






IO
- 重点:节点流 缓冲流 转换流 对象流
-
![1615629839882]()
-
![1615629883782]()
了解即可的流:标准输入输出流,打印流 ,数据流 。对象流是要求掌握的
Java IO原理及流的分类
- I/O是Input/Output的缩写。I/O技术是非常实用的技术,用于处理设备之间的数据传输。如读/写文件,网络通讯等
- Java程序中,对于数据的输入/输出操作以“流(stream)”的方式进行
- Java.io包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据
- 文件本身没有读写数据的能力 得用流才行
流的原理
- 输入input:读取外部的数据(磁盘,光盘等存储设备的数据)到程序(内存)中
- 输出output:将程序(内存)数据输出到磁盘,光盘等存储设备中
流的分类
- 按操作数据单位不同分为:字节流(8bit),字符流(16bit)(一个字节8位 一个字符是两个字节)
- 按数据流的流向不同分为:输入流,输出流
- 按流的角色不同分为:节点流,处理流
(节点流:直接作用于文件)(处理流:作用于已有的流)
- 节点流可以从一个特定的数据源读写数据
- 处理流是“连接”在已存在的流(节点流或处理流)之上,通过对数据的处理为程序提供更为强大的读写功能
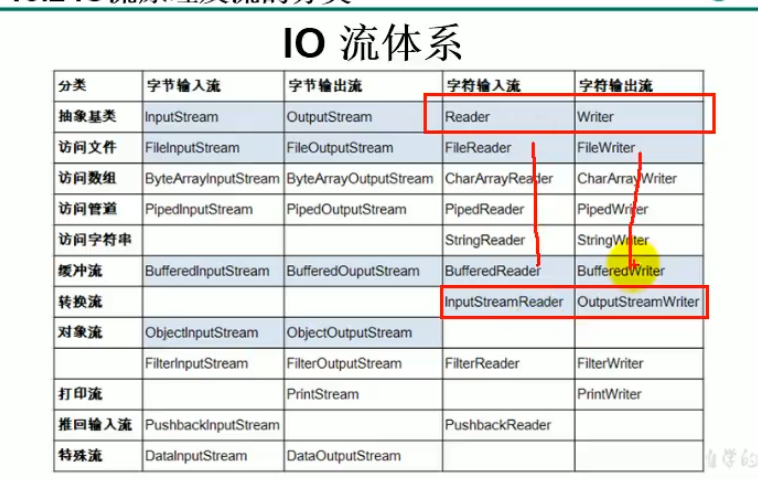
| (抽象基类) | 字节流 | 字符流 |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
- java的IO流共涉及40多个类,实际上非常规则,都是从如下4个抽象基类派生而来
- 由这4个类派生出来的子类名称都是以其父类名作为名字后缀
/*
为什么要有抽象类
因为我们实际去读写的时候太复杂了 我们在这里没有办法知名如何去读去写 这些交给子类去做 我们在这里只从设计的角度讲要想读和写该提供哪些功能 我们把他们呢定义在父类中 具体如何实施子类去做 父类的方法就都抽象化
*/

-
IO流体系【蓝框】重要
-
输入输出标准 只要读入都是read 只要输出都是write
-
以四个基本的节点流为例 把基本输入输出以及套路弄清楚 后续的流关心他们的功能即可 具体实施方面跟这四个特别像 关心什么时候用 功能,怎么用
-
-
-
只有FIleInputStream FileReader,FileOutputStream,FileWriter 是节点流,下面的都是处理流
-
程序中打开的文件IO资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以应该显示关闭文件IO资源

节点流(文件流)
| 抽象基类 | 节点流(文件流) | 缓冲流(处理流的一种) |
|---|---|---|
| InputStream(字节流) | FileInputStream ( read(byte[] buffer) ) | BufferedInputStream ( read(byte[] buffer) ) |
| OutputStream(字节流) | FileOutputStream ( write(byte[] buffer,o,len) ) | BufferedOutputStream ( write(byte[] buffer,o,len) ) / flush() |
| Reader(字符流) | FileReader ( read(char[] cbuf) ) | BufferedReader ( read(char[] cbuf) ) / readLine() |
| Writer(字符流) | FileWriter ( write(char[] cbuf,0,len) ) | BufferedWriter ( write(char[] cbuf,0,len) ) / flush() |
FileReader
- 套路:
-
- File类的实例化 指明要操作的文件 File file = new File("....");
- 提供具体的流 FileReader fr = new FileReader(file);
- 数据的读入
- 资源的关闭
- 还有try-catch-finally{}
-
//在main中
File f1 = new File("hello.txt");//相较于当前工程
System.out.println(f1.getAbsolutePath());
File f2 = new File("shang0\\hello.txt");
System.out.println(f2.getAbsolutePath());
//C:\Users\de'l'l\eclipse-workspace\shang0\hello.txt
//C:\Users\de'l'l\eclipse-workspace\shang0\shang0\hello.txt
@Test
public void TestFileReadr(){
File file = new File("hello.txt");//相较于当前Module
}
package shang0;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/**
* 一、流的分类
* 1.操作数据单位:字节流,字符流
* 2.数据的流向:输入流 输出流
* 3.流的角色:节点流,处理流
*
* 二。流的体系结构
* 抽象基类 节点流(文件流) 缓冲流(处理流的一种)
* InputStream FileInputStream BufferedInputStream
* OutputStream FileOutputStream BufferedOutputStream
* Reader FileReader BufferedReader
* Writer FileWriter BufferedWriter
*
*
* @author de'l'l
*/
public class FileReaderWriterTest {
/**把硬盘中文件里的内容读入到内存里**/
/**说明点:
* 1.read()的理解:返回读入的一个字符 如果到达文件末尾,返回-1
* 2.异常的处理:为了保证流资源一定可以执行关闭操作,需要使用try-catch-finally处理
* 3.读入文件一定要存在,否则就会报FileNotFoundException
* @param args
*/
public static void main(String[] args) /*throws IOException*/ {
// TODO Auto-generated method stub
FileReader fr=null;
try {
//1.实例化File类对象,指明要操作的文件
File file = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang0\\src\\shang0\\hello.txt");
//2.提供具体的流
fr = new FileReader(file);
//3.数据的读入
//read() :返回读入的一个字符 如果达到文件末尾 返回-1
int data;
while((data=fr.read())!=-1) {
System.out.print((char)data);
}
}catch(IOException e){
e.printStackTrace();
}finally {
//4.流的关闭
try {
//fr = new FileReader(file); 防止在这一步没有找到文件出现异常 FielNotFoundException 我们不能使用空指针关闭
// try里包if或者if里包catch均可
// if(fr!=null) {
// try {
// fr.close();
// }catch(IOException e) {
// e.printStackTrace();
// }
// }
//判断操作 是属于赋值之外的其他操作
//局部变量没有默认赋值
//在第一次赋值之前不能进行赋值以外的其他操作
//所以最开始要把fr初始化为null
if(fr!=null) {
fr.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
hello world
- FileReader 的 read()升级操作
/*
* read()方法
* 1.空参 read() 每次只读取一个 并返回读取的字符
* 2.read(char[] cbuff) 每次尽量读取数组长度个字符 存入char型数组
* 如果都不满就尽量读 能读几个读几个(能覆盖几个就覆盖几个位置)
* 3.read(char cbuf[],int off,int len) (这是一个更一般的方法) 往cbuf里读数据 不放满 每次只固定放几个
* read(char []cbuff,0,cbuff.length)就是2.
* public int read(char cbuf[]) throws IOException{
* return read(cbuf,0,cbuf.length);
* }
*/
public class FileReaderWriterTest {
//对read()操作升级
//这一章都逃不出这四步 (2,3可能会有不同)
@Test
public void TestFileReader() {
//2.FileReader流的实例化
FileReader fr = null;
try {
//1.File类的实例化
File file = new File("C:\\\\Users\\\\de'l'l\\\\eclipse-workspace\\\\shang0\\\\src\\\\shang0\\\\hello.txt");
fr = new FileReader(file);
//3.读入的具体操作细节
//read(carbuffer); 把从硬盘文件读取的数据读到char型数组carbuffer里中 carbuffer--cbuf 缓冲小车
//read(carbuffer)返回每次读入carbuffer数组中的字符个数 如果达到文件末尾 返回-1
//字符型!!char数组做FileReader的read()临时存放地!!!
//字节型则要用byte数组做InputStream的read的临时存放地
char[] carBuffer = new char[5];
int len=0;
while((len=fr.read(carBuffer))!=-1) {
//错误写法:
//for(int i=0;i<carBuffer.length;i++){System.out.println(carBUffer[i]);}
//每回read向carBuffer中读数据时 是覆盖上一轮读的 所以如果最后一轮读的不满5个 会输出倒数第二轮读入carBuffer的数据
//正确写法
// for(int i=0;i<len;i++) {
// System.out.print(carBuffer[i]);
// }
//方式二:(错误写法)
//char型数组到String转换 调用构造器
//最后一轮str也是存储了上一轮的部分数据
// String str = new String(carBuffer);
// System.out.print(str);
//正确写法
//从carBuffer中取数据 从0开始取 每次只取len个
String str = new String(carBuffer,0,len);
System.out.print(str);
//等价于上面的循环写法
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
//4.资源关闭
try {
if(fr!=null){
fr.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
//char[]数到String类型的转换写法
//调用String的构造器
char []ch="hello";
String str;
str = new String(ch); //----->hello
str = new String(ch,0,1);//--->h
//(字符型型数组名,起始位置,转换几个)
FileWriter
读入:硬盘->内存
写出:内存->硬盘
/*说明:
1. 输出操作:对应File可以不存在的,并不会报异常
2. File对应的硬盘中的文件如果不存在,并不会报异常
File对应的硬盘中的文件如果存在:
如果流使用的构造器是:FileWriter(file,false)/FileWriter(file) :对原有文件进行覆盖
如果流使用的构造器是:FileWriter(file,true):则不会对原有文件进行覆盖 而是在原内容之上追加
套路:先throw 写完之后再改成try catch finally
*/
@Test
public void testFileWriter(){
//2.提供具体的流
FileWriter fw = null;
try {
//1.提供File类的对象,指明写出到的文件
File file = new File("hello1.txt");
fw = new FileWriter(file,true);
//IOException 可能会创建文件失败把应该
//异常之后会没有给fw赋值 那么后面的关闭就不能在一个变量未初始化之前做动作(不然编译error) 所以要给其初始化
//3.写出的操作
fw.write("I am the winner\n");
fw.write("I hate you");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if(fw !=null) {
//4.流资源的关闭
try {
fw.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
hello2.txt
I am the winner
I hate you
- FileReader 与 FileWriter 结合应用
- 从硬盘中读取一个文件 复制到另一个文件中
/**从硬盘中读取一个文件 复制到另一个文件中**/ @Test public void testFileReaderFileWriter() { //2.提供读入写出流 FileReader fr=null; FileWriter fw=null; try { //1.File类的实例化 一个是要从硬盘中那个文件读入 一个是要输出的文件 File f1 = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang0\\src\\shang0\\hello.txt"); File f2 = new File("hello2.txt"); fr = new FileReader(f1); fw = new FileWriter(f2); //3.读入写出的具体操作 char []cbuf = new char[5]; int len=0; while((len=fr.read(cbuf))!=-1){ fw.write(cbuf,0,len);// for(int i=0;i<len;i++) {// System.out.print(cbuf[i]);// } } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { //先关闭哪个都行 //两个if fw有异常时也可以实现fr关闭 if(fw!=null) { try { fw.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(fr!=null) { try { fr.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
hello.txt hello world12hello2.txt hello world12
- FileReader 和FileWriter 只能用来处理字符型数据 不能用来处理图片(字节)(二进制)
InputStream
-
为什么用字节流去处理英文字符型文本转换成String不乱码?
- 英文中的abcd用一个字节就足够存下
A~65 a~97 z~122 都小于127 所以可以用一个byte存下
有中文就不行了 一个中午在UTF-8里占三个字节
如helloworld123中国人 组成一个中文的字节有可能被拆开 (我们下面的程序是吧她读入到byte []cbuf = new byte【5】;里
则 h e l l o , w o r l d , 1 2 3 中1 中2 , 中3 国1 国2 国3 人1,人2 人3 国2 国3 人1
-
结论:
-
对于文本文件(.txt .java .c .cpp) 使用字符流处理
-
对于非文本文件,(.jpg,.mps,.mp4,avi,doc,ppt.....)使用字节流处理
package shang0review;/**- - 结论:- 对于文本文件(.txt .java .c .cpp) 使用字符流处理- 对于非文本文件,(.jpg,.mps,.mp4,avi,doc,ppt.....)使用字节流处理**/import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;//使用字节流处理文本文件 在控制台输出时 可能出现乱码public class TestFileInoutStream { public static void main(String[] args){ //2.提供具体的流 FileInputStream fis=null; try { // TODO Auto-generated method stub //1.实例化File类 File file = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang0review\\src\\shang0review\\cheer up.txt"); fis = new FileInputStream(file); //3,具体操作 byte[] cbuffer = new byte[5]; int len; while ((len = fis.read(cbuffer)) != -1) { String str = new String(cbuffer, 0, len); System.out.print(str); } } catch (Exception e) { // TODO: handle exception } finally { if(fis!=null) { try { //4.关闭资源 fis.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }}
cheer up.txthey~girl!我爱你啊控制台输出:hey~girl!?野?啊
OutputStream
- 读取图片文件
package shang0review;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;public class TestFileInputFileOutputStream { public static void main(String[] args) { //2.提供具体的流 造流时指明是流向哪个文件或者从哪个文件流出的 FileInputStream fis=null; FileOutputStream fos=null; try { // TODO Auto-generated method stub //1.实例化File类(要读取和写入的对象) File file1 = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang0review\\src\\shang0review\\猪啊猪.jpg"); File file2 = new File("小飞猪.jpg"); fis = new FileInputStream(file1); fos = new FileOutputStream(file2); //3.具体操作 int len = 0;//记录读取长度 便于判断是否结束 以及每次输出多少 byte[] cbuff = new byte[5];//缓冲小车 每轮从硬盘中读取数据存到这里 while ((len = fis.read(cbuff)) != -1) { fos.write(cbuff, 0, len);/**写jpg图片文件**/ //不能String str = new String(cbuff,0,len) // fos.write(str) //FileOutputStream的write只能是int(byte也算是int) } } catch (Exception e) { // TODO: handle exception } finally { //4.关闭资源 if(fis!=null) { try { fis.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(fos!=null) { try { fos.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }}
成功制作了一个 “小飞猪.jpg” 文件 里面是一张图片
- 补充结论
- 如果只是把文件从硬盘中读出再复制到另一个文件里 中间不再内存层面(程序)读取 那么用字节流也行
- 对于文本文件来说
- 字节流:
- 硬盘源文件--------->
内存层面(程序控制台)转化成String显示-------->要写入的文件 - 字节流中间无法转化(会有乱码 原因是因为会有”截断“ 详情见前面) 但如果不转化 只是把他复制到另一个文件 是ok的 只做搬运工
- 字符流:可以转化
- 硬盘源文件------->内存层面(程序控制台)转化成String显示-------->要写入的文件
- 文本文件最好用用字符流 显示到控制台 再复制到目标文件中更好一些,当然,如果只做文件复制的话 字节流也ok
- 但是对于非文本文件来说(图片) 只能用字节流来读取,不能用字符流,即便用字符流但是不显示到控制台也不行!!
public static void main(String []args){ 套下面的程序}z//这是一个下载图片文件的函数!!自己写的!!牛!!public void CopyFile(String srcPath,String desPath) { // System.out.println(file1.getAbsolutePath()); //2.提供具体的流 FileInputStream fis=null; FileOutputStream fos=null; try { //1.实例化file类 File file1 = new File(srcPath);// File file1 = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang01erview\\src\\shang01erview\\猪啊猪.jpg"); File file2 = new File(desPath); fis = new FileInputStream(file1); fos = new FileOutputStream(file2); //3具体操作 int len = 0; byte[] carbuf = new byte[1024];//1024较快 while ((len = fis.read(carbuf)) != -1) { fos.write(carbuf, 0, len); } } catch (Exception e) { e.printStackTrace(); // TODO: handle exception }finally { //4.关闭资源 if(fis!=null) { try { fis.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(fos!=null) { try { fos.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }//参数:源文件名,目标文件名 @Test public void TestCopyFile() { //获取当前系统时间 long start = System.currentTimeMillis();//获取系统当前时间 String srcPath = "C:\\Users\\de'l'l\\Desktop\\01.mov"; String desPath = "C:\\Users\\de'l'l\\Desktop\\02.mov"; CopyFile(srcPath,desPath); long end = System.currentTimeMillis(); System.out.println("复制操作花费的时间为:"+(end-start)); }
结果:成功将一个桌面的视频文件复制到桌面//复制操作花费的时间为:109
处理流
一、缓冲流
-
**1.缓冲流 ** 处理流的一种
-
BufferedInputStream
-
BufferedOutputStream
-
BufferedReader
-
BufferedWriter
-
2.作用:提高流的读取,写入的速度
-
能够提高读写效率原因:内部提供了一个缓冲区
-
为什么更快?
-
BufferedIputStreeam/OutputStream/Reader/Writer 在内部提供了一个缓冲区 byte[1024*8]
// 先读到buffer里缓存着 达到指定大小之后再依次写出 一次多读一些 这样运的次数就少一些 就会快一些
//例如 100块砖 现要从硬盘读取到内存再写入文件 硬盘--->内存--->文件
//假设从硬盘到内存 路费10s 从内存到文件 路费10s
//有两种搬运方式
//1.一次搬一块 搬一块就把一块送到要写入的文件里去 一共要花100 (10+10)=2000s
//2.用一个小车 小车能装10块 装满小车的花费为10s 那么要花 100/10(10+10)=300s
//明显提高了速率 两种方式装砖的时间是一样的,不一样的是运输的时间。显然方案2提高了效率
-
3.处理流:就是"套接"已有的流的基础之上(不一定是节点流)
BufferedInputStream BufferedOutputStream
-
public class BufferedInputStream extends FilterInputStream { private static int DEFAULT_BUFFER_SIZE = 8192; // 8192/1024=8; 8个1024 .............. public BufferedInputStream(InputStream in) { this(in, DEFAULT_BUFFER_SIZE); //该构造器调用另一个参数表符合(InputStream ..,int ...)的构造器 } public BufferedInputStream(InputStream in, int size) { super(in); if (size <= 0) { throw new IllegalArgumentException("Buffer size <= 0"); } buf = new byte[size]; //即在内部提供了一个缓冲区 byte[1024*8] // 先读到buffer里缓存着 达到指定大小之后再依次写出 一次多读一些 这样运的次数就少一些 就会快一些 //例如 100块砖 现要从硬盘读取到内存再写入文件 硬盘--->内存--->文件 //假设从硬盘到内存 路费10s 从内存到文件 路费10s //有两种搬运方式 //1.一次搬一块 搬一块就把一块送到要写入的文件里去 一共要花100*(10+10)=2000s //2.用一个小车 小车能装10块 装满小车的花费为10s 那么要花 100/10*(10+10+10)=300s //明显提高了速率 } } -
案例:非文本文件的复制
-
- 造文件
- 造流
- 2·1 造字节流
FileInputStream fis = new FileInputStream(file1); FileOutputStream fos = new FileOutputStream(file2);- 2.2 造缓冲流
BufferedInputStream bis = new BufferedInputStream (fis); BufferedOutputStream bos = new BufferedOutputStream(fos);3. 复制细节:读取 写出 int len=0; byte []cbufer = new byte[5]; bis.read(cbufer); 4. 关闭资源 bis.close() bos.close() -
-
案例
package shangbuffer;import java.io.BufferedInputStream;import java.io.BufferedOutputStream;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import org.junit.Test;public class BufferedTest { /* * 实现非文本文件的复制 */ @Test public void BufferedStreamTest() { //2.造流 //2.1造字节流 FileInputStream fis = null; FileOutputStream fos = null; //2.2造缓冲流 BufferedInputStream bis = null; BufferedOutputStream bos = null; try { //1.File类的实例化 File srcFile = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang0review\\小飞猪.jpg"); File desFile = new File("C:\\\\Users\\\\de'l'l\\\\eclipse-workspace\\\\shang0review\\\\赤赤.jpg"); fis = new FileInputStream(srcFile); fos = new FileOutputStream(desFile); bis = new BufferedInputStream(fis); bos = new BufferedOutputStream(fos); //3,复制细节操作 :读取 写入 byte[] cbufer = new byte[10]; int len = 0; while ((len = bis.read(cbufer)) != -1) { bos.write(cbufer, 0, len); bos.flush();//刷新缓冲区 //把缓冲区的数据清空 输出到文件 //缓冲区读到8924就会自动flush() } } catch (Exception e) { // TODO: handle exception } finally { if(bis!=null) { try { bos.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(bos!=null) { try { bis.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } //4.关闭资源 //要求:先关闭外部的流,再关闭内层的流// bos.close();// bis.close(); //说明:关闭外层流的同时,内层流也会自动进行关闭,所以我们可以省略对内层流的关闭// fis.close();// fos.close(); } public static void main(String[] args) { // TODO Auto-generated method stub }}
与上面那个没有BufferedInputStream BufferedOutputStream 相比 同一文件更快 那个109ms//复制花费的时间为:25(ms)
自我小结
#读入文本用字符流FileReader /FileWriter (也可以用字节 如果不转化成String的话),读入非文本用字节流(FileInputStream,FileOutputStream) 是害怕乱码#读入文本/非文本用Buffered缓冲流 BufferedInputStream , BufferedOutputStream,BufferedReader, BufferWriter是为了提高速度
BufferedReader BufferedWriter
- BufferedReader/BufferedWriter 结果不知道为啥有乱码 求指教???????(shang0 review)
- 有乱码原因:charset不对 要读取的文件的charset是UTF-8,但是我的eclipise的默认charset不是UTF-8
- 大概是应该要用InputStreamReader把输入字节流InputStream转化成输出字节流时顺便改变charset?
- InputStreamReader isr = new InputStreamReader (new FileInputStream(new File(".....")) , "UTF-8" ) ;
public void CopyFFilewithBuffered(String srcPath,String desPath) { //2.2处理流 缓冲流 BufferedReader br=null; BufferedWriter bw=null; try { //1.实例化File类 File srcFile = new File(srcPath); File desFile = new File(desPath); //2.提供具体流 //2.1节点流 字节流 FileReader fr = new FileReader(srcFile); FileWriter fw = new FileWriter(desFile); br = new BufferedReader(fr); bw = new BufferedWriter(fw); 乱码原因:bw从文件中读取内容时 并不是按照编码UTF-8来读取的 使得读取到cbufer中就存在乱码 所以再从cbufer中写到要保存的文件中自然会有乱码 //3.复制具体操作// int len = 0;// char[] cbufer = new char[1024];// while ((len = br.read(cbufer)) != -1) {// String str = new String(cbufer, 0, len);// System.out.println(str);//转化成字符串,在内存层面上显示 //方式一:使用char数组// bw.write(cbufer,0,len);//// fw.flush();缓冲区满了之后自动flush// } //方式二:使用String 一次读一行 //readLine()返回字符串 读完之后返回null String data; while((data=br.readLine())!=null) { //方法一:// bw.write(data+"\n");//data中不包含换行符 //方法二: bw.write(data); bw.newLine(); } catch (Exception e) { // TODO: handle exception } finally { if(br!=null) { try { br.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(bw!=null) { try { bw.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }// //4.关闭资源// br.close();// bw.close();// } @Test public void testCopyFFilewithBuffered() { long start = System.currentTimeMillis(); String srcPath = "C:\\Users\\de'l'l\\Desktop\\猪猪.txt"; String desPath = "C:\\Users\\\\de'l'l\\\\Desktop\\\\鹿鹿.txt"; CopyFFilewithBuffered(srcPath,desPath); long end = System.currentTimeMillis(); System.out.println("复制花费时间为"+(end-start));
乱码
#include<iostream>//鏂规硶涔嬪悗浼樺寲鏋佸ぇ//[1]涓轰簡鑳介亶鍘嗘墍鏈夋儏鍐碉紝鎴戜滑棣栧厛鑰冭檻鎼滅储椤...------------------------------------------------------------- 改进见下
//1.1 节点流//FileInputStream 字节输入流 InputStreamReader 将其转化为字符输入流输入 FileInputStream fis=new FileInputStream (newFile("C:\\Users\\de'l'l\\Desktop\\pp.txt"));FileWriter fw = new FileWriter(new File("C:\\Users\\de'l'l\\Desktop\\hh.txt")); //1.2 处理流:转换流 //new InputStreamReader(转换流要作用到的字节型的节点流,字符集(charset)) //参数2指明了字符集,具体使用哪个字符,取决于文件pp.txt保存时使用的字符集 InputStreamReader isr = new InputStreamReader(fis,"UTF-8"); //据说使用的默认是UTF-8 但我的不是 //1.3 处理流:缓冲流 BufferedWriter bw = new BufferedWriter(fw); //2.具体细节 char []cbufer = new char[20]; int len; //InputStreamReader是字符流 所以操作读到char型数组 while((len=isr.read(cbufer))!=-1) { String str = new String(cbufer,0,len);//String构造器里没有可以指明字符集的地方 System.out.print(str);//读入cbufer时就会读入文本中的换行 所以不需要自己加 bw.write(str); } //关闭资源 isr.close(); bw.close();//一定要记得关闭资源!!不然输入到文件中的内容会丢失!!!
运行结果无乱码
输出到控制台上的无乱码 并且保存到文件中的也没有乱码
缓冲流复习复习缓冲流复习 加密
-
![1615536912904]()
-
-
这几个都是字节流 但也能实现文本文件的复制
但是不能在控制台看 只能复制 所以我们推荐用字符流处理
-
int b=0;while((b=fis.read())!=-1){ fos.write(b^s);//异或运算 打乱字节 加密} -
mnn=m
m连续异或上同一个数 还是m
加密/解密 都是如下
int len = 0;byte []bbufer = new byte[1024];//千万别忘了在方法里写数组!!!while((len=bis.read(bbufer))!=-1){for(int i=0;i<len;i++) bbufer[i] = (byte) bbufer[i]^5; bis.read(bbufer,0,len);}
-

package shang1; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import org.junit.Test; public class PicTest { public static void main(String []args) { } //图片的加密 @Test public void TestSecret() { // //1.造文件 // File f1 = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang1\\src\\小飞猪.jpg"); // File f2 = new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang1\\src\\肥肥.jpg"); // // //2.造流 // FileInputStream fis = new FileInputStream(f1); // FileOutputStream fos = new FileOutputStream(f2); // BufferedInputStream bis = new BufferedInputStream(fis); // BufferedOutputStream bos = new BufferedOutputStream(fos); // //1.造文件以及流 //[缓冲流 [ 节点流 [ 文件.......] ] ] //直接用文件名也可 FileInputStream的构造器会把它包装成一个File类 BufferedInputStream bis=null; BufferedOutputStream bos=null; try { bis = new BufferedInputStream( new FileInputStream(new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang1\\src\\小飞猪.jpg"))); bos = new BufferedOutputStream( new FileOutputStream(new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang1\\src\\hhhh.jpg"))); //2.具体操作 int len = 0; byte[] bbufer = new byte[1024];//[bbufer-->byte buffer] //别忘了在方法里写byte数组!!!!! while ((len = bis.read(bbufer)) != -1) { //字节数据进行修改 来加密 for (int i = 0; i < len; i++) bbufer[i] = (byte) (bbufer[i] ^ 5); //int 和byte运算完之后转化为byte bos.write(bbufer, 0, len); } } catch (Exception e) { // TODO: handle exception e.printSteckTrace(); if(bos!=null) { try { bos.close(); } catch (IOException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } } if(bis!=null) { try { bos.close(); } catch (IOException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } } } } //图片的解密 //连续异或同以一个数两次 不变---m^n^n=m @Test public void FightSecret() { //1.造文件以及流 //[缓冲流 [ 节点流 [ 文件.......] ] ] //直接用文件名也可 FileInputStream的构造器会把它包装成一个File类 BufferedInputStream bis=null; BufferedOutputStream bos=null; try { bis = new BufferedInputStream( new FileInputStream(new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang1\\src\\小飞猪secret.jpg"))); bos = new BufferedOutputStream( new FileOutputStream(new File("C:\\Users\\de'l'l\\eclipse-workspace\\shang1\\src\\小飞猪4.jpg"))); //2.具体操作 int len = 0; byte[] bbufer = new byte[1024]; while ((len = bis.read(bbufer)) != -1) { //字节数据进行修改 来加密 for (int i = 0; i < len; i++) bbufer[i] = (byte) (bbufer[i] ^ 5); //int 和byte运算完之后转化为byte bos.write(bbufer, 0, len); } } catch (Exception e) { e.printStackTrace(); // TODO: handle exception if(bos!=null) { try { bos.close(); } catch (IOException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } } if(bis!=null) { try { bos.close(); } catch (IOException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } } } } }
运行结果

未完成任务
记录每个字符出现的次数 map实现
二、转换流
InputStreamReader / OutputStreamWriter
-
转换流提供了在字符流和字节流之间的转换
-
Java API提供了两个转换流
- InputStreamReader:将InputStream转换为Reader
- OutputStreamWriter:将Writer转换成OutputStream
-
字节流中的数据都是字符时,转换成字符流的操作更高效
-
很多时候我们使用转换流来处理文件乱码问题。实现编码和解码的功能
-
解码:utf8.txt---字节流---->InputStreamReader(utf-8)----字符流-->程序(内存)
编码:程序---字符流-------->OutputStreamWriter(gbk)-----字节流--->gbk.txt
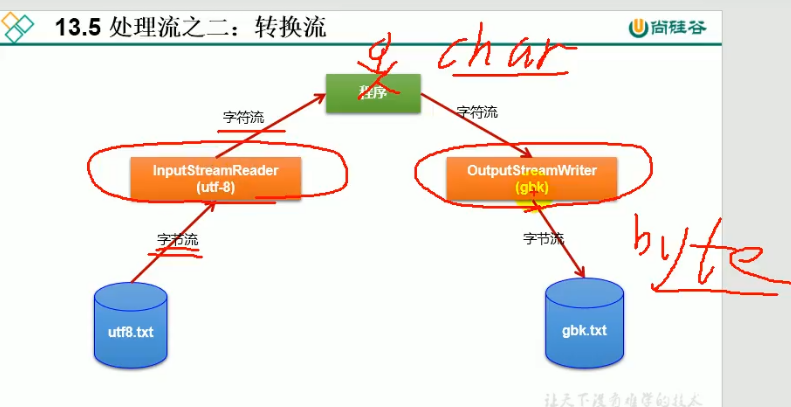
-
- (看后缀)转换流:属于字符流
-
涉及到的类:
-
InputStreamReader:将一个字节的输入流转换为字符的输入流 ----------解码:字节,字节数组---->字符数组,字符串
-
OutputStreamWriter:将一个字符的输出转换为字节的输出流 ----------编码:字符数粗,字符串---->字节,字节数组
-
- 作用:提供字节流和字符流之间的转换
-
- 字符集:文件编码的方式(比如:GBK) ,决定了解析时使用的字符集(也只能是GBK)
-
InputStreamReadr和OutputStream案例
package zhuanhuanliu;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStreamReader;import java.io.UnsupportedEncodingException;/* * InputStreamReader 实现字节输入流到字符输出流的转化 */public class InputStreamReaderAndOutputStreamReaderTest { public static void main (String args[]) throws IOException { //此处应当使用try-catch-finally 但是我偷懒了 //1.造文件以及流 //1.1 FileInputStream fis = new FileInputStream(new File("C:\\Users\\de'l'l\\Desktop\\pp.txt")); //1.2转换流 //new InputStreamReader(转换流要作用到的字节型的节点流,字符集(charset)) //参数2指明了字符集,具体使用哪个字符,取决于文件pp.txt保存时使用的字符集 InputStreamReader isr = new InputStreamReader(fis,"UTF-8"); //据说使用的默认是UTF-8 但我的不是 //2.具体细节 char []cbufer = new char[20]; int len; //InputStreamReader是字符流 所以操作到char型数组 while((len=isr.read(cbufer))!=-1) { String str = new String(cbufer,0,len);//String构造器里没有可以指明字符集的地方 System.out.print(str);//读入cbufer时就会读入文本中的换行 所以不需要自己加 } //关闭资源 isr.close(); }}
指明正确charset,运行结果没有乱码
#include<iostream>/*** * * * (DFS,迭代加深,剪枝,贪心) O(n2n)O(n2n) (n^2)*(2^n) n^2是找在哪里插入数(可以二分来优化乘n*logn) 2^n是枚举每个数属于那个序列 2^55 剪枝+每个数的贪心方法之后优化极大[1]为了能遍历所有情况,我们首先考虑搜索顺序是什么。搜索顺序分为两个阶段:1.从前往后枚举每颗导弹属于某个上升子序列,还是下降子序列;2.如果属于上升子序列,则枚举属于哪个上升子序列(包括新开一个上升子序列);如果属于下降子序列,可以类似处理。[1].a因此可以仿照AcWing 896. 最长上升子序列 II,分别记录当前每个上升子序列的末尾数up[],和下降子序列的末尾数down[]。这样在枚举时可以快速判断当前数是否可以接在某个序列的后面。注意这里的记录方式和上一题稍有不同:这里是记录每个子序列末尾的数;上一题是记录每种长度的子序列的末尾最小值。此时搜索空间仍然很大,因此该如何剪枝呢?[1].b对于第二阶段的枚举,我们可以仿照上一题的贪心方式,对于上升子序列而言,我们将当前数接在最大的数后面,一定不会比接在其他数列后面更差。这是因为处理完当前数后,一定出现一个以当前数结尾的子序列,这是固定不变的,那么此时其他子序列的末尾数越小越好。!!!!注意到按照这种贪心思路,up[]数组和down[]数组一定是单调的,因此在遍历时找到第一个满足的序列后就可以直接break了。!!!!!最后还需要考虑如何求最小值。因为DFS和BFS不同,第一次搜索到的节点,不一定是步数最短的节点,所以需要进行额外处理。一般有两种处理方式:1.记录全局最小值,不断更新; 这种搜索顺序可以参考@一瞬流年丶涅槃同学的题解;2.迭代加深。一般平均答案深度较低时可以采用这种方式。后面的代码中采用的是这种方式。时间复杂度每个数在第一搜索阶段有两种选择,在第二搜索阶段只有一种选择,但遍历up[]和down[]数组需要 O(n)O(n) 的计算量,因此总时间复杂度是 O(n2n)O(n2n)。 /**二分的话则要找到最后一个大于等于a[u]的数 为了在数组中没有符合要求的数时通过+1延长数组(+1来找到真正要用的严格小于a[u]的数)**/ /**int l=0; int r=nu; while(l<r) { int mid=(l+r+1)/2; if(up[mid]>=a[u]) l=mid; else r=mid-1; } int t=up[l+1]; up[l+1]=a[u]; dfs(u+1,max(nu,l+1),nd); up[l+1]=t;**/int main(){ while(cin>>n,n) { ans=n; for(int i=1;i<=n;i++) cin>>a[i]; dfs(1,0,0); cout<<ans<<endl; }}
-
InputStreamReader和OutputStreamWriter 案例
-
package zhuanhuanliu;import java.io.BufferedWriter;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.FileWriter;import java.io.IOException;import java.io.InputStreamReader;import java.io.OutputStream;import java.io.OutputStreamWriter;import java.io.UnsupportedEncodingException;import org.junit.Test;/* * InputStreamReader 实现字节输入流到字符输出流的转化 */public class InputStreamReaderAndOutputStreamReaderTest { public static void main (String args[]) throws IOException { //此处应当使用try-catch-finally 但是我偷懒了 //1.造文件以及流 //1.1 节点流 FileInputStream fis = new FileInputStream(new File("C:\\Users\\de'l'l\\Desktop\\pp.txt")); FileWriter fw = new FileWriter(new File("C:\\Users\\de'l'l\\Desktop\\hh.txt")); //1.2 处理流:转换流 //new InputStreamReader(转换流要作用到的字节型的节点流,字符集(charset)) //参数2指明了字符集,具体使用哪个字符,取决于文件pp.txt保存时使用的字符集 InputStreamReader isr = new InputStreamReader(fis,"UTF-8"); //据说使用的默认是UTF-8 但我的不是 //1.3 处理流:缓冲流 BufferedWriter bw = new BufferedWriter(fw); //2.具体细节 char []cbufer = new char[20]; int len; //InputStreamReader是字符流 所以操作到char型数组 while((len=isr.read(cbufer))!=-1) { String str = new String(cbufer,0,len);//String构造器里没有可以指明字符集的地方 System.out.print(str);//读入cbufer时就会读入文本中的换行 所以不需要自己加 bw.write(str); } //关闭资源 isr.close(); bw.close(); } @Test public void test() { OutputStreamWriter osr=null; InputStreamReader isr = null; try { //1.造文件 造流 File file1 = new File("C:\\Users\\de'l'l\\Desktop\\二分.txt"); File file2 = new File("C:\\\\Users\\\\de'l'l\\\\Desktop\\\\二分01.txt"); FileInputStream fis = new FileInputStream(file1); isr = new InputStreamReader(fis,"UTF-8");//读入 解码 FileOutputStream fos = new FileOutputStream(file2); osr = new OutputStreamWriter(fos,"gbk");//写出 编码 //写出的文件放在桌面上时会自动给识别用哪种格式写入文件的 所以在桌面上可以正常显示 ANSI--就是国内的gbk //如果直接放在eclipse里则会按照gbk来 则乱码 //2.具体操作 int len = 0; char []cbufer = new char[1024]; while((len=isr.read(cbufer))!=-1) {// String str = new String(cbufer,0,len);// System.out.print(str); osr.write(cbufer,0,len); } } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (UnsupportedEncodingException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { if(isr!=null) { try { isr.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(osr!=null) { try { osr.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } } -
//运行结果//写出的文件放在桌面上时会自动给识别用哪种格式写入文件的 所以在桌面上可以正常显示 ANSI--就是国内的gbk//如果直接放在eclipse里则会按照gbk来 则乱码
字符集
-
字符编码
-
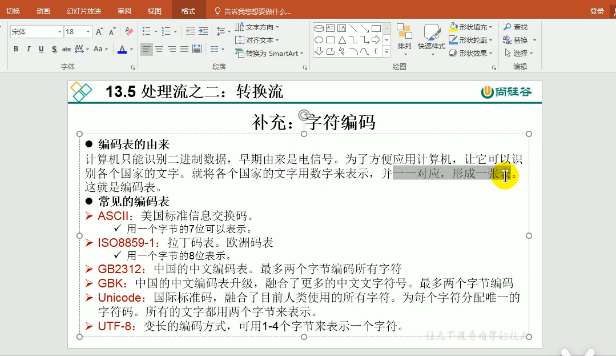
编码表的由来:计算机只能识别二进制数据,早期由来是电信号,为了方便应用计算机,让它可以识别各个国家的文字,就将各个国家的文字用数字来表示,并一一对应,形成一张表,这就是编码表
-
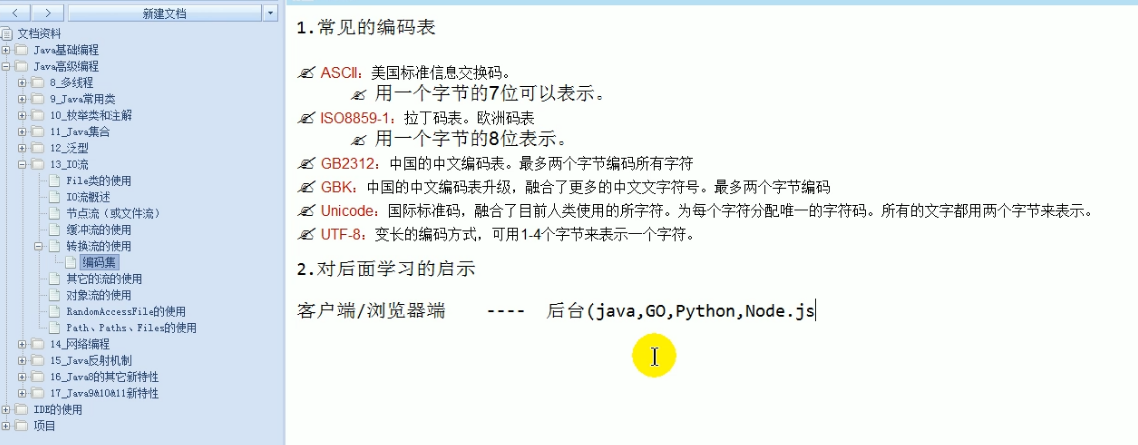
ASCII:美国标准信息交换码 用一个字节的7位表示
-
ISO8859-1:拉丁码表,欧洲码表
-
GB2312:中国的中文编码表,最多两个字节编码
-
GBK:中国的中文编码表升级:融合了更多的中文文字符号,最多两个字节编码
- GBK GB2312 判断字符是由一个字节还是两个字节表示由首位的0/1决定
-
Unicode: 国际标准码,融合了人类目前所使用的所有字符,为每个字符分配唯一的字符码,所用的文字都用两个字节来表示
-
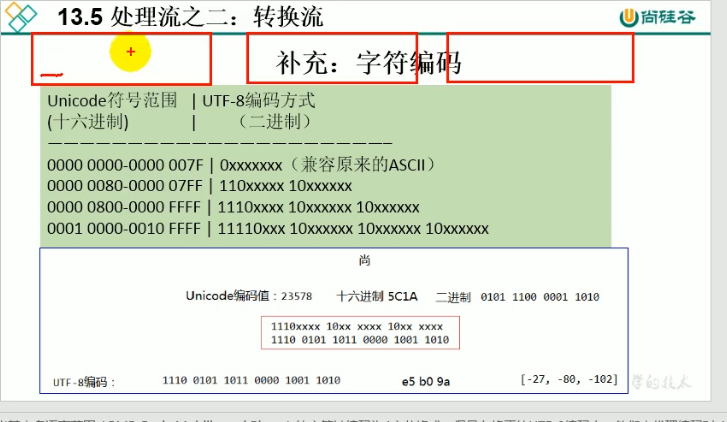
UTF-8:变长的编码方式,可用1-4来表示一个字节
Unicode 全世界符号加在一起也不超过2^16种 所以两个字节即可
-
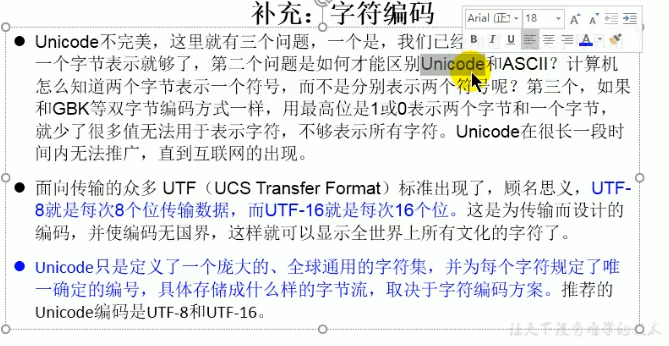
Unicode不完美 三个问题
-
- 英文字母只用一个字节表示就够了
-
-
如何才能区别Unicode和ASCII?
-
计算机怎么知道两个字节表示一个符号?而不是分别表示两个符号呢?如果就和GBK等双字节变啊,1方式一样,用最高位1或0表示两个字节和一个字节,就减少了很多可以表示的字符。
-
-
Unicode在很长时间没有落地 知道互联网出现
-
-
面向传输的众多UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次传输8个位传输数据,而UTF-16就是每次传输16个位。这就是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了
-
Unicode只是定义了一个庞大的,全球通用的字符集,并为每个字符规定了唯一的编号,具体存储成什么样的字节流,取决于字符编码方法。推荐的Unicode编码是UTF-8和UTF-16
-
中文在Unciode中用3个字节存储
-
注(了解):在标准UTF-8编码中,超出基本多语言范围的字符被编码为4字节模式,但是再修正的UTF-8编码中,他们由代理代码对表示,然后这些代理编码对在序列中分别重新编码,结果标准UTF-8编码中需要四个字节的字符,在修正后的UTF-8编码中需要6个字节
-
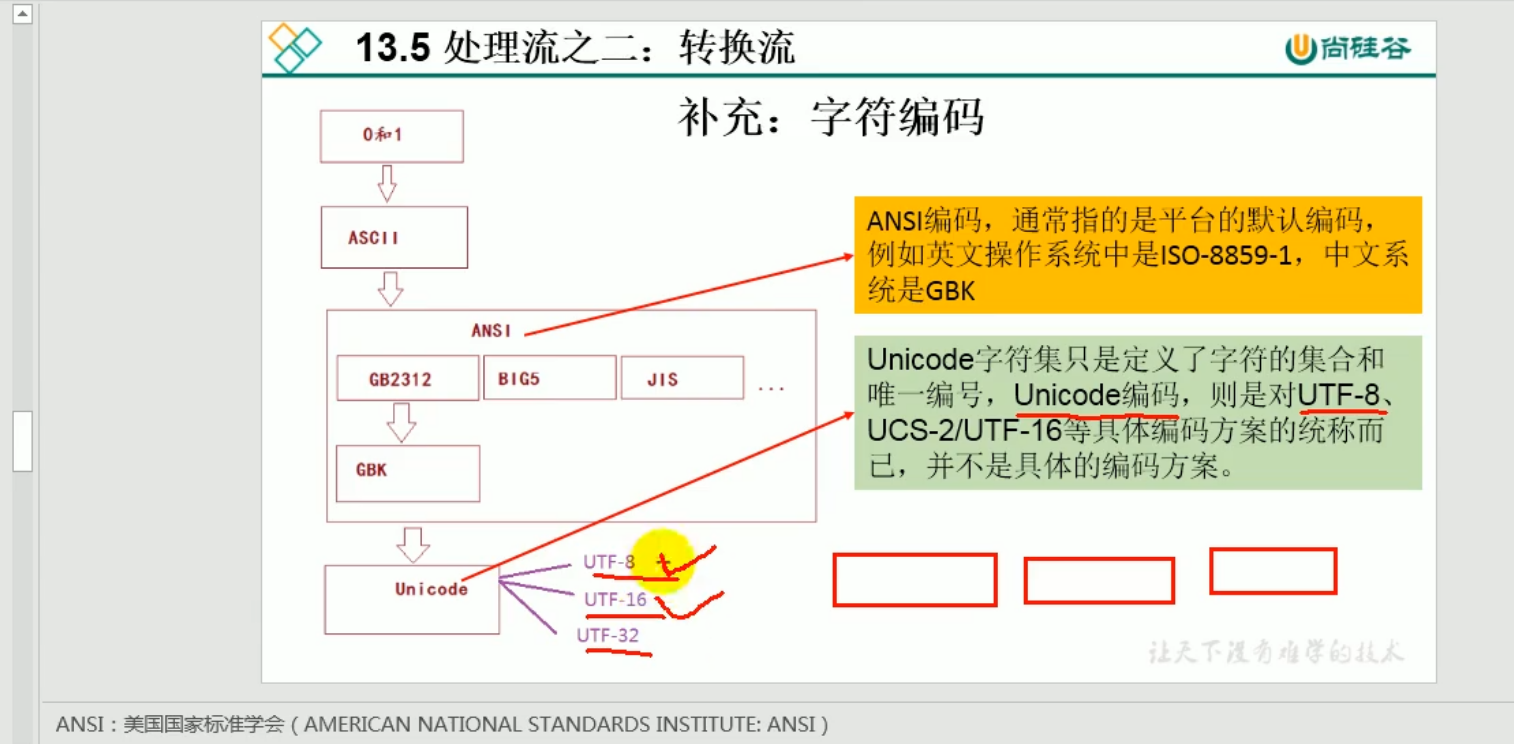
0和1-----------------> ASCII --------------->ANSI(GB2312->GBK,JIS...)------------>Unicode (UTF-8,UTF-16,UTF-32)(常用-8)
-
ANSI编码,通常指的是平台默认编码,例如英文操作系统是ISO-8559-1,中文系统是GBK
-
Unicode字符集只是定义了字符的集合和唯一编号,Unicode编码,则是对UTF-8,UTF-16,UTF-32等具体方案的统称,并不是具体的编码方案
-
对后面学习的启示:
-
客户端/浏览器端 <-------> 后台(Java,Go,Pyhton,Node.js)<-----> 数据库
要求前端后端使用的字符集要统一:UTF-8
三 、标准输入,输出流(了解即可)
System.in / System.out
- System.in:标准输入流
- System.out:标准输出流


package zhuanhuanliu;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;/** * 1.标准的输入、输出流 * 1.1 * System.in:标准的输入流,默认从键盘输入 * System.out:标准的输出流,默认从控制台输出 * * 1.2 * System类的setIn(InputStream is)/setOut(PrintStream ps)方式重新指定输入和输出的流 * * 1.3练习 * 从键盘中输入字符串,要求将读取到的整行字符串转换成大写输出。然后继续进行输出操作 * 直至当输入"e"活着"exit"时 退出程序 * * 方法一:使用Scanner实现 调用next()返回一个字符串 * 方法二:使用System.in实现 System.in---->转换流---->BufferedReader的readLine() * @author de'l'l * */public class OtherStream {//System.in一样的套路 public static void main(String[] args) { // TODO Auto-generated method stub BufferedReader br=null; try { //提供流 只不过终点不是文件了 而是从键盘输入 InputStreamReader isr = new InputStreamReader(System.in); br = new BufferedReader(isr); while(true) { System.out.println("请输入字符串:"); String data = br.readLine(); if("e".equalsIgnoreCase(data)||"exits".equalsIgnoreCase(data)) { System.out.println("程序结束"); break; } } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { if(br!=null) { try { br.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }}
- 问题作业 如何实现一个能读任何数据的类?
![1615558533799]()
四、 打印流(了解即可)
PrintStream / PrintWriter

-
实现将基本数据类型的数据格式转化为字符串输出
-
打印流:PrintStream 和PrintWriter
-
提供了一系列重载的print()和println()方法,用于多种数据类型的输出
-
PrintStream和PrintWriter的输出不会抛出IOException异常
-
PrintStream和PrintWriter都有自动flush功能
-
PrintStream打印的所有字符都是用平台的默认字符编码转换为字节
在学要写入字符而不是写入字节的情况下,应该使用PrintWriter类
-
System.out返回的时PrintStream的实例
-

/* * 2.打印流:PrintStream 和PrintWriter * 2.1 提供了一系列重载的print方法 * ....... 有时间再写吧。。。。 * 截图了。。。 */
五、数据流(了解即可)
DataputStream / DataOutputStream

/* *3.数据流 *如果要保存变量 放在内存中又不太靠谱 就可以用这两个流 把他们读入文件 用的时候在读取出来 *3.1 DataInputStream 和DataOutputStream *3.2 作用:用于读取或写出基本数据类型的变量或字符串 *练习:将内存中的字符串,基本数据类型变量写出到文件中 * * 注意:处理异常的话,仍然使用try-catch-finally */ @Test public void test3() throws IOException { //1.造流造文件 DataOutputStream dos = new DataOutputStream(new FileOutputStream(new File("data.txt"))); //2.操作 注意读取顺序 要按照写入文件的顺序来读取 dos.writeUTF("孙河陈"); dos.flush();//刷新操作 将内存中的数据写入文件 dos.writeInt(23); dos.flush(); dos.writeBoolean(true); dos.flush(); //关闭资源 dos.close(); } //这个写出来的文件不是双击去读 要用DataInputStream来读 /*将文件中存储的基本数据类型变量和字符春读取到内存中,保存在变量里 * */ @Test public void test4() throws IOException { //1. DataInputStream dis = new DataInputStream(new FileInputStream(new File("data.txt"))); //2.注意读取顺序 String name = dis.readUTF(); int age = dis.readInt(); boolean isMale = dis.readBoolean(); System.out.println("name = "+name); System.out.println("age = "+age); System.out.println("isMale = "+isMale); //3. dis.close(); }
复习问题
IO流概述
-
-
说明流的三种分类方式
- 按角色(作用于谁)划分:节点流(作用于文件),处理流(作用于已有的流)
- 按操作的数据单位划分:字符流,字节流
- 按(相对于内存的)流向分:输入流,输出流
-
写出4个IO流中的抽象基类,四个文件流,四个缓冲流
抽象基类 文件流 缓冲流 InputStream(字节流) FileInputStream BufferedInputStream OutputStream(字节流) FileOutputStream BufferedOutputStream Reader(字符流) FileReader BufferedReader Writer(字符流) FileWriter BufferedWriter 拿到一个流之后 如何判断属于什么类型的流?
看后缀!!!
InputStreamReader:父类Reader
如上一堂课讲的异常:XxxException XxxError
-
字符流于字节流的区别及使用情景
- 字符流读出来的是char 字节读出来的的byte
- 字节流:read(byte【】bbuffer) 返回读取的长度 / read() 空参的返回一个字节
- **字符流:read(char【】cbufer)返回读取的长度/ read() 返回一个字符 **
- 对于文本文件:在读取文本文件并复制到另一个文件中时 最好用字符流 这样可以在控制台输出查看,也可以用字节流,但是无法在控制台输出查看
- 对于非文本文件:在读取非文本文件时 只能用字节流byte
-
使用缓冲流实现a.jpg文件赋值为b.jpg文件的操作
BufferedInputStream bis = new BufferdeInputStream(new FileInputStream(new File("a.jpg")));//【缓冲流 【文件流【文件】】】//BufferedInput/OutputStream 是处理流 只能作用于已有的流 没有构造器使他能直接作用于File文件BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File("b.jpg")));//【缓冲流 【文件流 【文件】】】byte [] bbufer = new byte[1024];int len;while((len=bis.read(bbufer))!=-1){ bos.write(bbufer,0,len);}bis.close();bos.close();//此时的异常应该用用try-catch-fnally处理 不用throws -
转换流是哪两个类?分别的作用是什么?请分别创建两个类的对象
- InputStreamReader : 将输入的字节流转换为输入的字符流(解码)
- OutputStreamWriter : 将输出的字符流转换输出的为字节流(编码)
InputStreamReader isr = new InputStreamReader(new FileInputStream(new File("a.txt","...(charset)")));//因为要转化成可读的字符 所以只能文本文件,不能是非文本文件//所用charset取决于要读取的文本在最初存储的时候是用的什么字符集存储的//(英文字符不管在gbk gb2312 utf-8.... 还是什么什么 都是和ASCII一样的 所以英文不会出现乱码)OutputStreamWrter osw = new OutputStream(new FileOutputStream(new File("sss.txt","charset")));//这里的charset不需要参照别的编码自己想怎么编就怎么编 -
-
输入,输出的标准化过程
- 4.1 输入过程
- 创建FIle类对象,指明读取的数据的来源。(要求此文件一定要存在)
- 创建相应的输入流,将File类的对象作为参数,传入流的构造器中
- 具体的读入过程:
- 创建相应的 byte[] 或 char[] 数组
- 关闭流资源
- 说明:程序中出现的异常需要使用try-catch-finally处理
- 4.2 输出过程
- 创建File类对象,只能够输出的数据流向(不要求此文件一定存在)
- 创建相应的输入流,将File类的对象作为参数,传入流的构造器中
- 具体的输出过程:
- 利用之前创建的byte[] 或者char[] 写入指定长度
- write(char []/byte[] cbuffer,0,len)
- 关闭流子源
- 说明:程序中出现的异常需要使用try-catch-finally处理
- 4.1 输入过程
-
相对路径在IDEA和Eclipse中使用的区别?
IDEA:如果使用单元测试方法,相对路径基于当前的Module的
如果使用main()测试,相对路径基于当前Project的
Eclipse:无论是单元测试还是main() 都是基于当前Project
- 缓冲流
-
缓冲流涉及到的类:
- BufferedInputStream 非文本
- BufferedOutputStream 非文本
- BufferedReader 文本
- BufferedWriter 文本
-
作用:提高流的读取,写入速度。提高读写速度原因:内部提供了一个缓冲区 默认是8kb
-
public class BufferedInputStream extends FileterInputStream{ private static int DEFAULT_BUFFER_SIZE = 8192;}
-
转换流(重点)
.........
OtherStream
-
标准输入输出流
System.in:标准的输入流 默认从键盘输入
System.out:标准的输出流,默认从控制台输出
修改默认的输入和输出行为:
System类的setIn(InputStream is)/setOut(PrintStream)方式重新制定输入和输出的流
-
打印流:
PrintStream 和PrintWriter
- 说明:提供了一系列重载print()和println方法,用于多种数据类型的输出
- System.out返回的是PrintStream的实例
- 看P601~603
-
数据流:
DataInputStream 和DataOutputStream
作用:用于读取或写出基本数据类型的变量或字符串
- 实现将基本类型输出成字符串
![1615633845928]()
六、 对象流
ObjectInputStream / ObjectOutputStream
-
用于存储和读取基本数据类型数据或对象的处理流。他的强大之处就是可以把Java的对象写入到数据源中,也能把对象从数据源中还原回来
-
序列化:用ObjetOutputStream类保存基本数据类型或对象的机制
-
反序列化:用ObjectInputStrem类读取基本类型数据或对象的机制
-
ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量
-
对象的序列化‘
-
对象序列化机制允许内存中的Java对象转换成平台无关的二进制,从而允许把这种二进制流持久的保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。当其他程序获取了这种二进制流,就可以恢复成原来的Java对象
-
序列化的好处是在于可将任何时间了Serializable接口的对象转化为字节数据,使其在保存和传输时可以被还原
-
序列化是RMI(Rmote Mehtod Invoke--远程方法调用)过程的参数和返回值都必须实现的机制,而RMI是JavaEE的基础。因此序列化机制是JavaEE平台的基础
-
如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一。否则,会抛出NotSeriaizableException异常
- Serializable 可串行化的 (可序列化的)
- Externalizable
-
凡是实现Serializable接口的类都有一个标识序列化版本标识符的静态变量:
- private static final long serialVersionUID
- serialVersionUID用来表明类的不同版本间的兼容性。简言之,其目的是以序列化对象进行版本控制,有关各版本反序列化时是否兼容
- 如果类没有显式定义这个静态变量,他的值是Java运行时环境根据类的内部细节自动生成的。若类的实例变量做了修改,serialVersionUID可能发生变化。故建议,显式声明。
-
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地行营实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
-
实例
package shangduixiang;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.ObjectInputStream;import java.io.ObjectOutputStream;import org.junit.Test;/** * 本节重点:序列化机制 而不非得是对象流 * 对象流的使用: * 1. ObjectInputStream 和 ObjectOutputStream * * ObjectInputStream :把程序中的Java对象(转化成二进制)保存到硬盘或者传输到网络 * ObjectOutputStream :把内存中的被转化成二进制的对象再转化过来 输入到内存 * Person对象 在一端---时光门---> (二进制)[硬盘/网络] ----时光门---->在另一端出来 * 对象--ObjectOutputStream--硬盘/网络---ObjectInputStream--->输入到内存/传输到网络那端 * 对象要求: * a.可序列化 serializable * b.serialVersionUID 身上要给标识 是为了在转化成二进制和还原的时候不和其他对象的二进制串 所以加上标识 为了识别是哪一个类 * * 2. 作用:用于存储和读取基本类型数据或对象的处理流,他的强大之处就是可以把Java中的 * 3. 要想一个Java对象是可序列化的 需要满足相应的需求,见Person.java * 4. 序列化机制: * * @author de'l'l * */public class TestObjectOutputStream { //序列化过程:将内存中的Java对象保存到磁盘中或通过网络传输出去 //使用ObjectOutputStream实现 @Test public void test(){ // TODO Auto-generated method stub ObjectOutputStream oos=null; try { oos = new ObjectOutputStream(new FileOutputStream(new File("data.dat")));//这个写出来的文件不能看 不是让我们看的 如果要看 就要写反序列化过程 //2.写出过程 oos.writeObject(new String("我爱北京天安门")); //数据一开始在内存层面可能会被回收 于是我们把他写入文件(可以持久保存)或者通网络直接传输出去也是OK的 oos.flush();//刷新操作 把缓冲区的内容全部写入文件 oos.writeObject(new Person("小明",15)); oos.flush();// } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { if(oos!=null) { try { oos.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } //反序列化:将磁盘文件中的对象还原为内存中的一个Java对象 //使用ObjectInputStream @Test public void testObjectInputStream() { //1.造流造文件 ObjectInputStream ois = null; try { ois = new ObjectInputStream(new FileInputStream(new File("data.dat"))); //2.读取操作 readObject() 写的时候先写的String 读的时候也得先读String Object obj = ois.readObject(); String str = (String) obj;//我们读的obj本身就是一个字符串 所以可以强转 Person p = (Person) ois.readObject(); //readObjet()一次读一个对象好像 System.out.println(str); System.out.println(p); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { if(ois!=null) { try { ois.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }}package shangduixiang;import java.io.Serializable;//如果Person不实现序列化则不能被ObjectOutputStream流写到文件中//String类为什么就不报错? 因为String已经自己实现了一个Serializable接口//Serializable接口中无任何方法 这样的接口称为标识接口/** * Person需要满足如下要求,方可序列化 * 1. 需要实现接口:Serializable * 2.当前类提供一个全局常量:serialVersionUID * 3.除了当前Person类需要实现Serializable接口之外,还必须保证其内部的所有属性也必须是可序列化的 * 默认情况下 基本数据类型也是可序列化的 * 补充:ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员 * @author de'l'l * */public class Person implements Serializable{ //实现序列化必须要给(随便写一个值即可)// public static final long serialVersionUID = 4246465L;//序列反转号 //属性 自己不初始化 也会自动初始化 private int age; private String name; public Person(String name,int age){ this.age = age; this.name = name; } @Override public String toString() { return "Person [age=" + age + ", name=" + name + "]"; } public void setAge(int age) { this.age = age; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public String getName() { return name; }}
随机存取文件流(没有转换流和缓冲流重要)
RandomAccseeFile类(独立于四大抽象类之外)
-
(没法根据后缀判断类型hh)
-
RandomAccessFile声明在java.io包下,但直接继承于java.lang.Object类。并且它实现了Datainput和DataOutput这两个接口,也就意味着这个类可以读也可以写
-
RandomAccseeFile类支持 ” 随机访问 “的方式,程序可以直接跳到文件的任意地方来读,写文件
- 支持只访问文件的部分内容
- 可以向已存在的文件后追加内容
-
RandomAccseeFile 的对象包含一个记录指针,用以标识当前读写处的位置。RandomAccseeFile类对象可以自由移动记录指针
- long getFilePointer() 获取文件记录指针的当前位置
- void seek(long pos) 将文件记录指针定位到pos位置
- 指针位置从0开始 文件中的第一个字符就是位置0
-
RandomAccessFile的写 就是覆盖原先文件的内容
-
构造器:
- public RandomAccessFile(File file,String mode)
- public RandomAccessFile(String name,String mode)
-
创建RandomAccessFile类实例需要指定一个mode参数,该参数只当RandomAccessFile的访问模式:
- r 以只读的方式打开
- rw 打开以便读取和写入
- rwd 打开以便读取和写入,同步文件内容的更新
- rws 打开以便读取和写入,同步文件内容和元数据的更新
-
如果模式为只读r,则不会创建文件,而是会读取一个已经存在的文件,如果读取的文件不存在则会出现异常。如果模式为rw读写,如果文件不存在则会去创建文件。如果存在就不会创建
-
案例:复制 覆盖 插入
package shangduixiang;import java.io.File;import java.io.FileNotFoundException;import java.io.IOException;import java.io.RandomAccessFile;import org.junit.Test;//import sun.security.action.GetBooleanAction;/** * RandomAccessFile的使用 * 1.RandomAccessFile直接继承于java.langObject类 实现了DataInput和DataOutput接口 * 2.RandomAccessFile既可以作为一个输入流,又可以作为一个输出流 * 3.如果RandomAccessFile作为输出流存在 写出到的文件如果不存在,则在执行过程中自动创建 * 如果写出到的文件存在,则会对原有文件内容进行覆盖(默认情况下,从头覆盖)(能覆盖多少是多少)(不是覆盖文件 是覆盖内容) * (所以我们一般都是在文件末位追加 ,而不做插入)(利用RandomAccessFile的seek((int)要写入文件.length()); 来定位指针 * * 优点:RandomAccessFile 的seek() * 浏览器下载:不能续传 只能从头开始 迅雷下载:可以续传 * @author de'l'l * *///1.文件复制public class RandomAccessFileTest { public static void main(String[] args) { // TODO Auto-generated method stub RandomAccessFile raf1=null; RandomAccessFile raf2=null; File f2 = new File("2021.3.14.txt"); try { raf1 = new RandomAccessFile(new File("review.txt"),"r"); raf2 = new RandomAccessFile(f2,"rw"); //2.具体读写操作 int len = 0; byte []bbufer = new byte[1024];// raf2.seek(3); /**1.将指针移动到角标为3的位置 要写的文件的第一个位置指针为0**/// 2.如何追加? 移动到文件无内容的第一位即可 所以用文件的长度// 如文件原先有4个字 a b c d// 0 1 2 3 文件.length()即返回4// 所以要写的文件.seek(要读文件.length)即将指针定位到下一位要书写的地方 raf2.seek(f2.length()); while((len=raf1.read(bbufer))!=-1) { raf2.write(bbufer,0,len); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { if(raf1!=null) { try { raf1.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(raf2!=null) { try { raf2.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } //2.对文件覆盖 @Test public void test2() throws IOException { RandomAccessFile raf1 = new RandomAccessFile("C:\\Users\\de'l'l\\eclipse-workspace\\shang1\\src\\zhuanhuanliu\\yy.txt","rw"); raf1.write("ccccccccccccc".getBytes()); //将字符串转化为字节 //RandomAccessFile的write只能写字节 所以要把字符串转化成字节 raf1.close(); } //3.插入 @Test //此处应当用try-catch-finally //如何插入文件 将要插入的位置之后的内容复制到一个地方 插入(覆盖)要插入的内容之后再接着将这些保存的原内容覆盖进去 public void test3() throws IOException { //1. RandomAccessFile raf1 = new RandomAccessFile(new File("review.txt"),"rw"); //2.具体操作 //2.1 先将插入位置之后的内容读取下来保存在字符串中 raf1.seek(3);//将指针定位到要插入的位置 以便复制之后的内容 //避免总是扩容(StringBuilder底层默认实现大小为16的数组)(我们指定大小为要读取文件的长度 就一i的那个不会扩容了 节省时间) StringBuilder sb = new StringBuilder((int) new File("review.txt").length()); //File的length()方法返回long型 StringBuilder要int型 所以要强转 byte []bbufer = new byte[20]; int len=0; //读取的时候是 :文件指针移动一格,raf1读取一个。在内容都读取完时,文件指针有向下移动一个位置,但此时这个位置已无内容 raf1什么也没读到 所以返回-1 while((len=raf1.read(bbufer))!=-1) { String str = new String(bbufer,0,len);//一定别忘了0,len指定长度 不然最后一轮str可能会保留上一轮的部分数据 System.out.print(str); sb.append(str); } //2.2 再将要插入的内容插入进去 //此时读完之后 文件指针已指向文件的末位置的下一个位置 //所以需要把重新定位文件指针 到要插入的位置 raf1.seek(3); raf1.write("888".getBytes()); //2.3 将StringBuilder中的数据写入到文件中 raf1.write(sb.toString().getBytes());//StringBuilder-->String-->Byte raf1.close(); } //思考:将StringBuilder替换为ByteArrayOutputStream // paramater n.决定因素; 规范; 范围;// denote v.标志 预示 象征 意指// specify v.具体说明;明确规定;详述;详列 }
- 注意: 与IDEA不同 eclispe 无论是在test还是在main方法 都是以工程为单位去找文件
- eclispe以工程为单位找相对路径 如果想写文件的相对路径,要注意他只会在工程的一级目录下找文件。所以直接写写文件里的子文件的名字是找不到的。无论怎样 写绝对路径都能找到。绝对路径:从最高一级开始写。
//1.成功在project的一级目录(与src同级)下复制了一个小飞猪.jpg到hhh.jpg//2.覆盖了自己//3.成功插入了自己abcdefghijkelmnopqrst abc888defghijmnopqrst
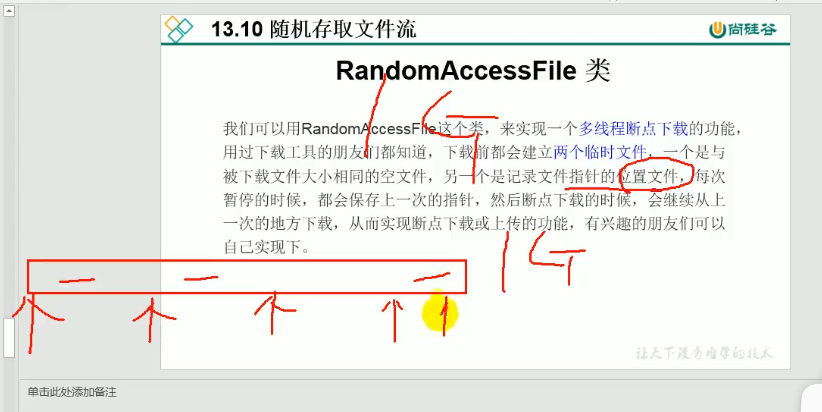
- 我们可以用RandomAccessFile这个类,来实现一个多线程断点下载的功能,。用过下载工具的朋友都知道,下载前都会建立两个临时文件,一个是与被下载文件大小相同的空文件,另一个是记录文件指针的位置文件,每次被暂停时,都会保存上一次的指针,然后断点下载的时候,会继续从上一次的地方下载,从而实现断点下载或上传的功能。
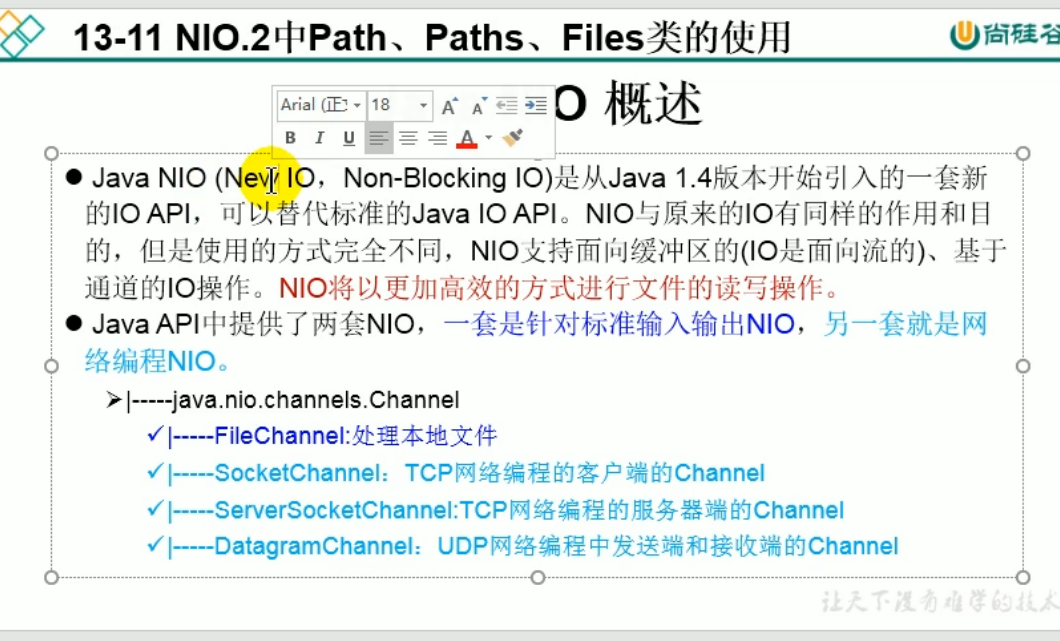
NIO(目前了解即可)

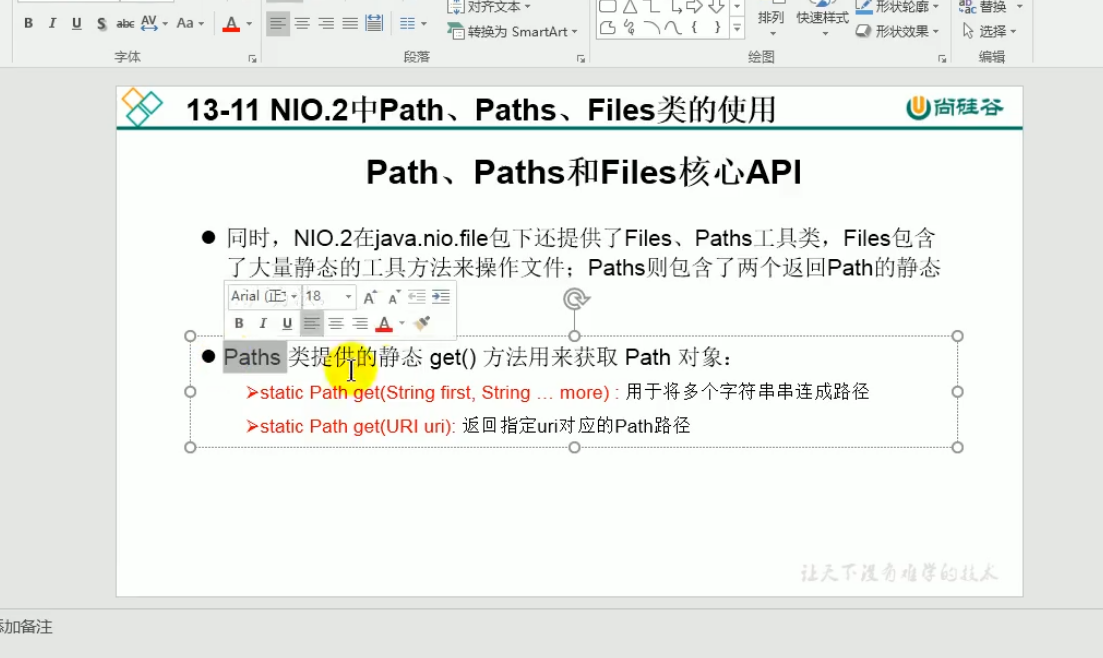

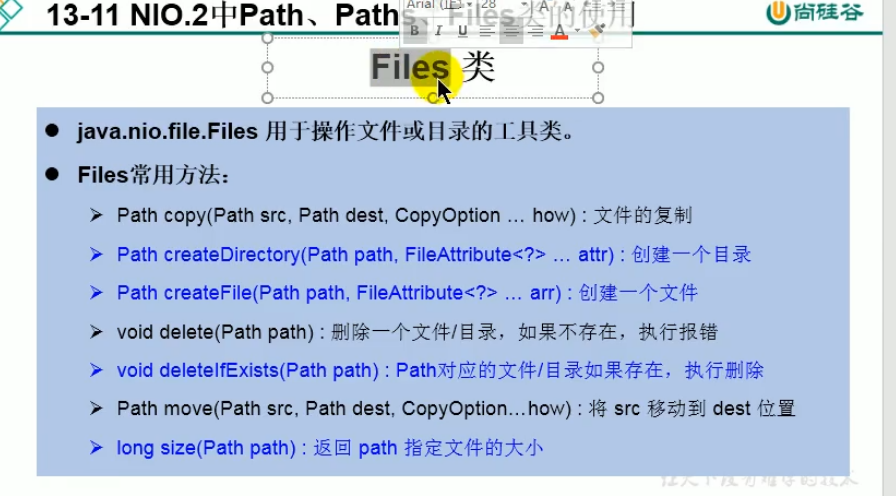

jar
- jar包:第三方提供的额外提供不属于JDK的API
- 这些jar包也都是我们讲的基本API实现的
- 如何导入 看P617 jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号