
学习笔记【第六章】
Part.A 小结&感悟
与上一章相似的是,本章也涉及到了许许多多的概念,理解起来确实有些让人头大。
在存储结构上面,学习了邻接矩阵&邻接表的使用,在此不做过多赘述。
另一方面是两个遍历算法中先理解并使用的深度优先遍历【DFS】,其实就是暴力把所有的路径都搜索出来,其本质在于每次搜索完成后的回溯,保存这次的位置,深入搜索,都搜索完了便回溯回来,搜下一个位置,直到把所有最深位置都搜一遍;然后再到广度优先搜索【BFS】,又结合到了队列的一部分知识。
此处参考了网上的一些资料,如下图;
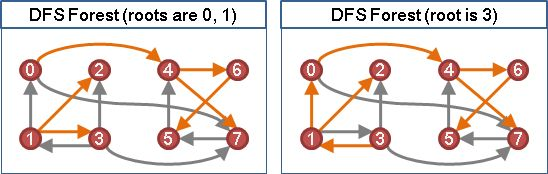
另外在学习过程中,附设访问标志(为了区别顶点是否被访问,附设访问标志数组visited[n],其初值为“false”,一旦某个顶点被访问,则其相应的置被赋为“true”)给了我一些启迪,我的理解是,在程序中对于一个对象设置的参数(可以是多个)构成了这个对象,会使整个程序整合度更高,
……好像表达的不太清楚,好吧,但是我确实非常中意这种程序的风格,于是参考了老师之前发过的有关程序编写标准化的文章,当时读只觉得都是很简单很常识性的东西,但是又细细阅读后觉得养成一个好的变成习惯也是非常重要的一件事,并且要在平时的编程中多注重一些细节。
Part B 反思&计划
这章值得一提的一道有趣编程题目“拯救007”,主要考察的就是上述的遍历算法
放一个参考程序在这里 https://blog.csdn.net/chy89224/article/details/60973087
而这位作者大大之所以厉害,有一个很重要的特点就是他对这道题的理解,同时这篇的画风让我又颇感新奇,
对于这两章所学习的数据结构,都可以借助作图或者构造模型的方式很好的解决。
由于一些原因这周没有跟上学习进度,PTA的题目还没有完成,这是我应该反思的地方,也是我下一步要调整的地方,忙过这段时间,还是应该把重心放在学习上,越来越明白这个道理……
还需努力。

