【机器学习基础】半监督学习简介
前面说了一部分有监督学习的有关算法,本节主要对半监督学习做一个简单的介绍,当然,有监督学习还有很多其他的算法,后面会不断完善和补充。
半监督学习简介
0.前言
这里半监督学习的内容只做一些初步的介绍,理解半监督学习是如何进行学习的,主要叙述原理,看一下半监督学习是如何工作的,不针对具体算法进行深究,到了实战部分涉及到会进一步学习。
前面的有监督学习中,数据都是带有标签的数据。因此,半监督学习就是一部分数据有标签,一部分数据没有标签,而通常情况下,无标签的数据数量远远大于有标签的数据。
为了后面能够更好地描述,这里先给出对数据的描述:

有标签数据有R个,无标签数据有U个,那么上面就分别表示有标签数据和无标签数据。
那么为什么要做无监督学习呢?一是因为在真实世界中,往往有标签的数据收集很困难;另一个原因就是我们人类的学习通常也是一种无监督学习的方式。
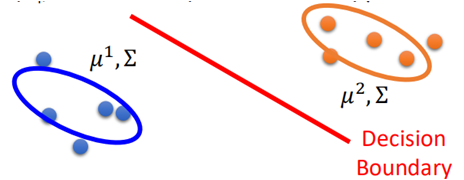
无监督学习为什么会有用呢?来看下面的图片:

假设有一只猫一只狗,对其进行分类,我们会把分界线画成中间那条竖线,而当加上unlabelled data之后:这些unlabelled data可能会影响我们的决定,会把分界线划分成斜着的这条线。
那么这样划分究竟有没有用呢?比如猫下面那一个点有可能是下面这样的一个数据:

这一张看样子也有点像猫,因为其背景与猫的背景相似,因此,有可能会被划分为猫。
半监督通常是要基于一些假设,然后进行建模的,那么半监督学习的效果好不好,就是假设的是否合理。下面介绍几种常见的半监督学习中的假设。
1.生成模型中的半监督学习
在前面《概率生成模型》一节中介绍了,在监督学习中,概率生成模型用来分类的方法:
假设数据集服从高斯分布,然后利用最大似然估计估算出样本分布的参数,然后对未知样本进行分类:
那么在半监督学习中,我们不仅有带有标签的数据,还会有大量的没有标签的数据,如图所示:
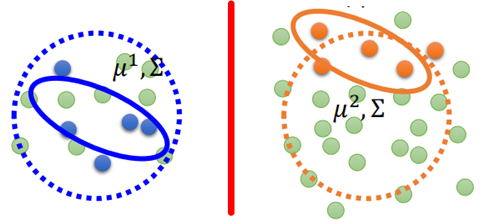
图中绿色的点是无标签数据,那么这些无标签的数据就会迫使原来的分类边界进行移动,变成竖线。
那么无监督学习中具体是如何实现呢?步骤如下:
(1)初始化一组参数μ1、μ2、Σ、P(C1)、P(C2);这组参数可以从labeled data计算得来;
(2)然后利用这组参数对无标签数据进行进行分类;
(3)根据对无标签数据的分类的结果,更新参数μ1、μ2、Σ、P(C1)、P(C2),具体更新方法如下:

(N是总样本数,即R+U,N1为labeled data 属于C1的样本数,N2为labeled data 属于C2的样本数,
其实就是在这之前有标签的数据上加上了无标签数据的所计算得到的概率,可对照之前概率生成模型中的公式写出剩余参数的更新方式)
然后回到第2步,直到参数不再更新,就结束。
上面的第二步就是EM算法中的E,第三步就是M。
算法可以证明最终一定会收敛,但是不同的初始化的参数值会对结果有较大的影响。
理论上,在监督学习中,我们最大化目标函数:
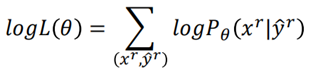
在半监督学习中,由于多了一部分无标签样本,因此目标函数变为:
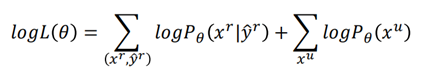 但是我们并不知道无标签数据来自那一个class,就无法估测上面的概率,但是xu可能来自于C1也可能来自于C2,那么:
但是我们并不知道无标签数据来自那一个class,就无法估测上面的概率,但是xu可能来自于C1也可能来自于C2,那么:
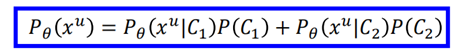 然后就是maxL(θ),但是很不幸的是,上面的式子是不收敛的,无法直接进行求解,因此要是用上述的EM算法进行迭代求解。
然后就是maxL(θ),但是很不幸的是,上面的式子是不收敛的,无法直接进行求解,因此要是用上述的EM算法进行迭代求解。
2.基于低密度区域分隔的假设
什么是基于低密度间隔呢?就是说两类数据,在它们分隔的区域会有明显的“隔离带”(楚河汉界),将两类数据分隔开,如下图所示:
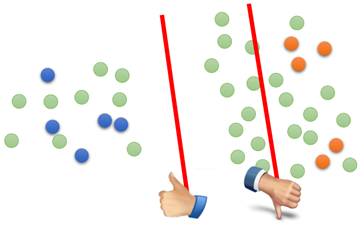
左边那条线就比右边那条线更合理,因为左边能够将数据分的更开(类似于SVM),分开后两边的数据所属类别就比较明确。而右边那一条线对于左半部分数据可能就分类比较模糊。
因此,这种假设称之为“非黑即白”的假设,即unlabeled data要么属于类别1,要么属于类别2。
2.1 self-training
这种假设就有一个比较著名的算法Self-Training,步骤如下:
(1)利用labeled data先训练一个分类模型出来,这个模型是任意的,可以用任意一种;
(2)利用这个模型去对unlabeled data进行分类,成为Pseudo-label;
(3)将一部分分类好的unlabeled data从中移除,并加入到labeled data中去;
(4)重复(1)~(3),直到模型不再发生改变。
那么这里有一个要把一部分数据从unlabeled data中移除的步骤,究竟移除哪一部分数据,通常是移除那一部分确信度比较高的数据,又或者给每一个数据提供一个权重,这里暂不细说。
self-training和前面说的semi-surpervised learning的生成模型有点相似。
这里“非黑即白”就会涉及到一个问题,就是Hard label和Soft label的问题。
所谓Hard label就是当unlabeled data输出比较像class1那么它就是class1,而soft-label是指输出有一定概率属于class1。如下图所示:

然而在神经网络中,假设输出为[0.7,0.3],然后使用soft label将unlabeled data设置为[0.7,0.3],这样对于参数的更新其实并没有用(因为模型参数不需要做任何更新,依然可以输出一样的值)。
但有时使用hard label又过于武断,因此就有了另一种方法Entropy-based Regularization(基于熵值的正则化)。
2.2 Entropy-based Regularization
首先先看几张图,假设对于一个无标签样本分类,有下面三种情况:

在对unlabeled data进行类别判定时,我们希望最终所得到的结果越集中越好,假设有5个类别,对样本xu进行分类,当分类结果为第一张图时,认为结果是好的,
第二张图结果也是好的,因为两张图在某一个类别上的置信度都很大,而第三张图则是不好的,因为我们无法分辨出xu究竟属于哪一类。
那么如何来衡量上面这几个结果的好坏呢?就是熵,熵是用来描述数据的分散程度的,其计算公式为:

熵越小,表示分类越集中,分类的辨识度就越高,因此我们希望其越小越好。上面三张图的熵为:
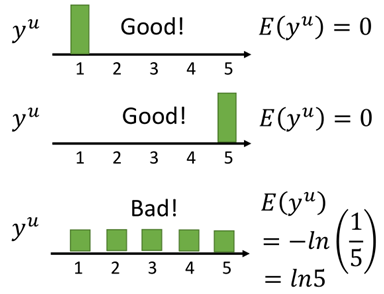
那么基于熵的正则化在半监督学习中就是:在训练过程中,我们不但要求labeled data的损失越小越好,同时也要使得unlabeled data的熵越小越好,即为:
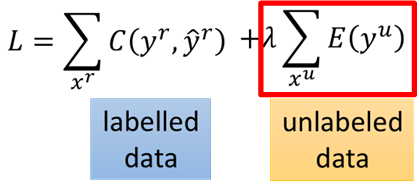
有了损失函数,就可以进行模型训练了。
3.基于平滑的假设
基于平滑的假设的思想就是:当x1和x2通过一个高密度区域相连,那么x1和x2就是相似的。这个思想有点像前面说的DBSCAN的思想。比如下面一张图:
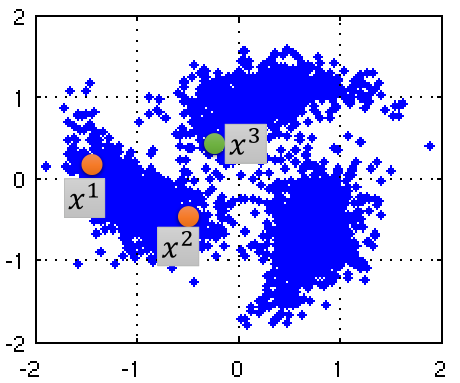
x1和x2从距离计算上来看相聚较远,而x2和x3相聚更近,然而x1和x2中间有一块高密度区域相连,那么就认为x1和x2更相似,而x2和x3则不相似。
那么在半监督学习中如何做呢?有两种思想:
3.1 聚类后再分类
这种方法比较直观,就是将所有的数据进行聚类,然后根据unlabeled data所属的簇中labeled data所属的类即为unlabeled data的类,如图所示:
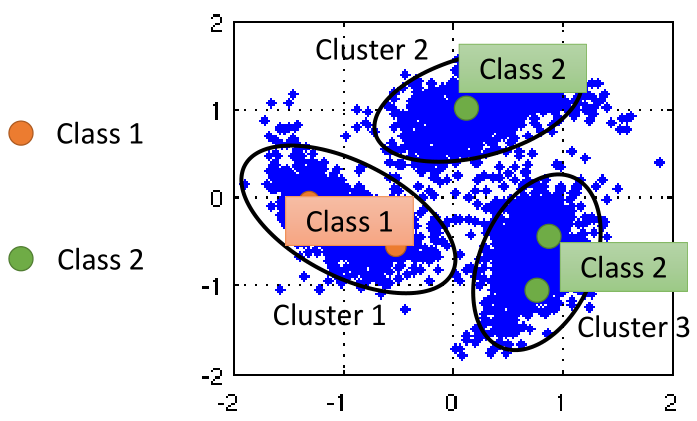
然而,这种方法往往需要数据分布非常好,且聚类效果比较好,要求比较高,因此这种方法得到的结果并不理想。
3.2 图方法
如何知道x1和x2是通过高密度区域相连的呢?我们可以利用数据建立一张图出来,类似这样:

通过这张图就可以知道x1和x2是不是属于同一类别,那么如何建立一张图呢?
(1)首先定义xi和xj之间的相似度s(xi,xj);
(2)然后以某一个点开始建立边,边的连接我们可以采用K-nearest neighbor或者e-neighborhood:
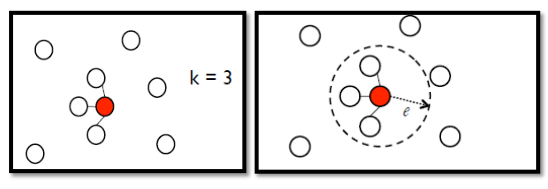
(3)然后每条边的长度即为两个样本之间的相似度。
相似的计算通常采用RBF进行计算(RBF的函数关系就是,近的很近,远的很远):
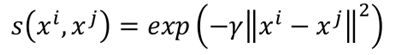
类似于DBSCAN,最后建立一张图:

在建图时一般需要大量的数据,否则有可能会导致图不连贯,断裂,如图所示这样的情况:
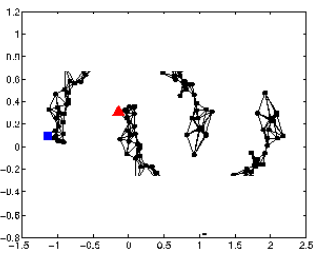
上面是定性地说明图连接如何进行半监督学习的过程,下面定量看一下图建好之后,我们如何来衡量图的好坏:
首先需要定义一个用来衡量一个图好坏的指标S,S的计算如下:

S的值越小,表示图越光滑,越好,如下两个图,来计算一下哪一个图更光滑:

图的边就是上面通过RBF计算得到的权重的大小,y即为分类结果,那么显然左边的比右边的分类结果更合理,因为S更小。
上面的S可以进行一下改写:

其中y是将labeled data和unlabeled data串起来的一个向量,即R+U维:
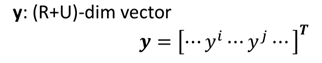
L则是(R+U)*(R+U)维的一个矩阵。这个矩阵就是著名的拉普拉斯矩阵:
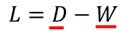
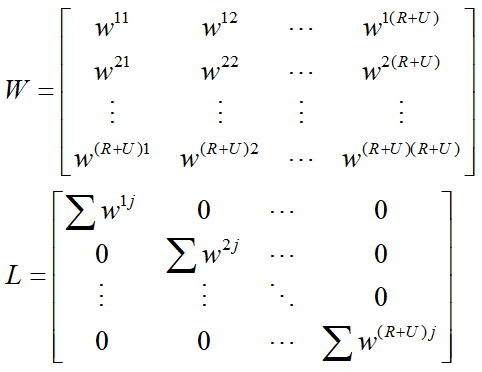
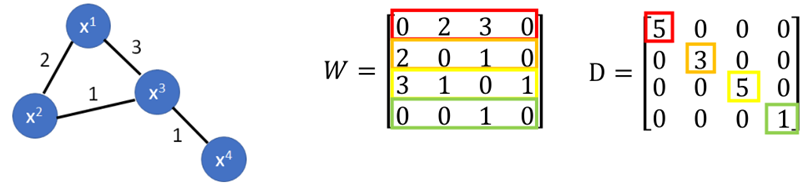
根据上面的图W和L分别为:
那么在进行训练时,由原本的labeled data使得损失最小,还要使得越smooth越好,即S越小越好,即损失函数变成了:

这里y是由模型的参数决定的,因此,有了损失函数后可以直接利用梯度下降进行求解模型。
参考资料:
李宏毅《机器学习》——半监督学习
半监督学习部分就到这里,内容不是很多,全部来源于视频资料,这里主要是进行回顾和整理,但是其思想很多值得学习的地方,因此在这里先进行一个整理,后续如涉及到,会针对具体算法进行实现和学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号