
关于机器学习课程的内容整理
关于机器学习的内容整理
机器学习的过程
- 获取数据,并从数据中提取有用的信息
- 收集数据(收集各种橘子样本,每个样本应包含橘子的多种属性,如大小,颜色,产地等)
- 保留有用的信息(在橘子多种属性中保留对甜度有用的属性)
- 创建模型并对模型进行训练
- 选择合适的机器学习算法(选择学习方法和学习技巧)
- 让计算机使用选择的算法从获取的数据中学习规律(开始进行学习)
- 模型评价和模型优化
- 学习到的规律是否总时好用的?(模型评价)
- 不好用重新优化并训练模型使之更好用(模型优化)
收集数据 -> 处理数据 -> 构建模型 -> 训练模型 -> 评估模型
机器学习的种类
是否在人类的监督下训练(监督学习,无监督学习,半监督学习,强化学习)
- 监督学习
训练数据包含了对应问题的答案,即标签。通常的分类和回归任务可以用监督学习来完成 - 无监督学习
训练数据是没有标签的,经典的无监督学习任务是聚类。如根据博客访问者的信息,使用聚类算法对相似访客进行分组。 - 半监督学习
通常是大量的无标签数据和一小部分有标签的数据的混合数据 - 强化学习
智能体(学习系统)通过在观察环境后做出选择和执行操作,获得奖励。根据奖励的好坏判断行动
是否动态渐进学习(在线学习 vs 离线学习)
-
离线学习
- 机器不能持续的学习,机器通常需要很多时间和资源进行线下训练,等模型发布之后就不再训练了只是应用而不再学习新的。
- 使用离线学习的系统来学习新数据,必须使用所有的数据对新系统进行训练,然后把老的系统换成新的。
- 优点:学习和部署分开,有助于在计算资源较低的设备上应用机器学习成果。比如手机端的语音识别系统(Siri,小艺,小爱)。
- 缺点:每次都使用完整的数据集进行训练会消耗大量的时间和计算资源,无法适应快速变化的数据(例如:股票预测系统)和进行低成本应用。
-
在线学习
- 自动接受连续数据流,学习步骤比较快而且成本很低,可以动态学习刚刚到达的数据。
- 多用于连续的数据(比如股票价格)
搭建简单的机器学习框架
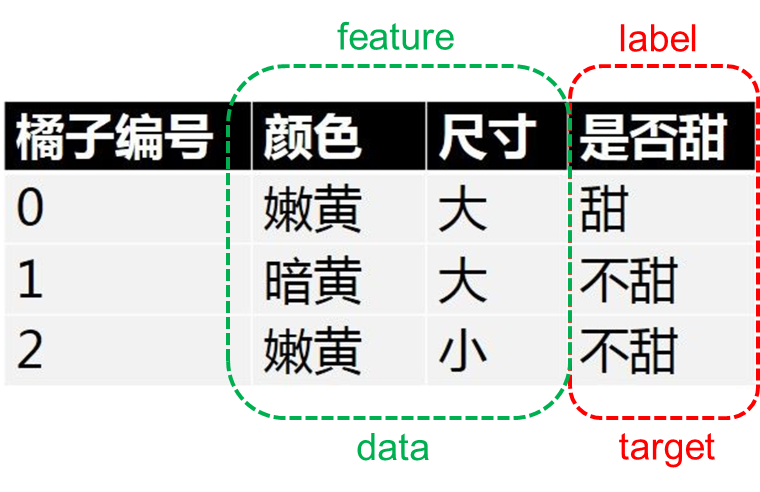
数据
- 数据的总体叫做数据集(datasets)
- 每行数据成为样本 (sample)
- 除了最后一列, 每一列称为特征(feature),只包含特征的数据叫做特征数据(data)——数据的样子
- 最后一列称为标记(label),只包含标记的数据叫目标数据(target)——数据的结果
- 以每个数据特征作为一个数据维度,构建的空间叫做数据空间。数据空间中的每个点表示一个数据样本
- 非结构化的数据类型:图像数据、文本数据、语音数据
![image]()
简单机器学习的步骤
1. 读取数据
import pandas as pd
iris = pd.read_csv('数据文件地址')
2.划分特征数据和目标数据
X = iris.drop('species',axis=1) //其中speies要根据实例中的目标数据标签(label)
y = iris.species
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
3.构建模型
from sklearn.linear_model import LogisticRegression //这里的例子为使用了 LogisticRegression 模型
log_reg = LogisticRegression(random_state=42)
4.训练模型
log_reg.fit(X_train, y_train)
5.测试模型
log_reg.score(X_test,y_test)
数据预处理部分
数据预处理包括:
- 数据的读取与分析
- 数据清洗(处理缺失值、异常值、重复数据)
- 数据转换(标准化、编码、向量化)
- 特征工程(特征提取、组合、选择)
- 数据分割(训练集、验证集、测试集)
- 数据平衡(处理类别不平衡)
- 数据增强(可选)
- 数据保存
数据的读取
1. pandas的read命令
- pd.read_csv():适用CSV文件(Comma-Separated Values,逗号分隔文件)
- pd.read_excel():适用Excel 文件(.xls 或 .xlsx)
- pd.read_json():适用JSON文件(JavaScript Object Notation)
- pd.read_sql():SQL 数据库
- pd.read_html():适用HTML 网页表格。
2. 观察读入的数据
观察文本式数据
house.info()
// 功能:输出数据集的基本信息,包括列名、非空值数量、数据类型及内存占用情况。
// 用途:快速检查数据完整性(如缺失值比例)及列类型分布,便于后续清洗或转换操作。可辅助判断缺失值处理优先级
housing["ocean_proximity"].value_counts()
// 功能:统计分类列 ocean_proximity 中每个类别的样本数量。
// 用途:分析类别分布均衡性,常用于判断是否需要处理类别不平衡问题(如过采样或合并低频类别)。
housing.describe(include=['object'])
// 功能:生成非数值型列(如字符串或分类变量)的统计摘要,包括唯一值数量、高频值及其出现次数24。具体的统计摘要根据include的值
// 用途:验证分类字段的合理性(如异常类别名)或指导编码策略(如独热编码或标签编码)。统计指标可用于筛选或转换输入特征
观察可视化数据
分析数据——相似性分析
相似性计算通过相似性计算从数值角度分析特征之间的关系。常用的方法包括相关性分析、距离度量和相似性度量。
-
相关性分析:用于分析两特征之间的线性关系。常用方法包括:皮尔逊相关系数、斯皮尔曼相关系数和肯德尔相关系数。
-
皮尔逊相关系数(Pearson Correlation)
- 衡量两个变量之间的线性相关性,取值范围为 [-1, 1]。
- 1 表示完全正相关,-1 表示完全负相关,0 表示无线性相关性。
correlation_matrix = data.corr(method='pearson')
-
斯皮尔曼相关系数(Spearman Correlation)
- 衡量两个变量之间的单调关系,适用于非线性但单调的数据。
correlation_matrix = data.corr(method='spearman')
- 衡量两个变量之间的单调关系,适用于非线性但单调的数据。
-
肯德尔相关系数(Kendall Correlation)
- 衡量两个变量的秩序相关性,适用于小数据集或存在较多重复值的情况。
correlation_matrix = data.corr(method='kendall')
- 衡量两个变量的秩序相关性,适用于小数据集或存在较多重复值的情况。
-
-
距离度量: 距离度量用于衡量两个特征之间的差异。常用的方法包括欧氏距离、曼哈顿距离和余弦相似度。
-
相似性度量: 相似性度量用于衡量两个特征之间的相似性。常用的方法包括Jaccard 相似系数和汉明距离。
数据的基本操作方法
-
查询:信息查询、统计查询(数值、类别)
1. 标签查询 df.loc
功能:基于行/列标签进行精确或范围查询,支持条件筛选和批量检索# 单个值查询 df.loc['row_label', 'column_label'] # 返回指定行列的标量值:ml-citation{ref="1,3" data="citationList"} # 批量查询 df.loc[['row1', 'row2'], ['colA', 'colB']] # 返回多行多列组成的 DataFrame:ml-citation{ref="2,4" data="citationList"} # 区间查询 df.loc['row_start':'row_end', 'col_start':'col_end'] # 范围查询:ml-citation{ref="1,2" data="citationList"} # 条件筛选 df.loc[df['column'] > 10, :] # 筛选某列满足条件的行:ml-citation{ref="1,2" data="citationList"}2. 位置查询
功能:基于行/列的数字位置索引查询,适用于非固定标签的场景df.iloc[0, 1] # 获取第1行第2列的值 df.iloc[1:5, [0, 2]] # 获取2-5行,第1和第3列的数据:ml-citation{ref="1,5" data="citationList"}3. 条件查询:布尔索引
功能:通过逻辑表达式筛选数据,支持组合条件# 单条件筛选 df[df['column'] == 'value'] # 筛选等于某值的行:ml-citation{ref="5" data="citationList"} # 多条件组合 df[(df['colA'] > 5) & (df['colB'].isin(['X', 'Y']))] # 多条件交集:ml-citation{ref="5,6" data="citationList"}4. 表达式查询:df.query
功能:通过字符串表达式简化复杂条件查询df.query('colA > colB * 2') # 比较两列关系 df.query('colC in ["X", "Y"]') # 筛选列值在列表中的行:ml-citation{ref="5,6" data="citationList"} -
切片——iloc/loc
1. 标签切片——左闭右闭df.loc['row_start':'row_end', 'col_start':'col_end'] # 行列标签范围切片:ml-citation{ref="1,2" data="citationList"}2. 位置切片——左闭右开
df.iloc[1:3, 2:4] # 获取第2-3行、第3-4列的数据:ml-citation{ref="2,3" data="citationList"}3. 隐式索引(直接切片)
仅适用于行切片,默认使用隐式位置索引df[1:3] # 等价于 df.iloc[1:3]:ml-citation{ref="4" data="citationList"} -
索引
1. 单值索引df.iloc[0, 1]2. 多值索引
df.loc[['row1', 'row2'], ['colA', 'colB']] # 多标签组合 df.iloc[[0, 2], [1, 3]] # 多位置组合3. 条件筛选
df.loc[df['Age'] > 30, ['Name', 'Salary']] # 筛选年龄>30的姓名和薪资 -
行列转换
1. 转置(行列互换)df_transposed = df.T # 快速转置 df_transposed = df.transpose() # 等价方法2. 宽表变长表——melt
pd.melt(df, id_vars=['ID'], value_vars=['Value1', 'Value2']) # 指定保留列和转换列3. 长表变宽表——pivot
df_wide = df.pivot(index='ID', columns='Category', values='Value') # 按类别展开为多列4. 层次化索引转换——stack和unstack
df_stacked = df.stack() # 列转行,生成多层索引 df_unstacked = df_stacked.unstack() # 行转列,恢复原始结构
数据的清洗方法
-
处理缺失值:
1. 删除缺失值:
- labels:要删除的行或列的标签。
- axis:指定删除行(axis=0,默认)或列(axis=1)。
- index:指定要删除的行(替代 labels 和 axis=0)。
- columns:指定要删除的列(替代 labels 和 axis=1)。
- 删除包含缺失值的行:
df_dropped_na_rows = df.drop(index=df[df.isnull().any(axis=1)].index)
- 删除包含缺失值的列:
df_dropped_cols = df.dropna(axis=1)
- 删除指定行
df_dropped_row = df.drop(index=[n])
- 删除指定列
df_dropped_col = df.drop(columns=['B'])
2. 填充缺失值:
- 用均值填充数值型缺失值:
df_filled_mean = df.fillna(df.mean())
- 用中位数填充数值型缺失值:
df_filled_median = df.fillna(df.median())
- 用众数填充类别型缺失值:
df_filled_mode = df.fillna(df.mode().iloc[0])
- 用固定值填充缺失值:
df_filled_fixed = df.fillna(0) # 用0填充
- 用插值法填充缺失值:
# 用线性插值填充缺失值 df_interpolated = df.interpolate()
使用Sklearn用法:
from sklearn.impute import SimpleImputer imputer = SimpleImputer(strategy="median") imputer.fit(housing[['total_bedrooms']]) housing['total_bedrooms'] = imputer.transform(housing[['total_bedrooms']])
3. 标记缺失值
# 添加新列标记缺失值的位置 df['A_missing'] = df['A'].isna() df['B_missing'] = df['B'].isna() df['C_missing'] = df['C'].isna() print("标记缺失值后的数据:\n", df) -
处理重复值
1.数据的删除
1.1 删除完全重复的行:
# 删除完全重复的行 df_deduplicated = df.drop_duplicates()
1.2 删除特定列删除重复行
# 基于列A删除重复行 df_deduplicated_col = df.drop_duplicates(subset=['A'])
2.对重复数据的聚合和标记
2.1 对重复数据进行聚合操作
# 对重复数据进行聚合操作(如求和) df_aggregated = df.groupby('A').sum().reset_index()
2.2 标记新列标记重复数据的位置
# 添加新列标记重复数据的位置 df['is_duplicate'] = df.duplicated() -
处理异常值
处理异常值的步骤:
1. 检测异常值:使用统计方法(Z-score、IQR)或可视化方法(箱线图、散点图)。
2. 处理异常值:
- 删除异常值。
- 替换异常值(均值、中位数、众数)。
- 转换异常值(对数转换、分箱)。
- 使用模型处理(Isolation Forest、K-Means)。
数据的转换
调整数据类型和文本格式
1.1 数值型数据转换
数值型数据通常需要转换为浮点数或整数。
df['age'] = df['age'].astype(int)
1.2 类别型数据转换
类别型数据通常需要转换为数值型编码,常用的方法包括 LabelEncoder 和 OneHotEncoder。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 创建示例数据
data = {'color': ['red', 'blue', 'green', 'blue', 'red']}
df = pd.DataFrame(data)
# 使用 LabelEncoder 进行编码
label_encoder = LabelEncoder()
df['color_encoded'] = label_encoder.fit_transform(df['color'])
//fit_transform 中fit学习输入的参数,transform使用fit阶段学习到的参数,将输入数据转换为新的形式
// 对于 LabelEncoder,它会将类别标签转换为整数。
# 使用 OneHotEncoder 进行编码
one_hot_encoder = OneHotEncoder(sparse=False)
color_encoded = one_hot_encoder.fit_transform(df[['color']])
// 对于 StandardScaler,它会将数据标准化(减去均值并除以标准差)
# 将编码结果转换为 DataFrame
color_encoded_df = pd.DataFrame(color_encoded, columns=one_hot_encoder.get_feature_names_out(['color']))
# 合并到原 DataFrame
df = pd.concat([df, color_encoded_df], axis=1)
print(df)
2.1 调整文本格式——文本清洗
文本清洗通常包括去除标点符号、转换为小写、去除停用词等。
import re
import nltk
from nltk.corpus import stopwords
# 下载停用词
nltk.download('stopwords')
# 创建示例文本
text = "This is a sample text, showing off the stop words filtration."
# 转换为小写
text = text.lower()
# 去除标点符号
text = re.sub(r'[^\w\s]', '', text)
# 去除停用词
stop_words = set(stopwords.words('english'))
words = text.split()
filtered_text = [word for word in words if word not in stop_words]
print("Original Text:", text)
print("Filtered Text:", filtered_text)
2.2 文本向量化
文本向量化是将文本转换为数值型向量的过程,常用的方法包括 CountVectorizer 和 TfidfVectorizer。
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# 创建示例文本
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
# 使用 CountVectorizer 进行向量化
count_vectorizer = CountVectorizer()
X_count = count_vectorizer.fit_transform(corpus)
# 使用 TfidfVectorizer 进行向量化
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(corpus)
print("Count Vectorizer:")
print(X_count.toarray())
print("\nTfidf Vectorizer:")
print(X_tfidf.toarray())
输出:
Count Vectorizer:
[[0 1 1 1 0 0 1 0 1]
[0 2 0 1 0 1 1 0 1]
[1 0 0 1 1 0 1 1 1]
[0 1 1 1 0 0 1 0 1]]
Tfidf Vectorizer:
[[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]
[0. 0.6876236 0. 0.28108867 0. 0.53864762
0.28108867 0. 0.28108867]
[0.51184851 0. 0. 0.26710379 0.51184851 0.
0.26710379 0.51184851 0.26710379]
[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]]
转换器和估计器
- 转换器:转换器是用于数据预处理的组件,负责将输入数据转换为适合模型训练的格式。转换器通常实现以下两个方法:
- fit():从数据中学习参数(如均值、标准差、类别编码等)。
- transform():使用学习到的参数对数据进行转换。
from sklearn.preprocessing import StandardScaler
# 示例数据
data = [[0, 1], [2, 3], [4, 5]]
# 创建转换器
scaler = StandardScaler()
// StandardScaler:标准化数据。
// MinMaxScaler:归一化数据。
// OneHotEncoder:对类别型数据进行独热编码。
// PCA:主成分分析,用于降维。
# 学习参数(计算均值和标准差),获得参数
scaler.fit(data)
# 转换数据
transformed_data = scaler.transform(data)
print("Transformed Data:")
print(transformed_data)
- 估计器:估计器是用于模型训练的组件,负责从数据中学习模型的参数。估计器通常实现以下两个方法:
- fit():从训练数据中学习模型参数。
- predict():使用学习到的参数对新数据进行预测。
from sklearn.linear_model import LinearRegression
# 示例数据
X = [[1], [2], [3], [4]]
y = [2, 4, 6, 8]
# 创建估计器
model = LinearRegression()
// LinearRegression:线性回归。
// LogisticRegression:逻辑回归。
// RandomForestClassifier:随机森林分类器。
// KMeans:K-Means 聚类。
# 训练模型
model.fit(X_train,y_train) // 有监督学习
model.fit(X_train) //无监督学习
# 预测新数据
predictions = model.predict([[5]])
print("Predictions:", predictions)
- 一致性原则(Consistency Principle):一致性原则是 Scikit-learn 的设计哲学,确保所有转换器和估计器遵循统一的接口和行为规范。
特征工程
特征工程的主要步骤包括:
- 特征提取:从原始数据中提取有用信息。
- 特征转换:将特征转换为适合模型的形式,主要用标准化、归一化和类别型数据编码
- 特征组合:通过组合现有特征生成新特征。
- 特征选择:选择对模型最有用的特征,分为给予统计方法和基于模型
- 特征降维:减少特征数量,保留重要信息,分为主成分分析(PCA)和线性判别分析(LDA)
数据集划分
通常会把数据集划分成训练集和测试集(训练集和测试集都要包含全部题型)
常见方法包括:
-
简单划分:将数据集按固定比例划分为训练集和测试集,使用 train_test_split 按比例划分。
# 划分数据集(80% 训练集,20% 测试集) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) -
K 折交叉验证:将数据集划分为 K 个子集,依次使用其中一个子集作为验证集,其余作为训练集,使用 KFold 或 cross_val_score 进行 K 折划分。
-
分层划分:在分类任务中,确保训练集和测试集中各类别的比例与原始数据集一致,使用 StratifiedKFold 或 train_test_split 保持类别比例。
# 分层划分数据集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
`
# 创建 StratifiedKFold 对象(K=5)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 遍历每一折
for train_index, test_index in skf.split(X, y):
X_train, X_test = [X[i] for i in train_index], [X[i] for i in test_index]
y_train, y_test = [y[i] for i in train_index], [y[i] for i in test_index]
-
时间序列划分:对于时间序列数据,按时间顺序划分数据集,使用 TimeSeriesSplit 按时间顺序划分。
-
留出法:将数据集划分为训练集、验证集和测试集。使用 train_test_split 划分训练集、验证集和测试集。
# 第一次划分:训练集 + 临时测试集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.4, random_state=42)
# 第二次划分:验证集 + 测试集
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号