
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | <完成个人项目:设计一个论文查重算法> |
一、Github链接
https://github.com/zhiyou-gift/zhiyou/tree/main
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 120 | 150 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 需求分析 (包括学习新技术) | 30 | 20 |
| Design | 具体设计 | 60 | 60 |
| Coding | · 具体编码 | 180 | 150 |
| · Code Review | · 代码复审 | 20 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 610 | 730 |
三、需求分析
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
-
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
-
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下: -
从命令行参数给出:论文原文的文件的绝对路径。
-
从命令行参数给出:抄袭版论文的文件的绝对路径。
-
从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
四、模块接口的设计与实现过程
模块和函数:
导入了 os, difflib, cProfile, pstats, 和 io 模块。
定义了4个主要函数:
read_file(filepath): 读取文件内容。
calculate_similarity(text1, text2): 计算两个文本的相似度。
compare_files(directory, reference_text, reference_filepath, file_extension=".txt"): 比较目录中的文件与参考文本的相似度。
main(directory, reference_file): 主函数,读取参考文件并调用比较函数。
函数间关系:
main 函数调用 read_file 以读取参考文件,并调用 compare_files 比较其他文件的相似度。
compare_files 内部调用 read_file 和 calculate_similarity 来获取文件内容并计算相似度。
性能分析:
使用 cProfile 进行性能分析,运行 main 函数,并利用 pstats 和 io.StringIO 打印性能分析结果,过滤出特定函数的统计信息。
独到之处:
difflib 的 SequenceMatcher 提供了一个高效的文本相似度计算方式,可以直接比较两个文本之间的相似度。这种方法适用于比较文本内容的相似度,而不仅仅是简单的字符串匹配或替换。这种方法对于检测文本的相似性非常有效,尤其是在处理有少量变化的文本时。
流程图:
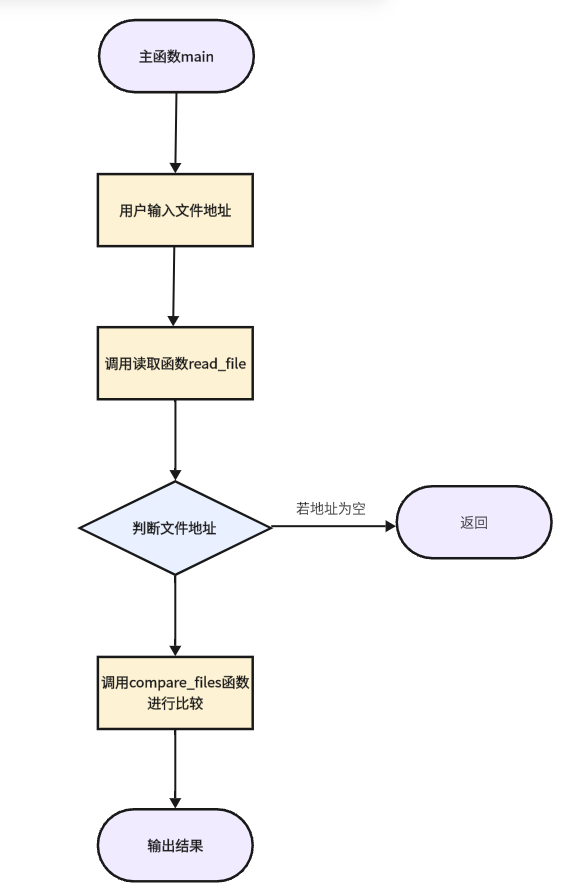
五、模块接口部分的性能改进
使用PyCharm提供了代码静态审查功能,消除了代码的所有警告
使用cProfile模块对代码进行分析,cProfile是Python自带的性能分析模块,所以直接import导入即可。
cProfile用法:
同时对分析的函数进行筛选仅保留主文件中的函数,结果如下:
由于main函数是作为入口所以可以忽略不计,可以发现是calculate_similarity函数占用了最多时间,但是SequenceMatcher作为difflib模块中的方法,暂时没有想到有什么办法再进行进一步的优化,在最终敲定difflib模块前曾尝试使用sklearn模块进行文件对比,但是结果十分不理想,所以选定SequenceMatcher方法。
六、模块部分单元测试展示
源代码:
点击查看代码
import unittest
import os
from unittest.mock import mock_open, patch, MagicMock
from Difflib import read_file, calculate_similarity, compare_files # 确保正确导入你的模块
class TestFileSimilarity(unittest.TestCase):
def setUp(self):
# 设置参考文件和目录的路径
self.directory = "D:\\作业\\软件工程\\zhiyou\\3121002717\\测试文本"
self.reference_file = "D:\\作业\\软件工程\\zhiyou\\3121002717\\测试文本\\orig.txt"
self.reference_content = "你好,世界"
def test_read_file_success(self):
# 创建一个模拟的open对象,里面有指定的内容
m = mock_open(read_data='data')
# 使用模拟对象替代'open'
with patch('builtins.open', m):
# 调用你的函数来读取文件
result = read_file('filename.txt')
# 进行断言或检查结果
self.assertEqual(result, 'data')
def test_read_file_failure(self):
# 模拟文件读取失败
with patch('builtins.open', side_effect=Exception("File not found")):
content = read_file('nonexistent.txt')
self.assertIsNone(content)
def test_calculate_similarity_exact(self):
# 测试完全相同的文本
self.assertEqual(calculate_similarity("你好", "你好"), 1.0)
def test_calculate_similarity_none(self):
# 测试完全不同的文本
self.assertEqual(calculate_similarity("你好", "世界"), 0.0)
def test_compare_files(self):
directory = 'dummy_directory'
reference_text = 'Hello world!'
reference_filepath = os.path.join(directory, 'reference.txt')
files = ['file1.txt', 'file2.txt', 'reference.txt']
# 使用 mock 模拟文件系统操作和 difflib 库的行为
with patch('os.listdir', return_value=files), \
patch('os.path.join', side_effect=lambda x, y: os.path.join(x, y)), \
patch('os.path.isfile', return_value=True), \
patch('builtins.open', mock_open(read_data='Hello world! Different words here')):
results = list(compare_files(directory, reference_text, reference_filepath, '.txt'))
# 假设所有文件都与参考文本有相同程度的相似度(由于difflib计算)
expected_results = [('file1.txt', 0.9230769230769231), ('file2.txt', 0.9230769230769231)]
self.assertEqual(len(results), len(expected_results))
for result, expected in zip(results, expected_results):
self.assertEqual(result[0], expected[0])
self.assertAlmostEqual(result[1], expected[1], places=4)
if __name__ == '__main__':
unittest.main()
测试结果:
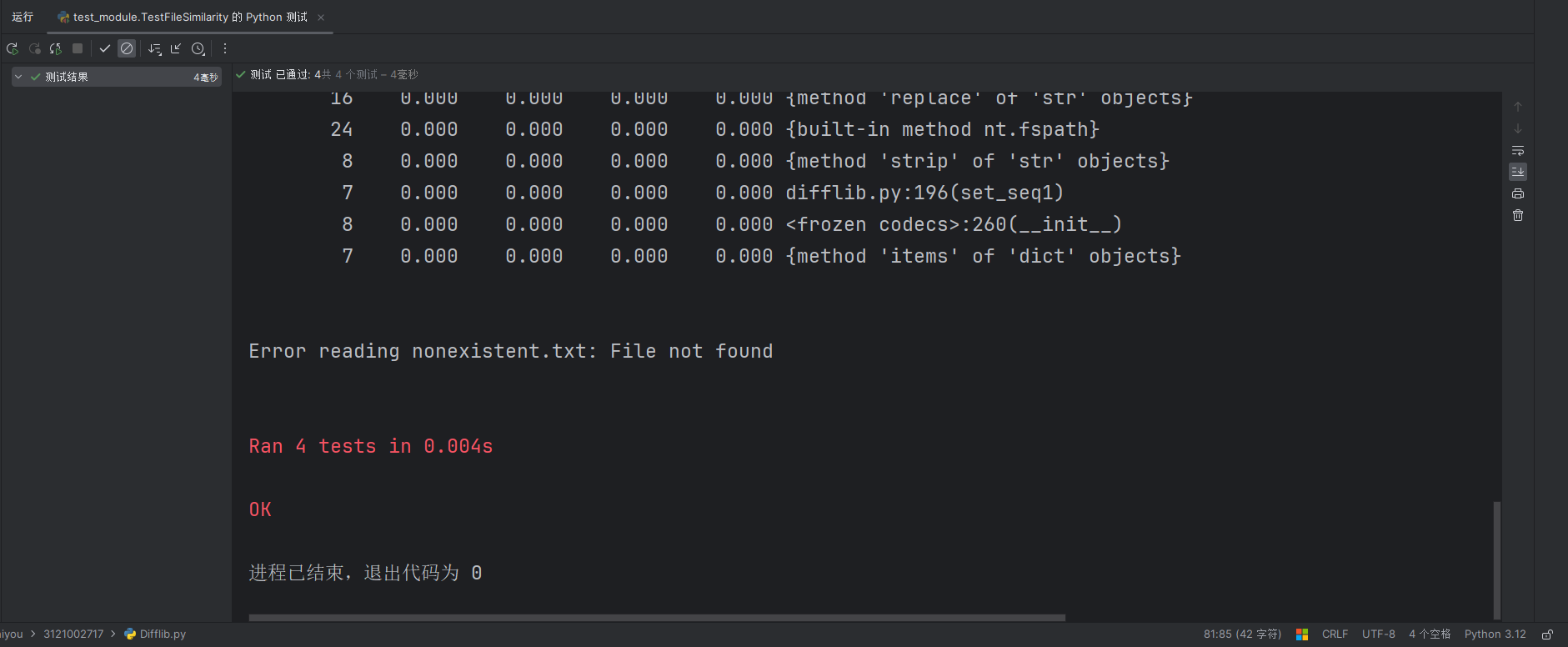
四个模块均通过单元测试,目前没有发现明显漏洞
七、模块部分异常处理说明
1. 读取文件的异常处理
设计目标
确保函数能够优雅地处理文件读取时可能发生的错误,如文件不存在或权限问题。
单元测试样例
点击查看代码
def test_read_file_failure(self):
# 模拟文件读取失败
with patch('builtins.open', side_effect=Exception("File not found")):
content = read_file('nonexistent.txt')
self.assertIsNone(content)
对应的错误场景
尝试读取一个不存在的文件时,系统应当能够处理这种异常,返回一个预期的响应(例如None或错误信息),而不是让程序崩溃。
2. 计算文本相似度的异常处理
设计目标
确保相似度计算逻辑在面对任何文本输入时都能返回准确的结果,包括完全相同或完全不同的情况。
单元测试样例
点击查看代码
def test_calculate_similarity_none(self):
# 测试完全不同的文本
self.assertEqual(calculate_similarity("你好", "世界"), 0.0)
对应的错误场景
测试两段完全不相关的文本时,相似度计算应正确返回0.0,表示没有相似度。
3. 比较文件夹中文件的异常处理
设计目标
确保能够处理文件夹读取和文件比较的各种情况,包括空文件夹、文件读取权限问题等。
单元测试样例
点击查看代码
def test_compare_files(self):
directory = 'dummy_directory'
reference_text = 'Hello world!'
reference_filepath = os.path.join(directory, 'reference.txt')
files = ['file1.txt', 'file2.txt', 'reference.txt']
# 使用 mock 模拟文件系统操作和 difflib 库的行为
with patch('os.listdir', return_value=files), \
patch('os.path.join', side_effect=lambda x, y: os.path.join(x, y)), \
patch('os.path.isfile', return_value=True), \
patch('builtins.open', mock_open(read_data='Hello world! Different words here')):
results = list(compare_files(directory, reference_text, reference_filepath, '.txt'))
# 假设所有文件都与参考文本有相同程度的相似度(由于difflib计算)
expected_results = [('file1.txt', 0.9230769230769231), ('file2.txt', 0.9230769230769231)]
self.assertEqual(len(results), len(expected_results))
for result, expected in zip(results, expected_results):
self.assertEqual(result[0], expected[0])
self.assertAlmostEqual(result[1], expected[1], places=4)
对应的错误场景
在这个测试案例中,模拟了一个完整的文件比较场景,包括模拟文件系统和文件内容。这个测试验证了在一组预设条件下,文件比较逻辑能否正确执行并返回预期的相似度结果。这可以帮助确保比较逻辑在实际运用中对各种文件状态具备正确的响应能力。
八、个人总结
从前写代码从来不会详细的分析需求,更多的是给出要求后脑子里想什么就写什么,不对总体进行规划,也没有使用GitHub等工具对代码进行git,就出现了当一段时间没有接触这个项目时,会导致忘记之前干了什么,做到哪一步,还有哪些代码需要改进能使性能更上一步。在熟悉GitHub之后可以对代码进行阶段性的存储,每次迭代也能有所记录,更好的想起来之前是怎么改进的代码,有规划之后也使得任务进行的顺利许多,不会出现想一出是一出的情况。
总之,这一次个人项目经历让我认识到了项目开发的各个流程需要的时间和复杂度,更好的安排自己的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号