

爬虫&逆向--Day05--综合实战
""" 目标网站:https://ks.wangxiao.cn/ 爬取目标: - 将所有的一级标题进行爬取 - 将一级标题对应的二级标题进行爬取 - 进入到二级标题对应子页面的【每日一练】选项页面中 - 将每日一练对应的练习题进行数据爬取 - 注意:在登录页面进行微信扫码登录后,该网站可能没有及时刷新出登录成功后的页面,依然停留在扫码登录的页面中。我们 只需要重新打开一个页面,访问该网站的目标url:https://ks.wangxiao.cn/。即可显示登录成功! 需求分析: - 进行一级标题和二级标题数据爬取,我们确认了这些标题数据不是动态加载的。因此,就可以直接在浏览器开发者工具中的Elements 中进行页面布局结构的查看。 - 成功解析出了一级标题和其对应所有的二级标题和二级标题对应的详情页的url - 注意:二级标题对应详情页的url,对其请求后,默认是显示【模拟考试】这个子版块中。我们想要进入的是【每日一练】这个板块。 - 观察:模拟考试的url:https://ks.wangxiao.cn/TestPaper/list?sign=jzs1 - 观察:每日一练的url:https://ks.wangxiao.cn/practice/listEveryday?sign=jzs1 - 观察结果:每一个一级标题对应二级标题的每日一练板块的链接中sign这个参数值都是不一样的。该链接sign的参数值和二级标题 详情页链接中的sign值是一样的。因此,我们就可以单独将所有二级标题对应详情页链接中的sign值提取出来,作用在每一个【每日一练】url中即可!
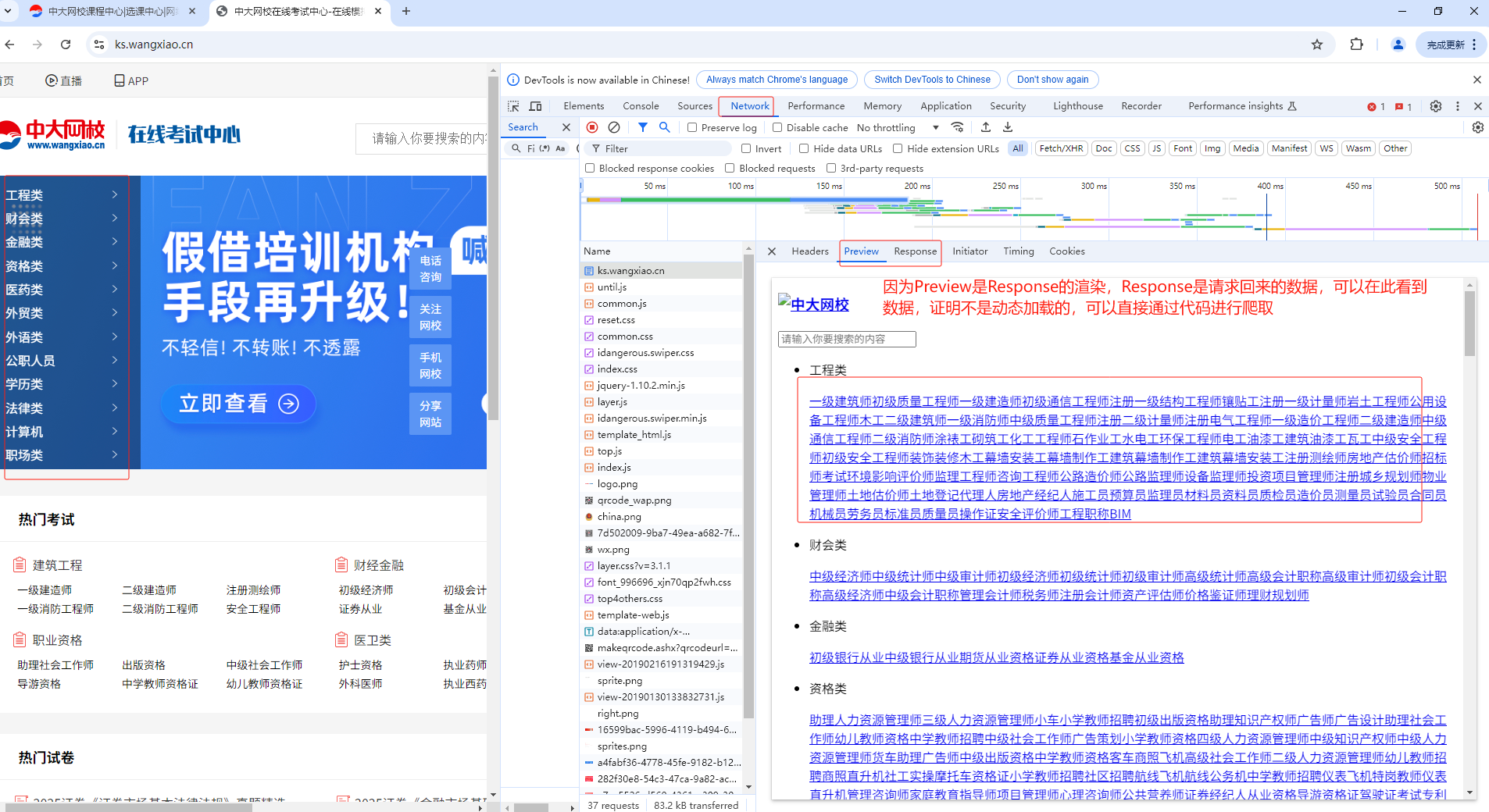
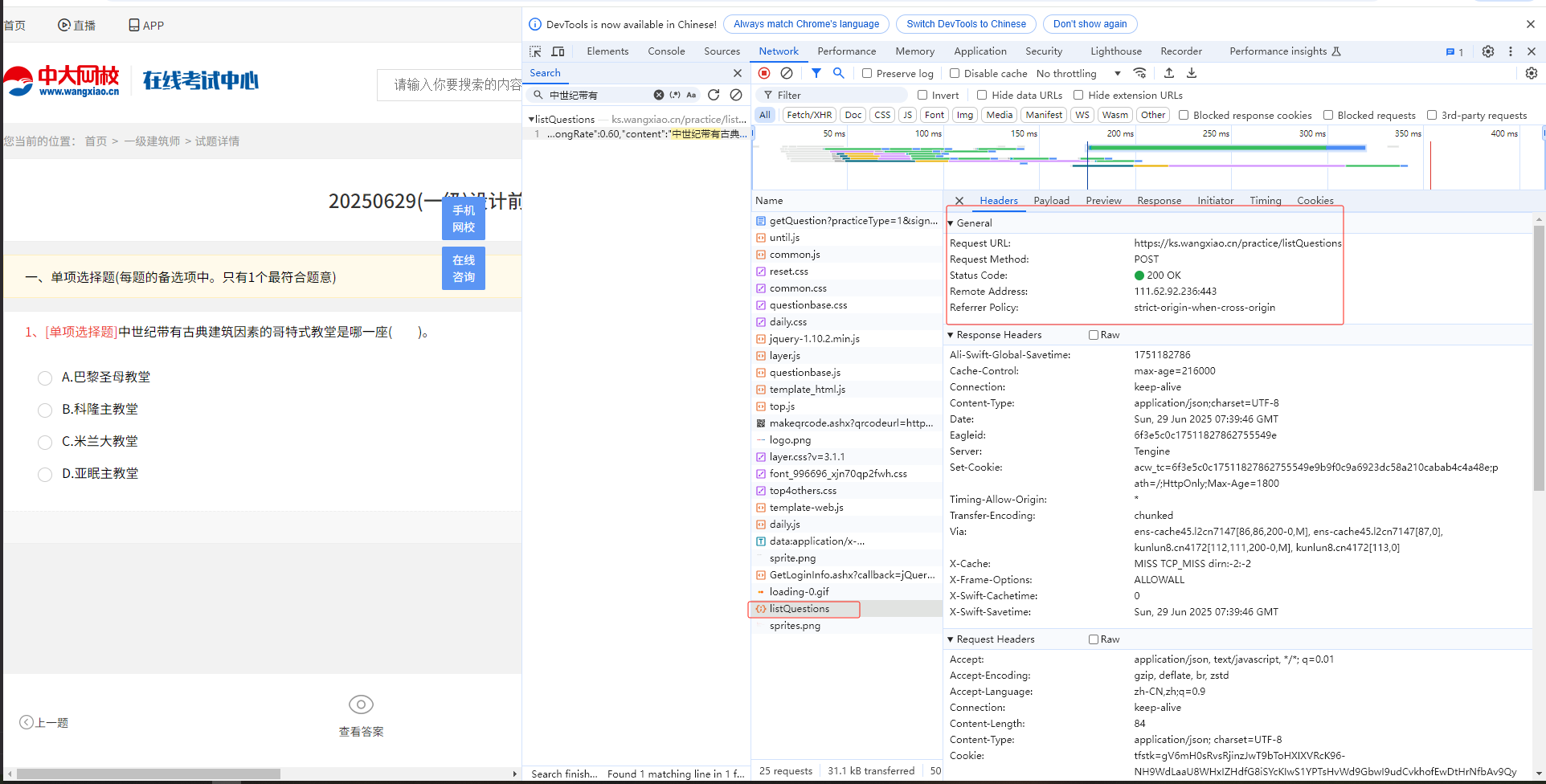
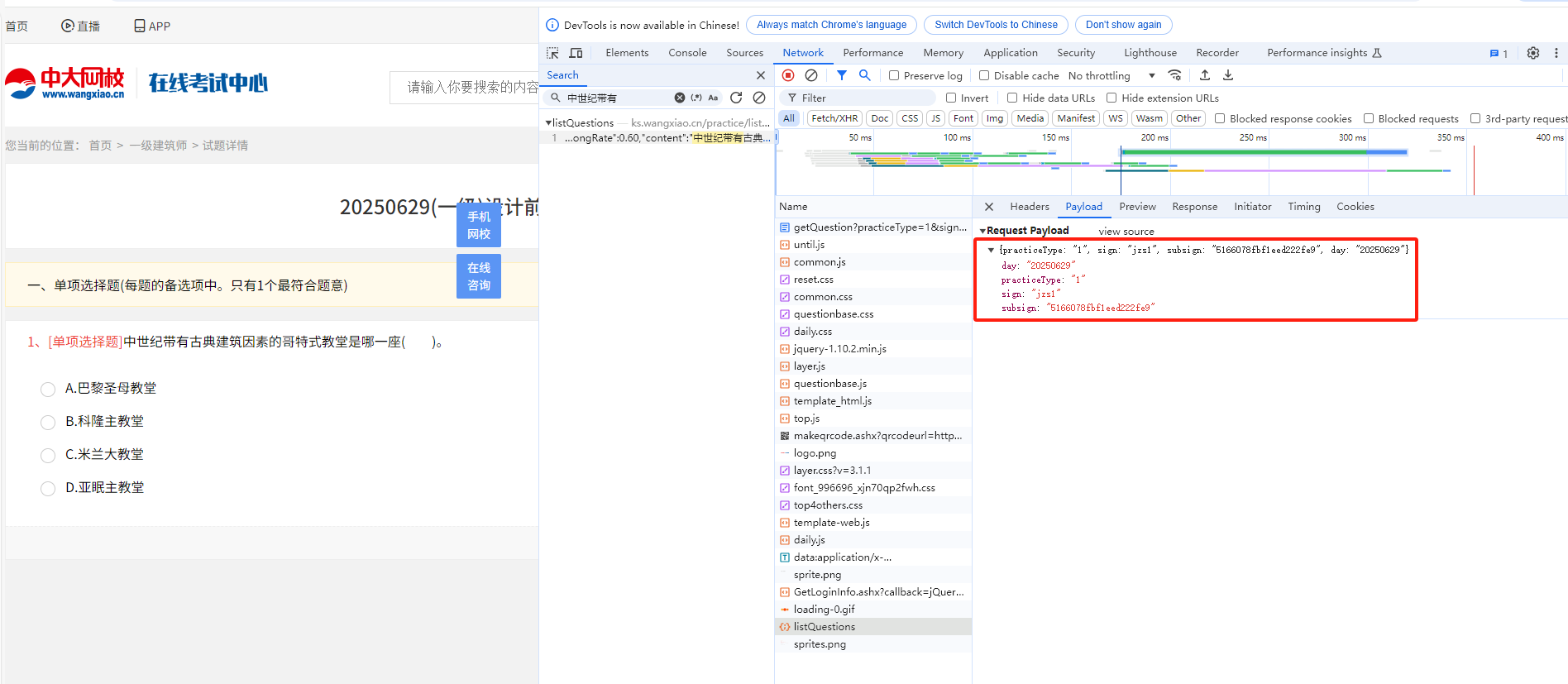
- 已经可以成功获取所有二级标题详情页中【每日一练】的完整链接 - 可以点击【开始做题】进行对应题目的爬取 - 当点击【开始做题】页面跳转,需要我们进行登录,因此我们可以进行登录实现 - 注意:当扫码登录后,页面依然停留在了登录页面,我们就可以从新打开一个新页面访问当前网站目标url,就是登录状态了。 - 分析:登录后,发生了什么?登录成功后,你再次进行页面跳转等操作都是出于登录状态。我们进行登录后,服务器给客户端 创建了cookie实现登录状态的保持。因此,我们就需要注意,获取cookie作用在headers中。 - 分析点击【开始做题】: - 通过抓包工具分析发现,我们的试题是动态加载出来的,并不是点击【开始做题】这个链接请求后产生的! - 定位到试题内容对应的数据包,发现该数据包的请求参数中sign和subsign的值是动态变化的: - 上述两个动态变化的请求参数其实和【每日一练】连接中对应的参数值是一致的,因此我们就可以对【每日一练】页面中 所有的【开始做题】对应的url进行解析,提取出其中的sign和subsign。 - 可以对题目的数据包进行请求,解析json数据即可完成 Preview就是对返回数据Response请求到的html标清数据进行的可视化渲染 如果在Preview和Response中都没找到界面上显示的题目,因此就可以认为界面上显示的题目是动态加载出来的 并不是点击了页面上的【开始做题】刷出来的 """ import requests import json from lxml import etree from time import sleep fp = open("data.txt", 'w', encoding='utf-8') headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36", "cookie":"tfstk=gV6mH0sRvsRjinzJwT9bToHXIXVRcK96-NH9WdLaaU8WHxIZHdfG8iSYcKIwS1YPTsHvWd9GbwI9udCvkhofEwDtHrNfbAv9QyULpJIjcd9aJFtngVuXxhHaBC-q4KtTzJkeMJIfc0om7kCzpcjiMVv27NR2U8-6zx8N7I-zqh-tufkV7uqkAh320h8aU0-6jd8N7drl4UtMQn7wQbI8gE6NUTz85MsUAOCfEnAD8gVIQADk02Lh0zDiQTfkiekMrAkNEnjGL44oK5LFOEdp5ay-ndjyjaAdiyDcSGSC_QXiuoQFj_b6HTrZge5AkCBXZql2xKYDTtRqmxJW__XkHtzsOgIkuBvRw7av6KbcOeO4Nz_GqEQNnQu0yFCd2tRl8zHl5CfNHLW4zJjzUblU_MH64lBr1fO2V3YLHT9QPtGiRnruqXr6g3tXJuqo1fO2V3YLqucUtI-WceC..; safedog-flow-item=; UserCookieName=pc_269509205; OldUsername2=juKqHC1IJVEOyfAFEGqAXA%3D%3D; OldUsername=juKqHC1IJVEOyfAFEGqAXA%3D%3D; UserCookieName_=pc_269509205; OldUsername2_=juKqHC1IJVEOyfAFEGqAXA%3D%3D; OldUsername_=juKqHC1IJVEOyfAFEGqAXA%3D%3D; userInfo=%7B%22userName%22%3A%22pc_269509205%22%2C%22token%22%3A%229011ec25-7a54-4f2c-947c-810809e61d82%22%2C%22headImg%22%3Anull%2C%22nickName%22%3A%22183****5683%22%2C%22sign%22%3A%22fangchan%22%2C%22isBindingMobile%22%3A%221%22%2C%22isSubPa%22%3A%220%22%2C%22userNameCookies%22%3A%22juKqHC1IJVEOyfAFEGqAXA%3D%3D%22%2C%22passwordCookies%22%3A%22Zjaf4MyWoxw%3D%22%7D; token=9011ec25-7a54-4f2c-947c-810809e61d82; OldPassword=Zjaf4MyWoxw%3D; OldPassword_=Zjaf4MyWoxw%3D; pc_269509205_exam=fangchan; mantis6894=61e86cd2fbb44f1db81ee2378dca8ae8@6894; register-sign=jz1; sign=jz1" } main_url = 'https://ks.wangxiao.cn' # 对主页进行网络请求,获取主页的页面源码数据 main_page_text = requests.get(url=main_url, headers=headers).text # 对主页页面进行数据解析,获取一级标题 tree = etree.HTML(main_page_text) # li_list = tree.xpath('//*[@id="banner"]/div[2]/ul/li') # 该网站使用Copy --> Copy XPath 获取不到标签,需要手写xpath函数 li_list = tree.xpath('//ul[@class="first-title"]/li') # 遍历一级标题所在的li_list列表 for li in li_list: # 解析一级标题 c1_title = li.xpath('./p/span/text()')[0] # print(c1_title) # 解析二级标题 a_list = li.xpath('./div/a') for a in a_list: # 获取二级标题 c2_title = a.xpath('./text()')[0] # 获取二级标题对应的url https://ks.wangxiao.cn/TestPaper/list?sign=jzs1 # c2_url = "https://ks.wangxiao.cn" + a.xpath('./@href')[0] # /TestPaper/list?sign=jzs1 c2_url = main_url + a.xpath('./@href')[0] # print(c2_title, c2_url) # 一级建筑师 https://ks.wangxiao.cn/TestPaper/list?sign=jzs1 # 可见************【分析思路一】************ # 提取c2_url中的sign的值 sign = c2_url.split('?')[1] # print("sign:", sign) # sign: sign=jzs1 # 结合sign的值动态拼接生成【每日一练】的完整链接 c2_day_url = 'https://ks.wangxiao.cn/practice/listEveryday?' + sign # print("c2_day_url:", c2_day_url) # c2_day_url: https://ks.wangxiao.cn/practice/listEveryday?sign=jzs1 # 获取【每日一练】对应的页面源码数据 detail_page_text = requests.get(url=c2_day_url, headers=headers).text # 解析出每一个【开始做题】的链接 detail_tree = etree.HTML(detail_page_text) div_list = detail_tree.xpath('//div[@class="test-panel"]/div') for div in div_list: day_url = div.xpath('./ul/li[4]/a/@href')[0] # print("day_url:", day_url) # /practice/getQuestion? practiceType=1 &sign=jzs1 &subsign=5166078fbf1eed222fe9 &day=20250629 # ************【分析思路二】************ # 切割爬取的url,获取四个参数 ret = day_url.split('?')[1].split("&") sign = ret[1].split('=')[1] # sign=jzs1 subsign = ret[2].split("=")[1] # print(sign,subsign) # 对试题表示的动态加载数据对应的数据包进行请求发送 post_url = 'https://ks.wangxiao.cn/practice/listQuestions' data = { "practiceType": "1", "sign": sign, "subsign": subsign, "day": "20250621" } # 请求到了所有的试题对应的json结果 sleep(1) # post请求,返回的形式是json字符串, content = requests.post(url=post_url, headers=headers, json=data).json() for option in content["Data"][0]["questions"]: # 题目 title = option['content'] right_anser_list = [] # 存储每一个选项是否为正确答案的标识(0,1组成) opt_list = [] # 存储4个选项内容 # 获取题目选项答案 for opt in option["options"]: # 选项内容 opt_content = opt['content'] opt_list.append(opt_content) # 1表示正确答案,0表示错误答案 anser = opt["isRight"] right_anser_list.append(anser) dic = { 0: "A", 1: "B", 2: "C", 3: "D" } right_index = right_anser_list.index(1) # 获取数据为1的下标 # 获取正确答案的选项 right_anwser = dic[right_index] fp.write(title + "\n" + json.dumps(opt_list, ensure_ascii=False) + '\t' + right_anwser + '\n\n') print(title, "--爬取保存成功!") break # 只获取一级标题中的第一个二级标题 【一级建筑师】 break # 只获取一级标题中的第一个 【工程类】 fp.close() """ ************【分析思路一】************ 分析对比:获取的【模拟考试--url】和【每日一练--url】的区别 【模拟考试--url】:https://ks.wangxiao.cn/TestPaper/list?sign=jzs1 【每日一练--url】:https://ks.wangxiao.cn/practice/listEveryday?sign=jzs1 由此可以看出一级标题下的二级标题中的模拟考试和每日一天中的区别点就是 1、?前面的地址链接不一样 2、?后面的sign=jzs1字段是一样的,所以我们可以从获取的【模拟考试--url】获取【每日一练--url】需要的sign=jzs1 3、通过对比可知,每一个一级标题和二级标题中的【每日一练--url】除了后面的sign=jzs1不一样以外,其他都是一样的 【每日一练-一级建筑师】:https://ks.wangxiao.cn/practice/listEveryday?sign=jzs1 【每日一练-中级经济师】:https://ks.wangxiao.cn/practice/listEveryday?sign=zjjs """ """ ************【分析思路二】************ 通过爬取数据的结果分析获取到的每个【开始做题】下面的链接如下 /practice/getQuestion?practiceType=1&sign=jzs1&subsign=5166078fbf1eed222fe9&day=20250629 但是当点击【开始做题】跳转的界面,可以获取到的题目所在的接口如下 https://ks.wangxiao.cn/practice/listQuestions post请求 并且需要四个参数 {practiceType: "1", sign: "jzs1", subsign: "5166078fbf1eed222fe9", day: "20250629"} 刚好需要的四个参数,都可以从爬取的每一个【开始做题】按钮的数据分析中获得 """
图例一:
图例二:

图例三:

图例四:

图例五:

图例六:

图例七:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号