
联邦学习论文阅读笔记10 面向联邦学习激励优化的演化博弈模型_孙跃杰
面对的问题: 参与者虚报成本导致激励分配不匹配
提出了:质量评估方法、基于信誉度的激励分配方法、计算了演化博弈模型达到均衡的解。
本文模型:
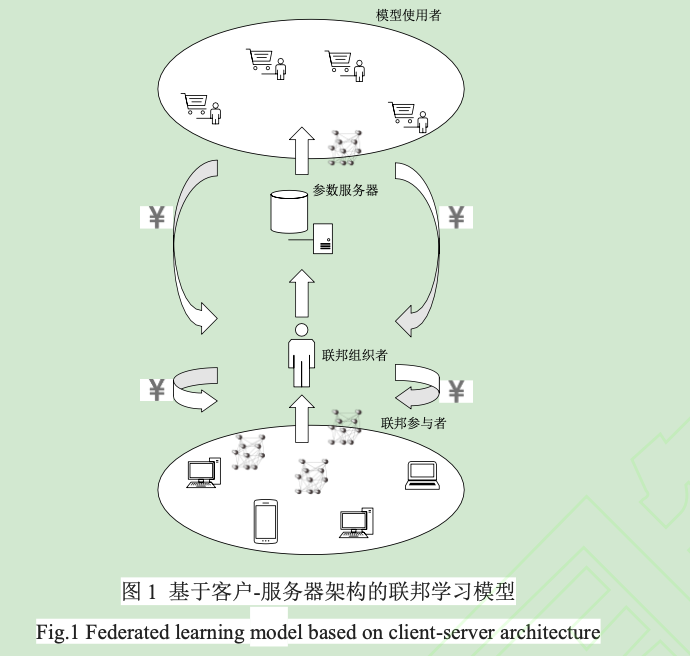
质量评估:不是参与者绝对主导,由参与者与组织者共同决定质量评估结果,参与者可主导的指标:准确度、精确度、召回率。做归一化处理;组织者根据模型使用者需求给指标设置对应权重。
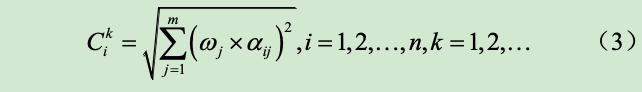
信誉度计算:初始设为1,有一轮虚报成本都会下降,下降幅度与本轮自身虚报量占本轮总体虚报量的比例有关

激励分配:基于信誉度分配,划分诚实参与者和虚报参与者,诚实参与者是信誉度是1,不是1的都是虚报参与者。分两轮分配,第一轮所有人都参与,按上报训练成本占总成本比例分配激励;第二轮先将虚报参与者虚报部分根据信誉度扣除
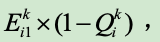 然后将得到的扣除总和对诚实参与者按其成本占总诚实参与者成本占比进行二次分配。最终分配结果如下:
然后将得到的扣除总和对诚实参与者按其成本占总诚实参与者成本占比进行二次分配。最终分配结果如下:
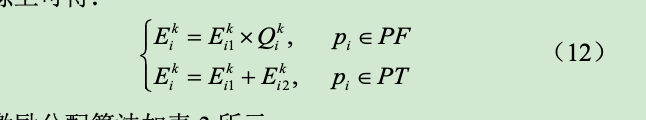
演化博弈模型的理解: 论文设计二元的演化博弈均衡求解,水平有限,📌标记以后补上
给出一般演化博弈均衡解求解过程:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号