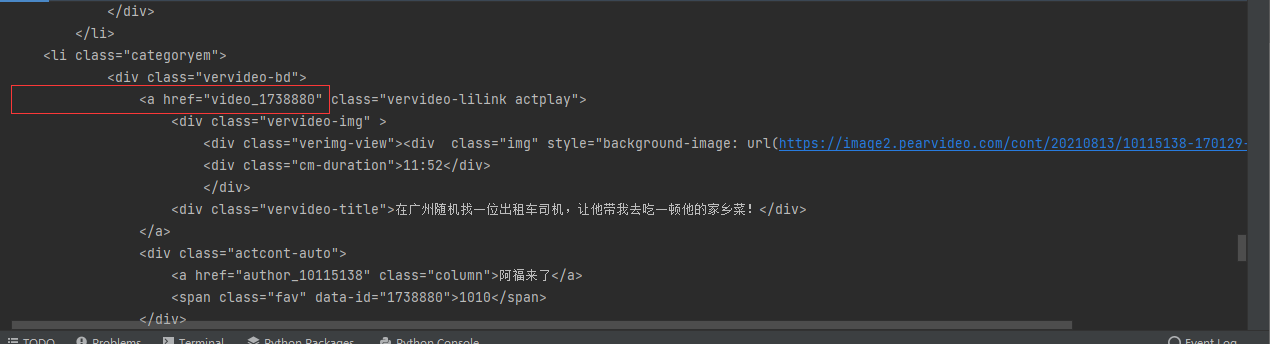
那么就有了大致的方向,向获取class="categoryem"的标签,再做for循环取li标签,在从li标签获取a标签中href的内容
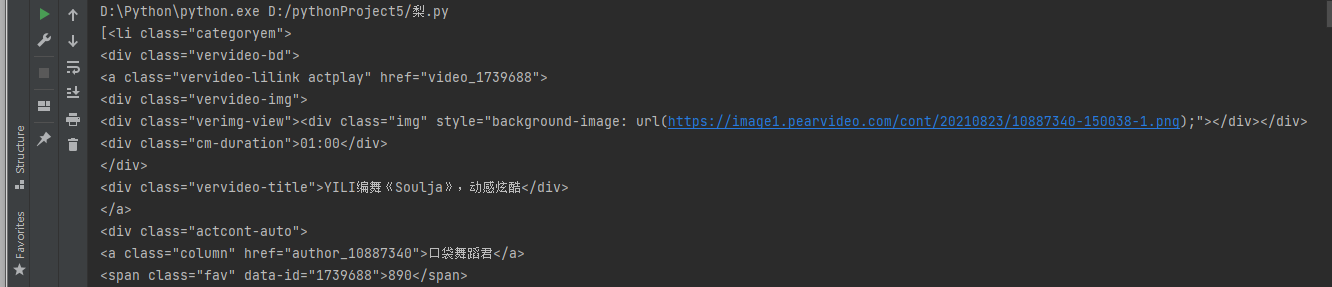

""" 通过观察网页源代码, 发现id号在class=categoryem的标签中, 那我们就通过bs4模块找到class=categoryem的所有标签, 再通过观察,关键内容在class=categoryem下面的li标签, 对li做for循环 循环获取li中的a标签 在获得a标签中的所有href内容即可获得id号 """
进行切割,取纯数字的部分
下一部分
通过观察视频详情页地址的源码发现
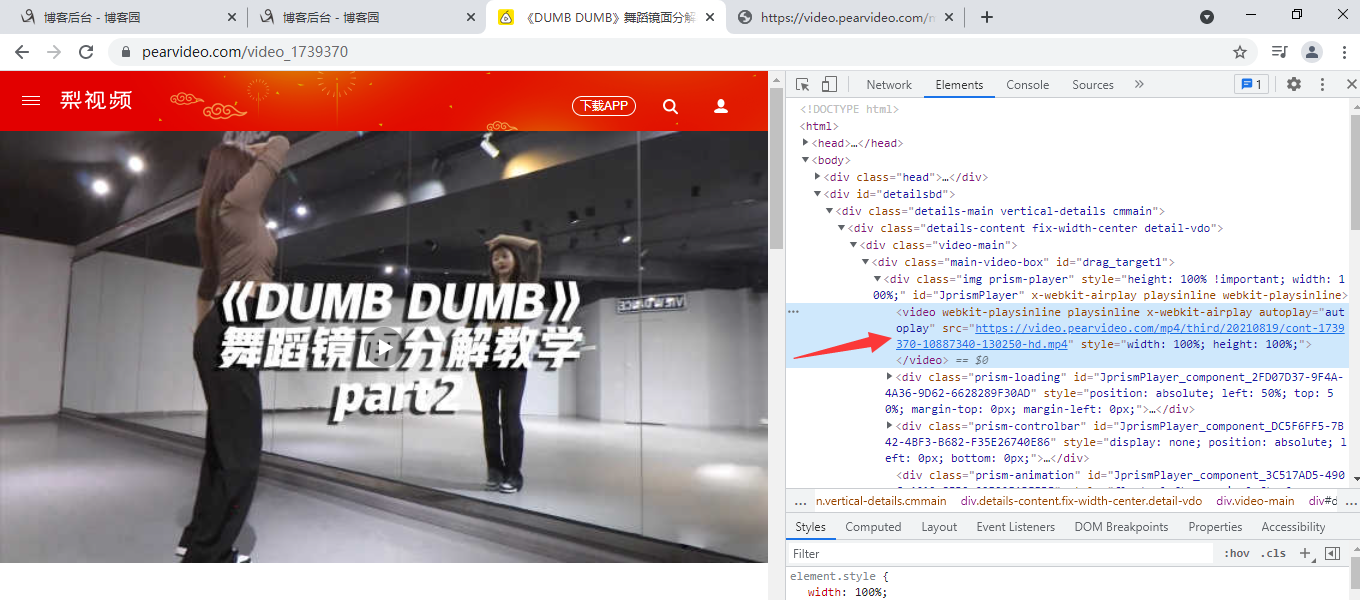
这个网址是真正的视频地址

检查视频详情页后台发送的网址
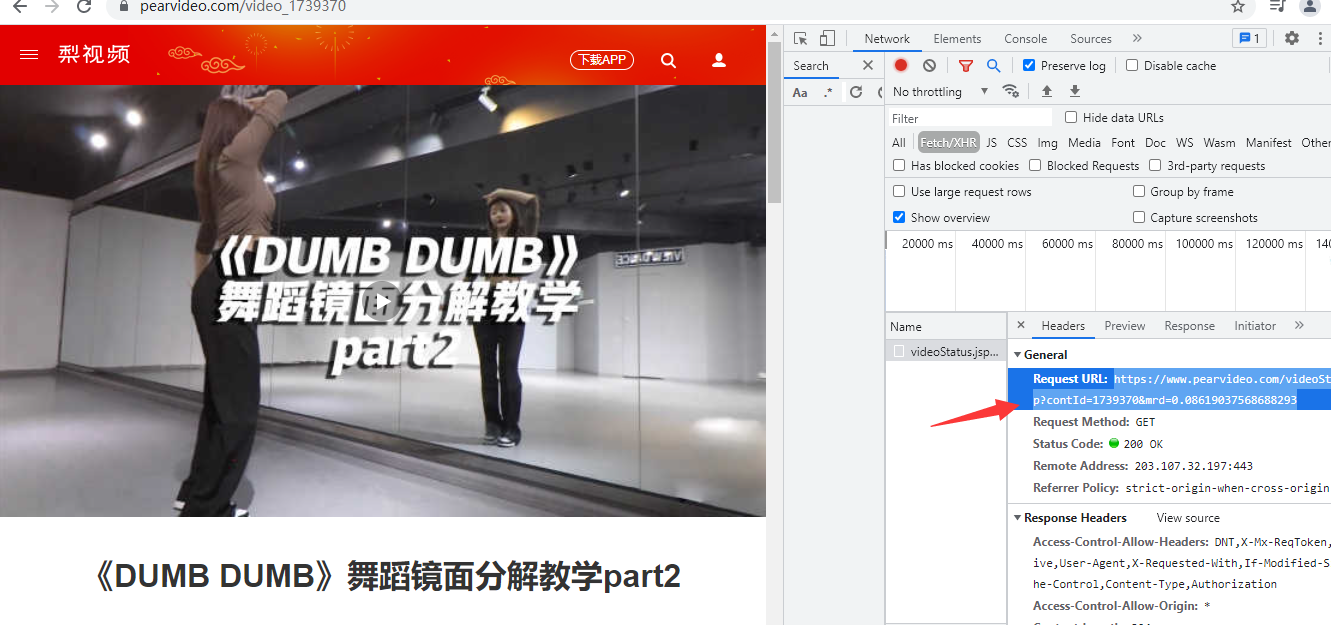
试着打开该网址

这是添加了防盗链
需要再请求头中加入referer参数
并且contld=id即可
headers={'Referer': 'https://www.pearvideo.com/video_%s'%id} # 构造防盗链加入请求头中
res1=requests.get('https://www.pearvideo.com/videoStatus.jsp' #向视频页后台发送数据的网址发送请求
,headers=headers# 加入请求头
,params={'contId':id}#在网址后加入参数 每个参数对应不同的视频
)

打印获得文本内容
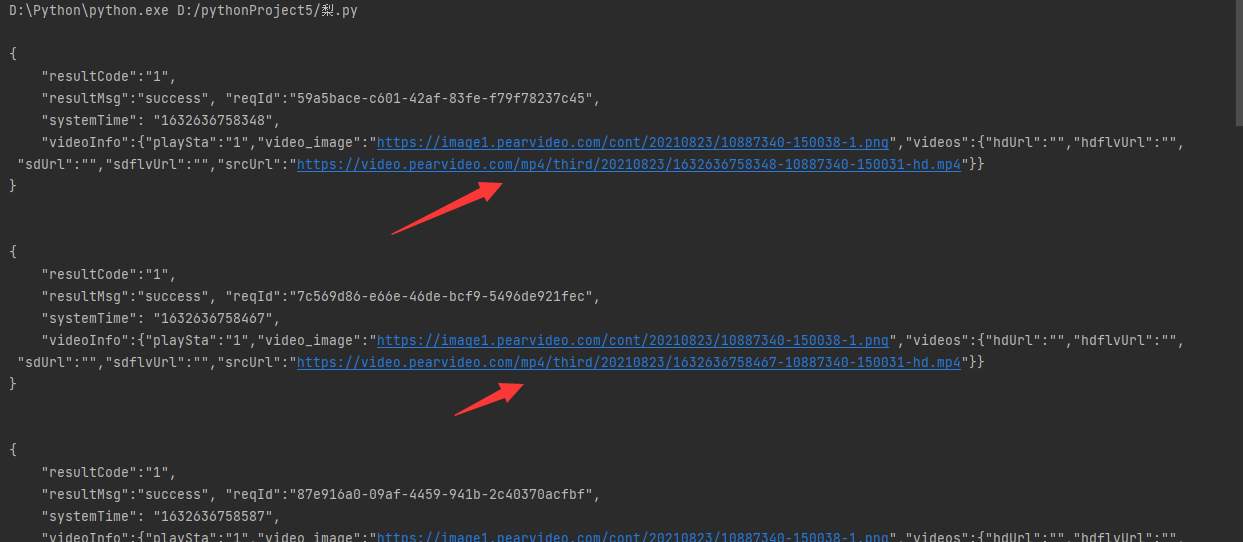
获取到srcurl中的内容
mp4_url=res1.json()['videoInfo']['videos']['srcUrl']
点开该链接发现:
将真正的视频地址链接与该链接进行对比
真正的视频链接:https://video.pearvideo.com/mp4/third/20210819/cont-1739370-10887340-130250-hd.mp4
获得的视频链接:https://video.pearvideo.com/mp4/third/20210823/1632637070451-10887340-150031-hd.mp4
差异在于

通过观察视频页请求头地址发现下面一串数字就是systemtime
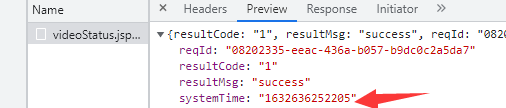
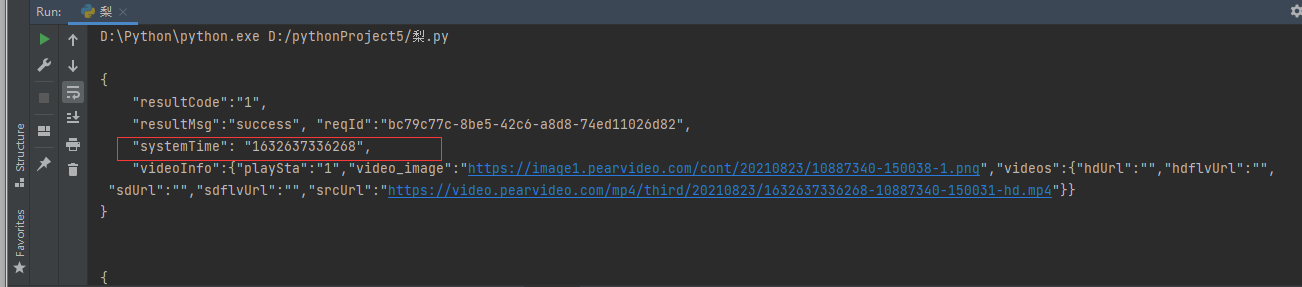
即res1.json()中的systemTime,做替换即可
real_url=mp4_url.replace(systemtime,'cont-%s'%id)
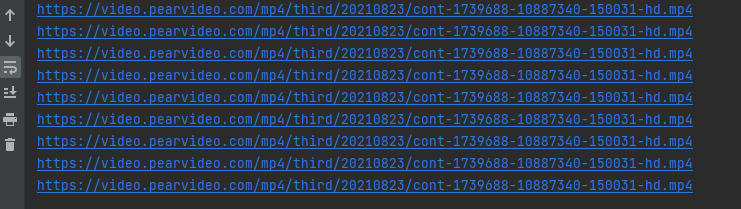
并且确实是可以打开的.
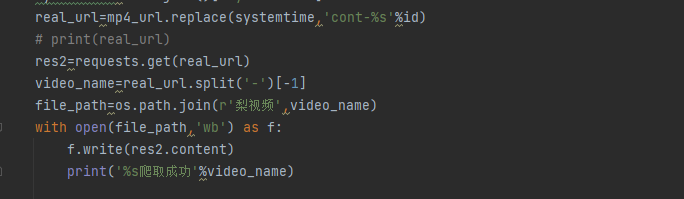
最后就朝该网页发请求,并通过os模块创建文件夹,拼接路径,写入文件
最后 添加函数 n 进行12倍数的for循环
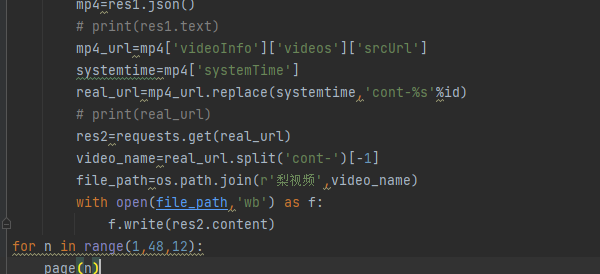
import os import requests from bs4 import BeautifulSoup if not os.path.exists(r'梨视频'): os.mkdir(r'梨视频') def page(n): res=requests.get("https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=4&start=%s"%n) # print(res.text) soup=BeautifulSoup(res.text,'lxml') href=soup.select('.categoryem') # print(href) for li in href: a_tag=li.find(name='a') # print(a_tag) href_id=a_tag.get('href') id=href_id.split('_')[-1] headers={'Referer': 'https://www.pearvideo.com/video_%s'%id} res1=requests.get('https://www.pearvideo.com/videoStatus.jsp',headers=headers,params={'contId':id}) mp4=res1.json() # print(res1.text) mp4_url=mp4['videoInfo']['videos']['srcUrl'] systemtime=mp4['systemTime'] real_url=mp4_url.replace(systemtime,'cont-%s'%id) # print(real_url) res2=requests.get(real_url) video_name=real_url.split('cont-')[-1] file_path=os.path.join(r'梨视频',video_name) with open(file_path,'wb') as f: f.write(res2.content) for n in range(1,48,12): page(n)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号