
爬虫实战与数据筛选方式
爬取农产品数据http://www.xinfadi.com.cn/priceDetail.html
import requests import time for n in range(1,5): url='http://www.xinfadi.com.cn/getPriceData.html' headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"} res=requests.post(url,headers=headers,data= {"limit":"", "current":n, "pubDateStartTime":"", "pubDateEndTime":"", "prodPcatid":"", "prodCatid":"", "prodName":""}) rep=res.json().get('list') for i in rep: name=i.get('prodName') lowprice=i.get('lowPrice') highprice=i.get('highPrice') avgprice=i.get('avgPrice') place=i.get('place') pubdate=i.get('pubDate') print(""" 蔬菜名:%s 最低价:%s 最高价:%s 均价:%s 产地:%s 上市日期:%s """%(name,lowprice,highprice,avgprice,place,pubdate)) time.sleep(1)
#在爬取数据时建议加入time.sleep()功能 缓解对方服务器压力,停顿一秒即可.
爬虫解析库之bs4模块
模块全称:Beautiful Soup 4 简称bs4
是一个可以从html或者xml文件中提取数据的python库
可以极大的节省工作时间,
模块下载: pip3 install beautifulsoup4
配套下载解析器: pip3 install lxml
# 构造一个网页数据 html_doc = """ <html> <head> <title>The Dormouse's story</title> </head> <body> <p class="title"> <b>The Dormouse's story</b>
<b>story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
"""
1.构造一个解析器对象
soup=BeautifulSoup(html_doc,'lxml')
2利用对象内置方法完成操作
获取从上往下数的第一个a/p标签
print(soup.a) print(soup.p)

获取从上往下数的第一个a/p标签中的文本内容
print(soup.a.text) print(soup.p.text)#包含内部所有内部后代文本

获取内部标签属性
print(soup.a.attrs)#以字典的形式返回所有 print(soup.a.attrs.get('href'))

可以简写成
print(soup.a.get('href'))
获取内部标签所有子标签
print(soup.p.children) res=soup.p.children for i in res: print(i)
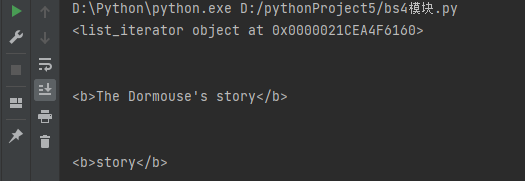
由于得到的是一个迭代器 所以需要for循环取值获取
获取内部所有元素
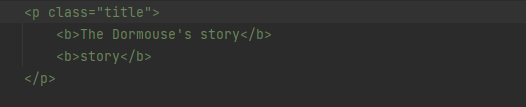
print(soup.p.contents)

获取标签的父标签
print(soup.p.parent)
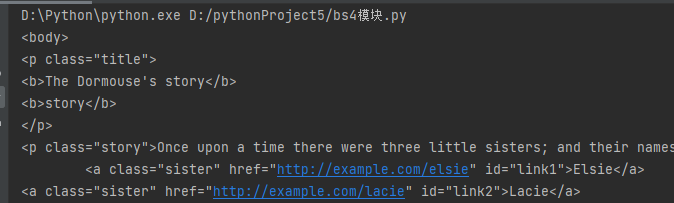
拿到的就是上一层body标签所有的内容
获取祖先标签
res=(soup.p.parents)
for i in res:
print(i)
获取到的是个迭代器,所以需要for循环
bs4核心操作
find方法:
缺点:只能找符合条件的第一个,该方法返回的是一个标签对象
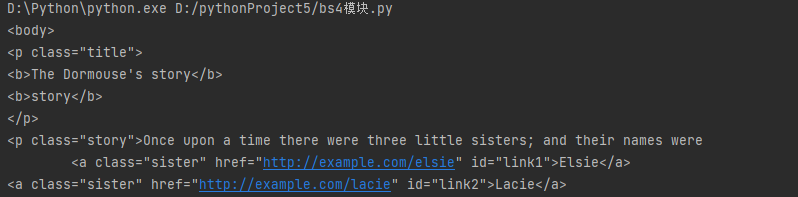
查找指定标签名的标签(默认只找一个)
print(soup.find(name='a'))

后面可以跟参数做到精确查找,id="link2"
print(soup.find(name='a',id="link3"))

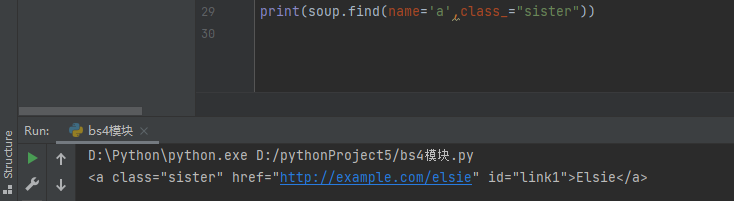
但如果需要查找class=xxx时,会导致关键字冲突报错

在class后加_即可解决
更推荐使用字典的形式书写,效果相同,避免了关键字冲突
print(soup.find(name='a',attrs={'class':'sister'}))

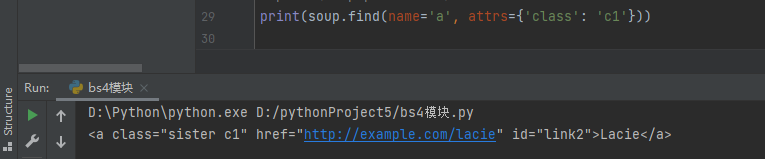
如果一个标签属于多个类,不管寻找哪个类,都能找到,属于成员运算
print(soup.find(name='a', attrs={'class': 'c1'}))
如果想要获取改标签内部文本直接再加.text即可

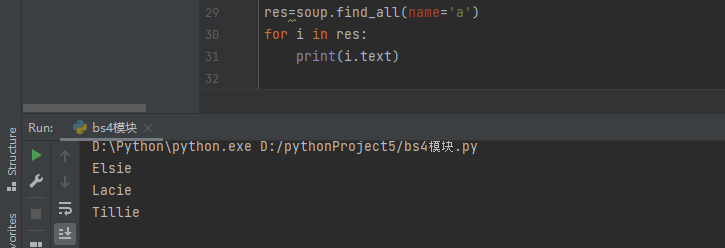
find_all方法
查找符合条件的所有方法,以列表的形式返回
其他用法与find相同

如果需要获取标签内部的文本内容,则需要for循环获取
select方法 需要使用css选择器,该方法返回的是一个列表
""" <p></p> <div> <a></a> <p> <a></a> </p> <div><p></p></div> </div> <p></p> <p></p> """
""" 1.标签选择器 直接书写标签名即可 2.id选择器 #d1 相当于写了 id='d1' 3.class选择器 .c1 相当于写了 class=c1 4.儿子选择器(大于号) 选择器可以混合使用 div>p 查找div标签内部所有的儿子p 5.后代选择器(空格) 选择器可以混合使用 div p 查找div标签内部所有的后代p """
print(soup.select('.title'))
查找含有class含有title的p标签
不要忘记返回的是个列表 如果想要获取text内容同样需要做for循环
print(soup.select('.sister span'))
查找含有sister标签内部所有后代span的标签
print(soup.select('#link1'))
查找id等于link1的标签
print(soup.select('#link1 span'))
查找id等于link1标签内部所有后代span
print(soup.select('#list-2 .element'))
查找id等于list-2内部class=element的标签
print(soup.select('#list-2')[0].select('.element'))
查找id等于list2中的标签,再找出class=element的标签
爬取红牛分公司数据http://www.redbull.com.cn/about/branch
需求:获取红牛所有分公司详细数据(名称 地址 邮箱 电话)
通过检查网页源代码得知该网页是直接加载
使用正则编写:
import re # 导入正则模块 import requests# 导入爬虫模块 url='http://www.redbull.com.cn/about/branch' # 输入网址 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}# 伪造浏览器身份 res=requests.get(url,headers=headers) # 向该网址发送get请求 com=re.findall('<h2>(.*?)</h2>',res.text) # 通过观察网页源代码,城市分公司在h2 标签内部的文本 通过正则表达式.*?获取文本 addr=re.findall("<p class='mapIco'>(.*?)</p>",res.text) # 通过观察网页源代码 具体地址都在class=mapico的p标签中的文本 通过.*?获取 e_mail=re.findall("<p class='mailIco'>(.*?)</p>",res.text)# 通过观察网页源代码 邮编都在class=mailico的p标签中的文本 通过.*?获取 phone=re.findall("<p class='telIco'>(.*?)</p>",res.text)# 通过观察网页源代码 电话都在class=tellico的p标签中的文本 通过.*?获取 rep=[] # 定义一个列表 for i in range(len(com)): # 随便获取一个列表对他的元素个数进行循环 print(""" 公司名称:%s 公司地址:%s 公司邮编:%s 公司电话:%s """%(com[i],addr[i],e_mail[i],phone[i])) # 每一个列表都是一一对应的关系,当第一个元素个数为1时就是取每个列表中的第一个元素,就是名称,地址,邮编,电话

 浙公网安备 33010602011771号
浙公网安备 33010602011771号