Elasticsearch分布式文档存储
前言
该篇笔记主要记录在Elasticsearch中文件是如何分布到集群的,又是如何从集群中获取的。(官方原话: 不必了解这么深入也无妨。个人也只是简单了解一下)
文档如何路由到分片中?
当我们创建一个新的文档时,文档将会存储到一个主分片中,但是Elasticsearch是如何决定将这个文档存储在哪一个分片的呢?这涉及到Elasticsearch内部的一个hash:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
主副分片的交互?
这里借用官方的图,这个集群有3个节点,2个主分片,4个副分片。我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上,比如对于0分片文档的更新操作发送到了node1上,node1将会根据id获取到P0的位置,将请求转发到node3,node3处理之后,将会将操作同步到所有的副分片上,来保证主副分片的数据一致性。
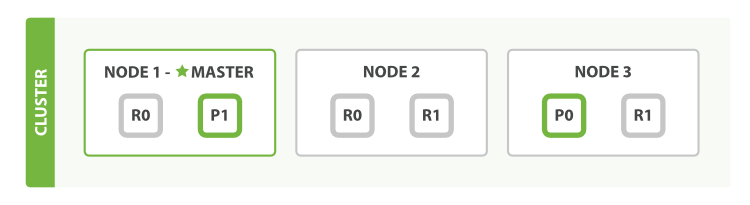
1:新建文档时,会通过哈希值来决定将该文档存储到哪个主分片上;随后会将该操作同步到该主分片的所有副本分片上。
2:更新删除文档时,根据文档ID找到文档所在的主分片,并进行操作;随后会将该操作同步到该主分片的所有副本分片上。
3:获取文档时,每次都会从主分片和副分片中选择分片来组合成一个索引,以供搜索,而且每次搜索请求不一样;这样当并发搜索很多时,就可以把压力分散在多个节点上,做到负载均衡。
4:当集群中某个节点宕机,该节点上所有分片中的数据全部丢失,丢失的主分片在其他节点上的副分片就会自动变成主分片。
注意
副分片可以提高搜索性能,提高并发吞吐量,提高数据安全性容错性。但是副分片不宜过多,因为主副分片之间的数据同步也是一个不容小觑的消耗。
在试图执行一个_写_操作之前,主分片都会要求 必须要有 规定数量(quorum)(或者换种说法,也即必须要有大多数)的分片副本处于活跃可用状态,才会去执行_写_操作(其中分片副本可以是主分片或者副本分片)。这是为了避免在发生网络分区故障(network partition)的时候进行_写_操作,进而导致数据不一致。虽然我们可以通过consistency参数来强制要求更新,但是不推荐。
#规定数量
int( (primary + number_of_replicas) / 2 ) + 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号