
第一次个人编程作业
一.Github链接:https://github.com/iFortheFuture/software/tree/main/3122004776
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024/homework/13136 |
| 这个作业的目的 | 学习使用Github和了解完整的软件开发测试流程以及使用Markdown语言 |
二.PSP表格## Personal Software Process Stages
| Personal Software Process Stages | 预估时间 (分钟) | 实际时间 (分钟) |
|---|---|---|
| Planning | 30 | 35 |
| Estimate | 45 | 40 |
| Development | 120 | 125 |
| Analysis | 60 | 55 |
| Design Spec | 90 | 85 |
| Design Review | 45 | 50 |
| Coding Standard | 30 | 35 |
| Design | 120 | 130 |
| Coding | 180 | 175 |
| Code Review | 60 | 65 |
| Test | 90 | 95 |
| Reporting | 45 | 40 |
| Test Report | 30 | 35 |
| Size Measurement | 60 | 55 |
| Postmortem | 60 | 65 |
| 合计 | 1135 | 1145 |
三.计算模块接口的设计与实现过程:
1.两个类,分别是
FileManager 类:
这个类负责处理文件的读取和写入操作。
它包含成员函数来打开原文文件、抄袭版文件和输出文件,以及关闭这些文件。
FileManager 类还应该提供方法来获取文件中的文本内容,并将结果写入输出文件。
TextProcessor 类:
这个类负责文本的清洗和相似度计算。
它包含一个成员函数来清洗文本,去除标点符号和转换为小写。
另一个成员函数用于计算原文和抄袭版之间的相似度,关键是统计两个文本中相同单词的数量,并将其与总单词数相除。
2.关于算法的关键和独到之处:
清洗文本:清洗文本是算法的关键步骤之一。通过去除标点符号和将文本转换为小写,我们可以确保文本在比较时不会因为大小写或标点符号的不同而产生误差。
相似度计算:相似度计算是另一个关键步骤。我们可以将文本分割成单词,并比较这些单词在原文和抄袭版中的出现情况。通过统计相同单词的数量并将其与总单词数相除,我们可以得到相似度的百分比。
文件管理:有效地管理文件的读取和写入是算法的另一个关键点。我们需要确保文件能够成功打开,并且在写入结果时不会出现错误。
3.关键函数的流程图:
附录
4.计算模块接口部分的性能改进: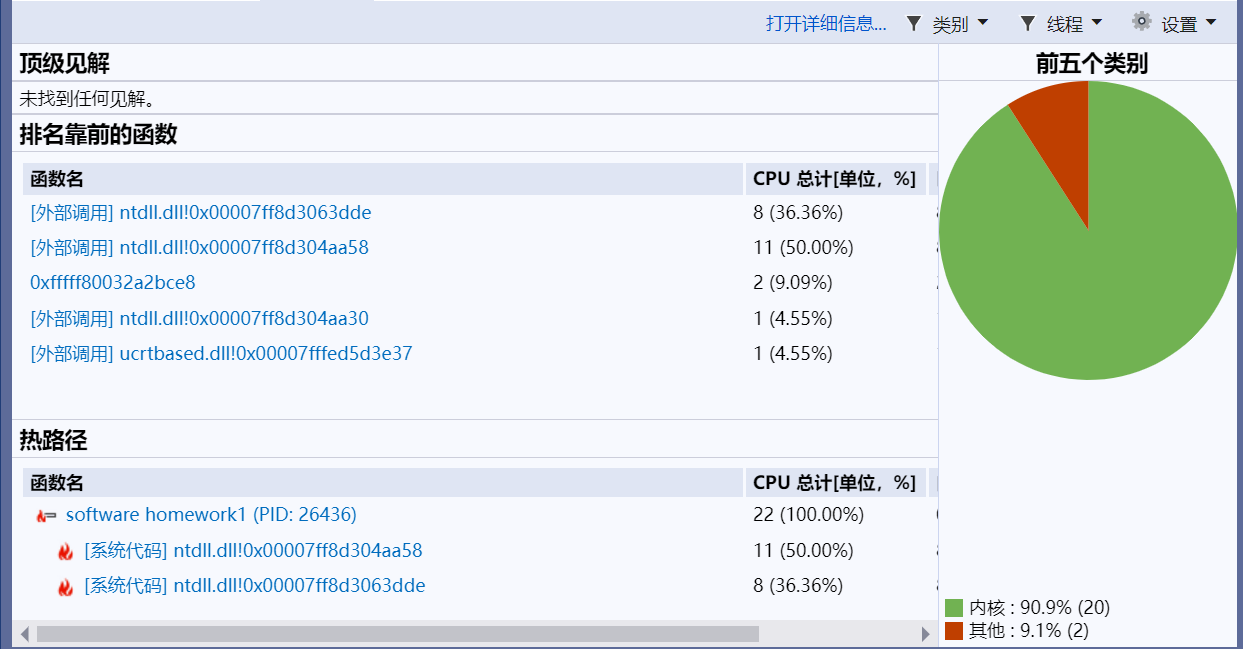

5.计算模块部分单元测试展示:
include <gtest/gtest.h> //使用 Google Test 框架
include "FileManager.h"//假设这里是你的 FileManager 类的头文件
include "TextProcessor.h"//假设这里是你的 TextProcessor 类的头文件
//测试清洗文本功能
TEST(TextProcessorTest, CleanTextTest){
string dirtyText = "This is some !@#$ text.";
string cleanText = TextProcessor::cleanText(dirtyText);
ASSERT_EQ(cleanText, "this is some text");
}
//测试计算相似度功能
TEST(TextProcessorTest, CalculateSimilarityTest){
string originalText = "This is the original text.";
string plagiarizedText = "This is the plagiarized text.";
double similarity = TextProcessor::calculateSimilarity(originalText, plagiarizedText);
ASSERT_NEAR(similarity,100.0,0.01);//期望相似度接近100%
}
//测试文件读写功能
TEST(FileManagerTest, ReadWriteFileTest) {
FileManager fileManager("org.txt", "addorg.txt", "ans.txt");
ASSERT_TRUE(fileManager.isOpen());//确保文件打开成功
ifstream& originalFile = fileManager.getOriginalFile();
ASSERT_TRUE(originalFile.good()); // 确保原文文件可读
//读取原文文件内容
string originalText((istreambuf_iterator<char>(originalFile)), istreambuf_iterator<char>());
ASSERT_FALSE(originalText.empty());//确保原文文件非空
//读取抄袭版文件内容
ifstream& plagiarizedFile = fileManager.getPlagiarizedFile();
ASSERT_TRUE(plagiarizedFile.good());//确保抄袭版文件可读
string plagiarizedText((istreambuf_iterator<char>(plagiarizedFile)), istreambuf_iterator<char>());
ASSERT_FALSE(plagiarizedText.empty());//确保抄袭版文件非空
//测试相似度计算并写入文件
ofstream& outputFile = fileManager.getOutputFile();
ASSERT_TRUE(outputFile.good());//确保输出文件可写
double similarity = TextProcessor::calculateSimilarity(originalText, plagiarizedText);
outputFile << fixed << setprecision(2) << similarity;
}
//运行所有测试
int main(int argc, char **argv){
testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}
这个代码包括了针对 TextProcessor 类和 FileManager 类的单元测。
在上面的代码中,我对两个主要功能进行了测试:文本清洗和相似度计算,以及文件的读写功能。
(1).文本清洗功能测试(TextProcessorTest::CleanTextTest):
测试函数:TextProcessor::cleanText
构造测试数据的思路:准备包含各种标点符号、空格和大小写字母的脏文本,期望通过文本清洗后得到只包含小写字母和空格的干净文本。在测试用例中,我们使用了一段包含各种标点符号的脏文本,并期望清洗后只包含小写字母和空格。
(2).相似度计算功能测试(TextProcessorTest::CalculateSimilarityTest):
-测试函数:TextProcessor::calculateSimilarity
构造测试数据的思路:准备一对原文和抄袭版文本,期望通过相似度计算后得到一个合理的相似度百分比。在测试用例中,我们准备了一对包含相同内容的原文和抄袭版文本,并期望计算出的相似度接近100%。
(3). 文件读写功能测试(FileManagerTest::ReadWriteFileTest):
测试函数:FileManager 类的构造函数和成员函数 getOriginalFile, getPlagiarizedFile, getOutputFile
构造测试数据的思路:准备一对原文和抄袭版文本文件,并期望通过文件读取操作能够成功读取文件内容,以及通过文件写入操作能够将计算出的相似度百分比正确地写入到输出文件中。在测试用例中,我们使用了预先准备的原文和抄袭版文本文件,并期望通过文件读取和写入操作得到正确的结果。
附录:

