

简单项目爬取

也可以通过邮右键,点击查看网页源码,随便复制网页中的一段文字,在网页源码页面crtl+f黏贴这段文字, 如果搜到了就是直接加载了全部内容


2.内部通过js代码发送请求
这是现在大多数网站都是这么做的,先加载一个框架,之后再各项数据网址发送请求数据,
如b站所示网页源码仅39行 很明显,并没有获取到全部的数据
通过检查network检测内部请求,请求数据一般为json格式
爬取天气数据
1.先查看该网站是以什么方式请求数据
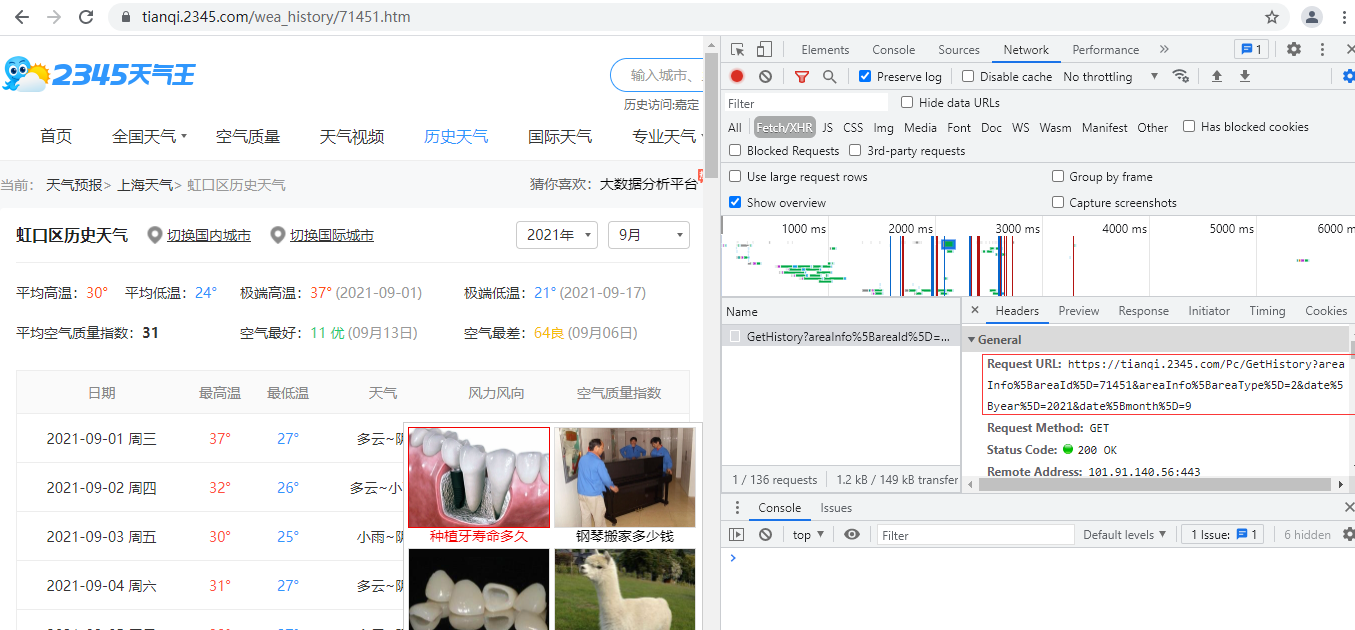
通过查找网页源代码得知该网页是通过js动态请求发送的数据的
2.得到 网址 并且发送的是get请求


https://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=71451&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=8
3.可以访问该网站获取页面中的json数据
4.通过https://www.bejson.com/该网站进行UNicode转中文
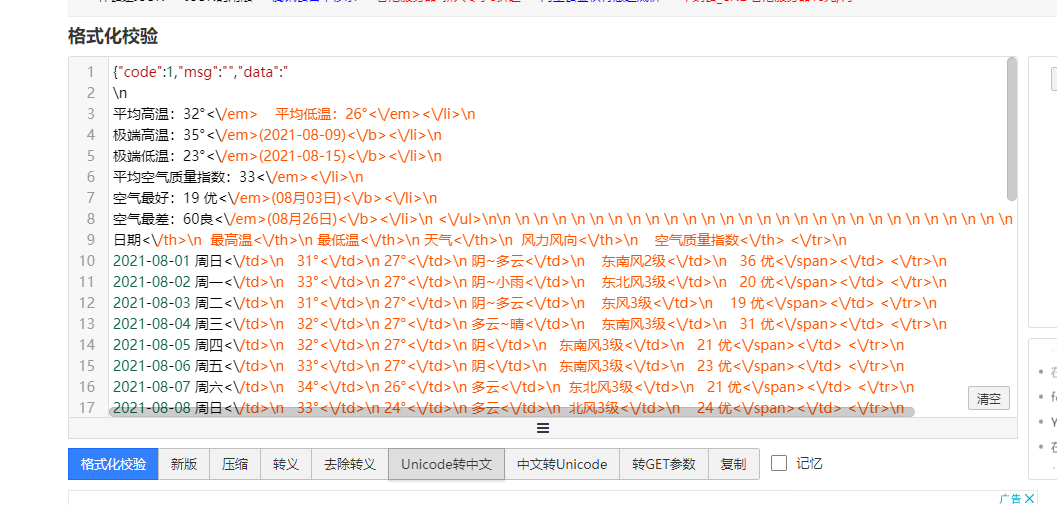
5.朝目标网站模拟浏览器请求数据
#爬取虹口区八月份天气数据 import requests #1.先检查网页是以什么形式发送的数据 res=requests.get('https://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=71451&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=8') #print(res.json())# 查看关键性数据在那个键值对中(data中) print(res.json().get('data'))
进阶操作:
------------恢复内容开始------------
也可以通过邮右键,点击查看网页源码,随便复制网页中的一段文字,在网页源码页面crtl+f黏贴这段文字, 如果搜到了就是直接加载了全部内容
2.内部通过js代码发送请求
这是现在大多数网站都是这么做的,先加载一个框架,之后再各项数据网址发送请求数据,
如b站所示网页源码仅39行 很明显,并没有获取到全部的数据
通过检查network检测内部请求,请求数据一般为json格式
爬取天气数据
1.先查看该网站是以什么方式请求数据
通过查找网页源代码得知该网页是通过js动态请求发送的数据的
2.得到 网址 并且发送的是get请求
https://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=71451&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=8
3.可以访问该网站获取页面中的json数据
4.通过https://www.bejson.com/该网站进行UNicode转中文
5.朝目标网站模拟浏览器请求数据
#爬取虹口区八月份天气数据 import requests #1.先检查网页是以什么形式发送的数据 res=requests.get('https://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=71451&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=8') #print(res.json())# 查看关键性数据在那个键值对中(data中) print(res.json().get('data'))
进阶操作:
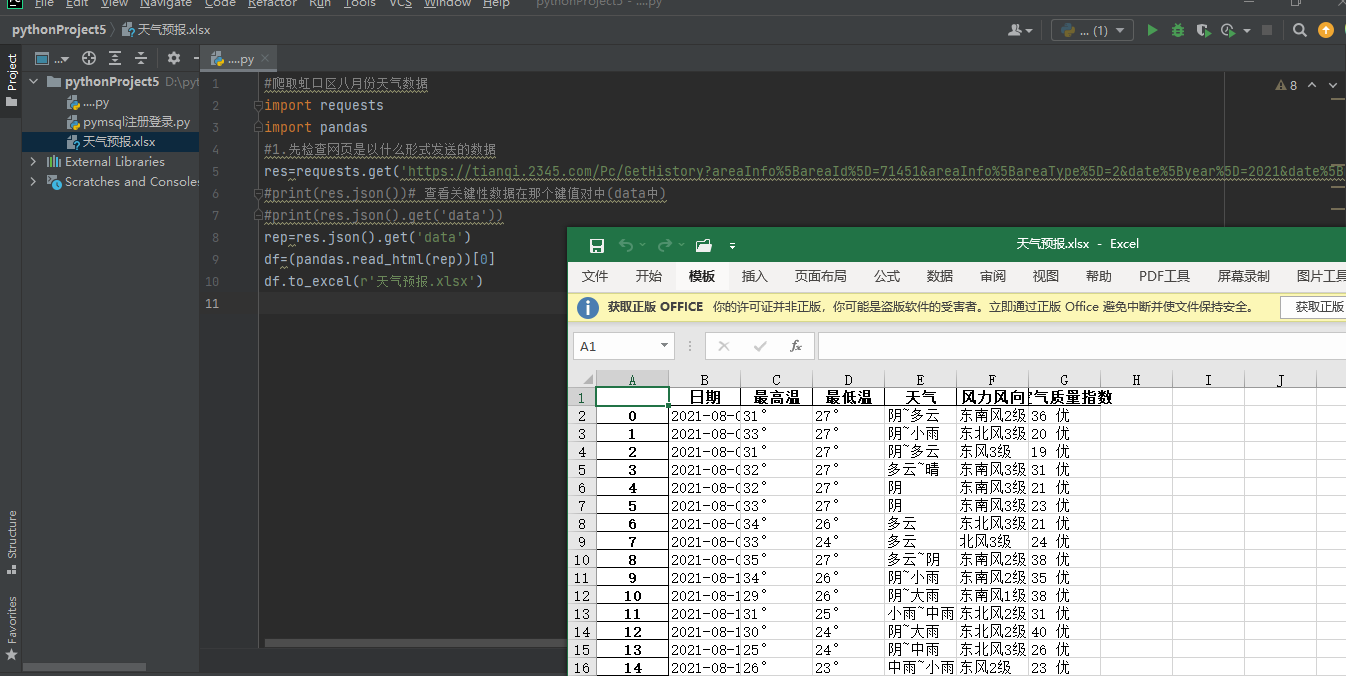
安装 pandas xlsx openpyxl模块
#爬取虹口区八月份天气数据 import requests import pandas #1.先检查网页是以什么形式发送的数据 res=requests.get('https://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=71451&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=8') #print(res.json())# 查看关键性数据在那个键值对中(data中) #print(res.json().get('data')) rep=res.json().get('data') df=(pandas.read_html(rep))[0] df.to_excel(r'天气预报.xlsx')
3.检查network可以发现每当网页发送请求时,总会出现sug并且返回四到五个文件都数据都带有sug
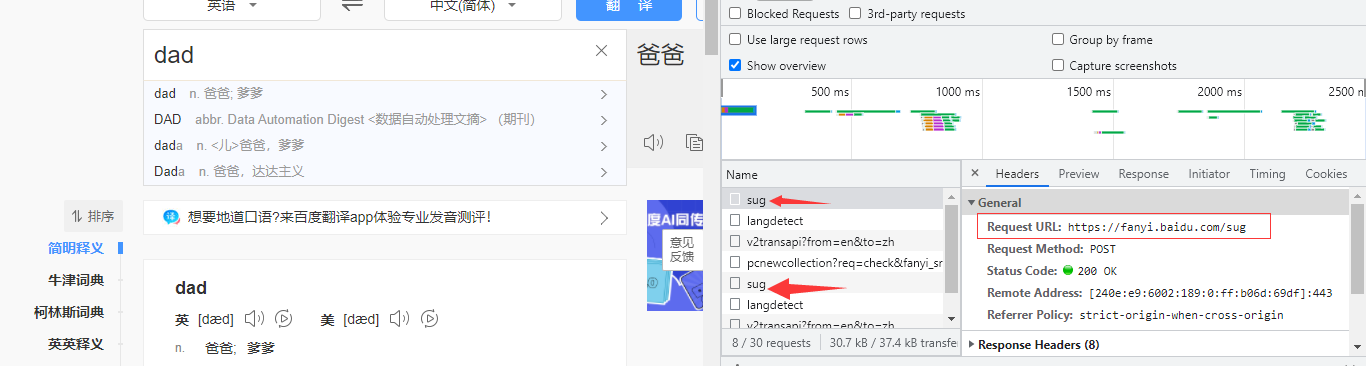
4.经分析得知 该网站每次做请求都是向https://fanyi.baidu.com/sug网址发送请求
5.写代码
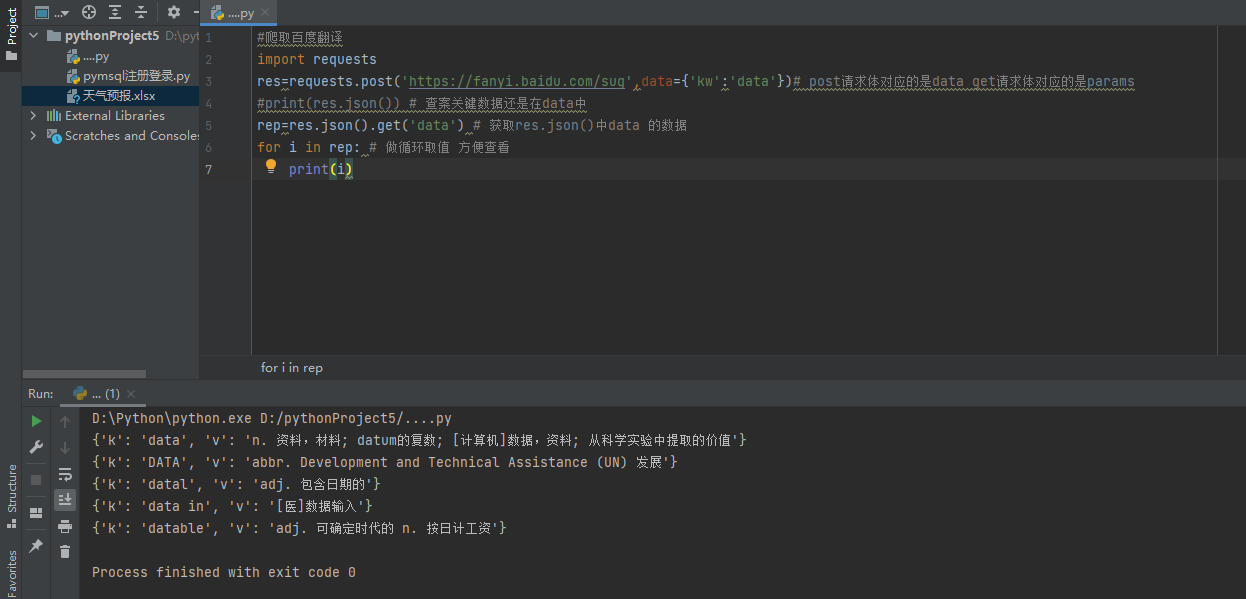
#爬取百度翻译功能 import requests res=requests.post('https://fanyi.baidu.com/sug',data={'kw':'data'})# post请求体对应的是data get请求体对应的是params #print(res.json()) # 查看关键数据还是在data中 rep=res.json().get('data') # 获取res.json()中data 的数据 for i in rep: # 做循环取值 方便查看 print(i)
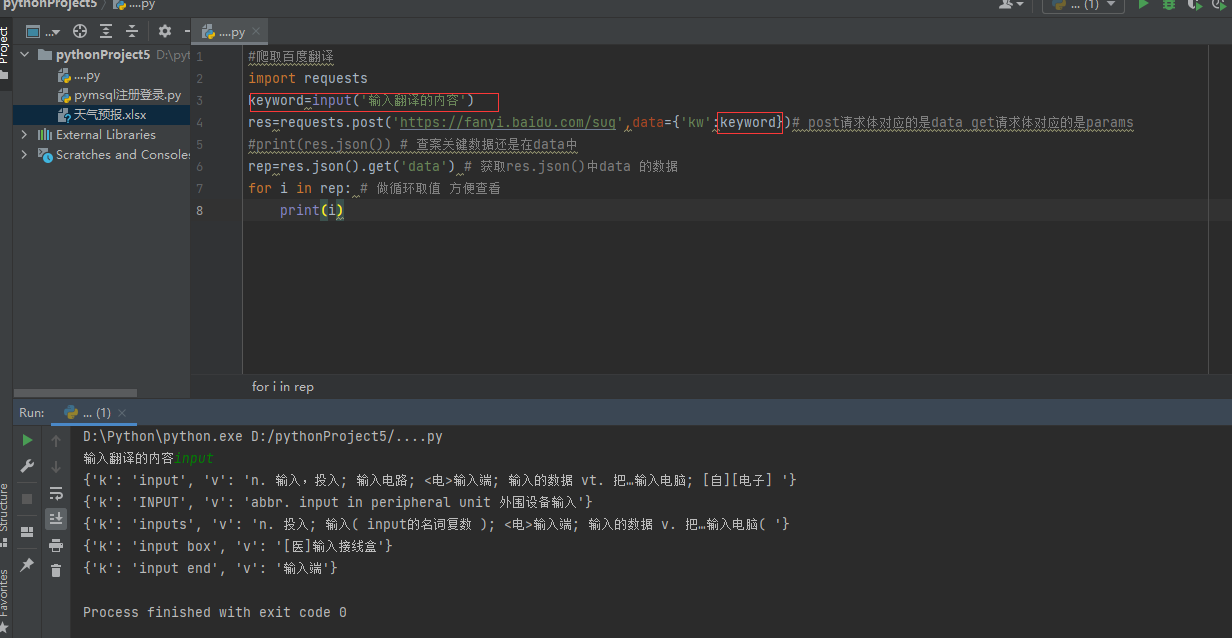
也可以做一个用户输入操作
爬取药品许可证http://scxk.nmpa.gov.cn:81/xk/
1.先判断是否数据请求方式(js代码动态请求)

2.通过network观察第一个网址不是接受请求的网址 则继续往下找也可以直接点fetch/xhr 直接寻找发送数据的筛选
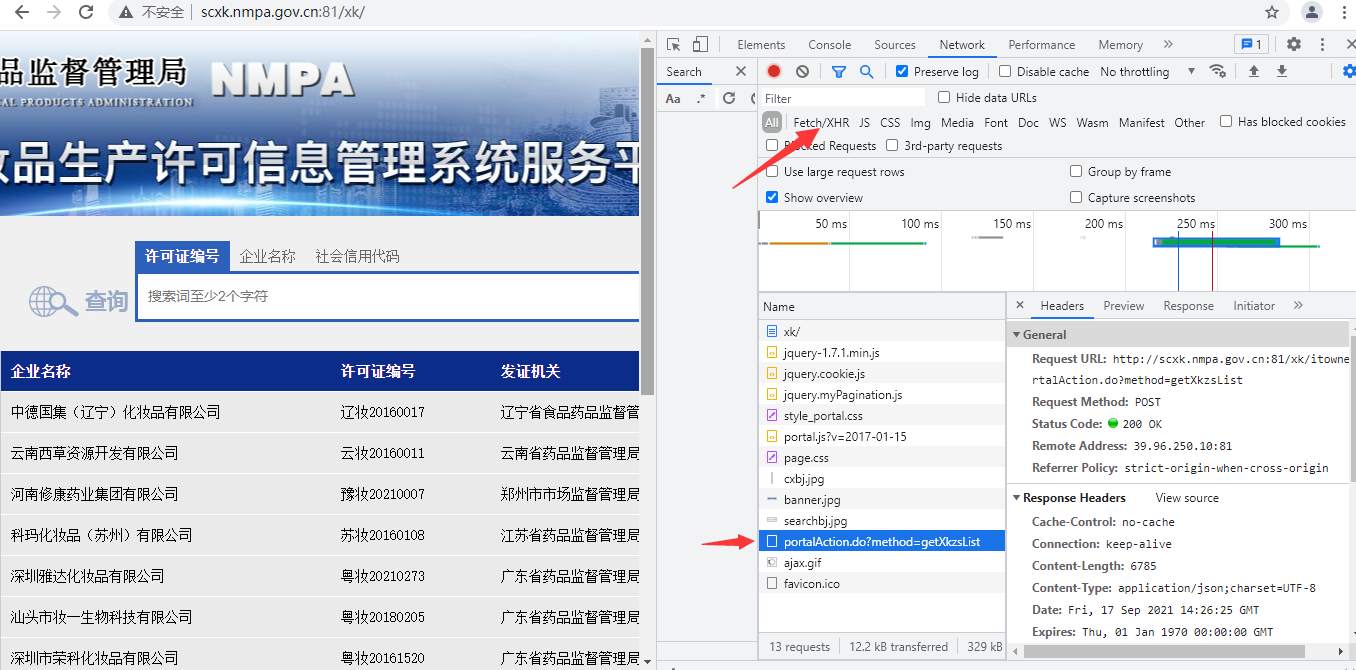
3. 观察到是在往这个网站发送post请求http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList
4.赋值response中的数据 在json校验格式化工具中 进行转换
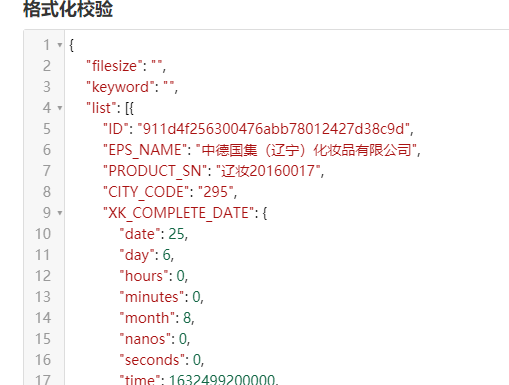
5.书写代码
import requests res=requests.post('http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList' , data={"on": "true", "page": 1, "pageSize": 15, "productName":'', "conditionType":1, "applyname":'', "applysn":'' }) #print(res.json()) # 查看关键性数据 为list 获取list rep=res.json().get('list') for i in rep: print(i)
6.观察详情页network 检查网页源发现也是动态加载的获得网址http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById
以及data=id:30015a586fd54a10bf5ff664ebe5ab35
7.通过观察之前的代码运行结果发现id与之前运行的id数据相同

8.由此得出结论:获取多个详情页数据 即 对id可以进行循环取值
9.爬取详情页地址http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById
并定义id在res中循环取id
import pymysql import requests conn = pymysql.connect( host='127.0.0.1', # ip地址 port=3306, # 端口号 user='root', # mysql 登录用户名 password='123456', # mysql 登录密码 database='t4', # 使用的database charset='utf8', # 定义字符编码 autocommit=True, # 自动确认sql命令 ) cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) url1='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList' for p in range(0,20): res=requests.post(url1, data={"on": "true", "page": p, "pageSize": 15, "productName":'', "conditionType":1, "applyname":'', "applysn":'' }) rep=res.json().get('list') for i in rep: ID=i.get('ID') url2="http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById" res2=requests.post(url2,data={'id':ID}) res3=res2.json() name=res3.get('epsName') bln=res3.get('BUSINESS_LICENSE_NUMBER') sql = 'insert into com_info(公司名字,征信代码) values(%s,%s)' cursor.execute(sql, (name,bln))
思路:
1.先获取了主页中数据,观察data中的数据发现page是控制页数的 可以做一个循环page 2再获取每个公司详情后发现 请求地址每个公司都相同 唯独id 不同 3.取到第一个结果中的所有id做循环 将id 为第二个中的id data={id:'id'} 这样就可以获取到所有公司的详情 4.导入pymysql模块 将数据导入mysql数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号