
预训练模型(四)---Ernie
首先,Ernie是百度搞出来的预训练语言模型,目前分为Ernie1.0和Ernie2.0.
一. Ernie 1.0
Ernie和Bert有什么异同呢?
1.Ernie:通过实体和短语mask能够学习语法和句法信息的语言模型
2.训练方法:与bert类似
3.训练数据集:Bert在中文数据集上只用到了中文维基百科,而Ernie用到了中文维基百科,百度百科(对实体有更好的解释),百度新闻(专业的文本知识),百度贴吧(对话)数据集进行训练。
如何mask?
1.Ernie的输入是字粒度的输入
2.不同级别的mask(单字,实体,短语)
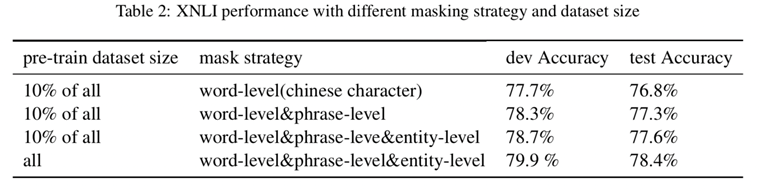
单字级别的mask是跟bert一样,上一篇博客已经讲过,那么如何实现实体和短语级别的mask呢?
大家都知道,百度有它自己的一套分词系统,那些输入的文本在输入之前会进行分词并做好标记,在batching.py中,
seg_labels就是记录分词边界的,有三种取值,0:词首,1:其他,-1:占位
mask_word_tags表示masked word(连续mask) 还是masked char
然后再构造语料时,通过mask_word_tags标志判断是否mask实体,短语还是单字,若是判断为连续mask,则通过seg_labels判断是不是一个单词的词首位置,若为词首则开始连续mask该实体
面试题:怎么理解词源级别的mask比字符级别的好?
BERT 模型主要是聚焦在针对字或者英文word粒度的完形填空学习上面,没有充分利用训练数据当中词法结构,语法结构,以及语义信息去学习建模。比如 “我要买苹果手机”,BERT 模型 将 “我”,“要”, “买”,“苹”, “果”,“手”, “机” 每个字都统一对待,随机mask,丢失了“苹果手机” 是一个很火的名词这一信息,这个是词法信息的缺失。同时 我 + 买 + 名词 是一个非常明显的购物意图的句式,BERT 没有对此类语法结构进行专门的建模,如果预训练的语料中只有“我要买苹果手机”,“我要买华为手机”,哪一天出现了一个新的手机牌子比如栗子手机,而这个手机牌子在预训练的语料当中并不存在,没有基于词法结构以及句法结构的建模,对于这种新出来的词是很难给出一个很好的向量表示的,而ERNIE 通过对训练数据中的词法结构,语法结构,语义信息进行统一建模,极大地增强了通用语义表示能力,在多项任务中均取得了大幅度超越BERT的效果!
其他细节改动:
中文繁体->简体
英文大写->小写
词表大写:17964
对NSP任务的改动:
输入多轮对话修改NSP任务(random replace 构造负样本)
(二) Ernie2.0
2.0的改动就比较大了,首先它采用了多任务持续学习预训练框架,然后构建了三种类型的无监督任务,去训练模型。
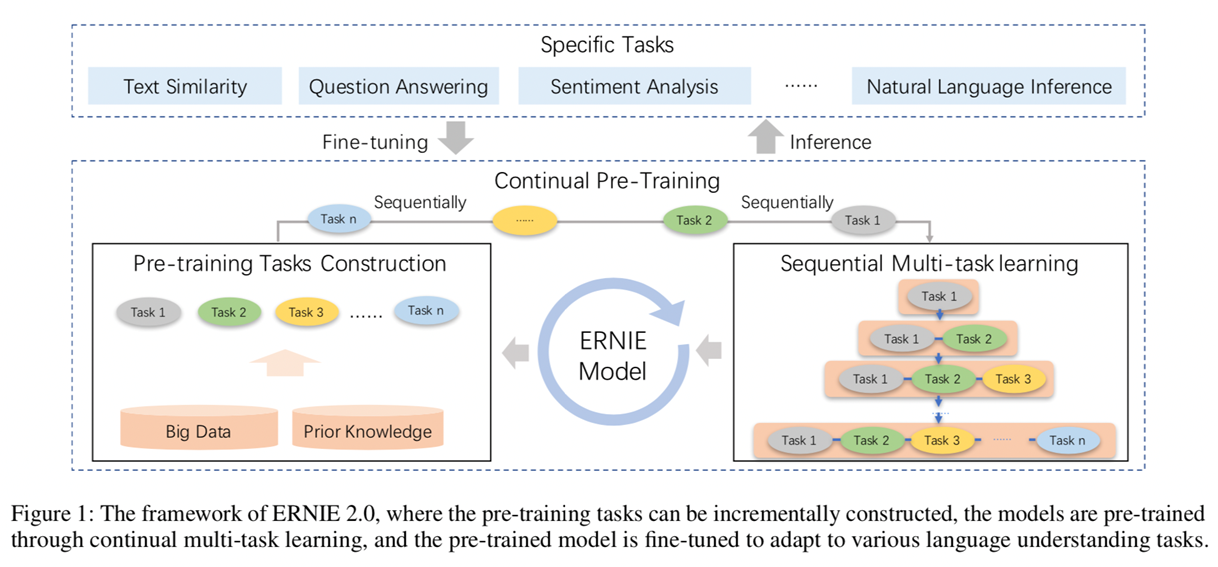
首先看一下2.0的框架图,左边是进行预训练准备的数据和任务(Prior Knowledge是指分词后的信息),然后把任务和数据放进右边持续多任务学习框架中去训练。
为什么用连续多任务学习呢?
先来说一下连续多任务学习的优点:
不遗忘之前的训练结果
多任务高效的进行训练
使用上一任务的参数,并且新旧任务一起训练
将每个任务分成多次迭代,框架完成不同迭代的训练自动分配

再来解释一下啥叫多任务训练?
我们知道无论bert还是ernie,训练的任务无非是两类,句子级别的任务和单词级别的任务,每个任务都有独立的loss function,sentence task 可以和word task一起训练
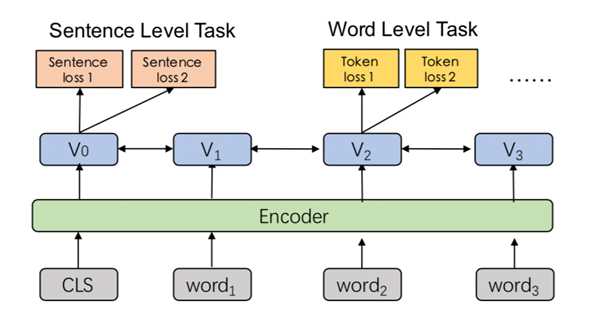
那么,2.0有哪些任务呢?
任务(一):词法级别预训练任务
1.Knowledge Masking Task(ERNIE 1.0):继续沿用1.0的任务,学习当前和全局依赖
2.Capitalization Prediction Task:大写用于专名识别等,小写也可用在其他任务
比如说:Apple(苹果公司),apple(水果),首字母大小写不同
3.Token-Document Relation Prediction Task:token存在段落A中是否token会在文档的段落B中出现
感觉该任务类似于主题提取,关键字提取,TF-IDF
任务(二):语言结构级别预测预训练任务
4.Sentence Reordering Task:文档中的句子打乱(分成1到m段,shuffle),识别正确顺序
感觉该任务类似于判断句子之间短距离依赖关系
5.Sentence Distance Task:句子间的距离,3分类任务
0 相连的句子
1同一文档中不相连的句子
2两篇文档间的句子
感觉该任务类似于判断句子之间长距离依赖关系
任务(二):语法级别预测预训练任务
6.Discourse Relation Task:计算两句间的语义与修辞关系
这个任务没有详细描述,通过一篇英文文章,自己构建了语料,这语句是句间的语义与修辞关系,我感觉是两个语句是否相关,包括人工标注,不过没有细说,只是猜测
7.IR Relevance Task:短文本信息检索关系(百度的核心)
Query-title (搜索数据)
0:搜索并点击
1:搜索并展现(在先验知识中验证相关性)
2:无关,随机替换
这个任务感觉是百度训练后专门为自己的搜索做服务
有了这些任务,2.0怎么进行训练呢?
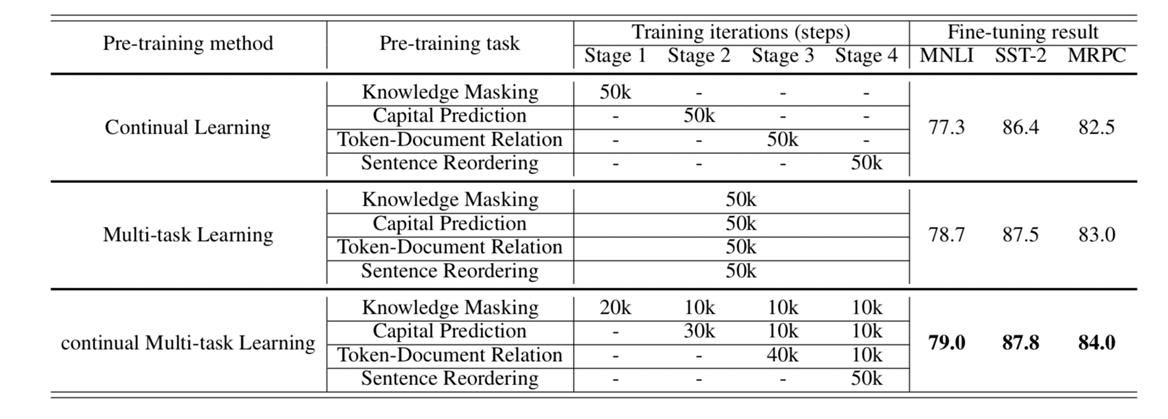
百度对了实验对比,只公布了4个任务上的结果,发现多任务学习比持续学习更好,而连续多任务学习比多任务学习更好,其实连续多任务学习就是对steps级别上的切分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号