

os模块 序列化模块


import os print(os.listdir()) #如果不输入,则输出当前文件下的所有文件 展示结果: ['2016-01-02.log', '2016-01-03.log', 'a.txt', 'al.txt', 'all', 'alll', 'bmi.py', 'dir3', 'evreyday.log', 'file-副本', 'hello', 'lxl', 'lxl.html', 'lxl.txt', 'student_msg', 'student_msg.txt', 't1.txt', '作业总结.py', '你好', '刘.log', '刘晓蕾1.py', '刘晓蕾10.py', '刘晓蕾11.py', '刘晓蕾13.py', '刘晓蕾15.py', '刘晓蕾17.py', '刘晓蕾2.py', '刘晓蕾3.py', '刘晓蕾4.py', '刘晓蕾5.py', '刘晓蕾6.py', '刘晓蕾7.py', '刘晓蕾8.py', '呵呵', '哈哈', '哈哈.html', '第二周大作业.py', '考试题.py', '课上代码.py', '购物车.py', '麻.log']
本节内容:
1.os模块
2.练习题
3.sys模块
4.练习题
5.序列化模块
6.练习题
一os.模块:和操作系统的一个接口(dir 文件夹名)
(1)os.makedirs('dirname1/dirname2')
可生成多层递归目录,只能新建文件夹,不能在原有文件下创建新的文件
import os os.makedirs('dir/dir2/dir3')
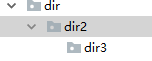
(2)os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.removedirs('dir/dir2/dir3')
(3)os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
import os os.mkdir('hello') #可以直接创建新文件 os.mkdir('hello/world') #可以在已有文件下创建新的文件
(4)os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
(5)os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
import os print(os.listdir('你好')) #查看你好文件下的文件 print(os.listdir()) #查看当前文件夹下的所有文件 运行结果: ['呵呵'] ['2016-01-02.log', '2016-01-03.log', 'a.txt', 'al.txt', 'all', 'alll', 'bmi.py', 'dir3', 'evreyday.log', 'file-副本', 'hello', 'lxl', 'lxl.html', 'lxl.txt', 'student_msg', 'student_msg.txt', 't1.txt', '作业总结.py', '你好', '刘.log', '刘晓蕾1.py', '刘晓蕾10.py', '刘晓蕾11.py', '刘晓蕾13.py', '刘晓蕾15.py', '刘晓蕾17.py', '刘晓蕾2.py', '刘晓蕾3.py', '刘晓蕾4.py', '刘晓蕾5.py', '刘晓蕾6.py', '刘晓蕾7.py', '刘晓蕾8.py', '呵呵', '哈哈', '哈哈.html', '考试题.py', '课上代码.py', '购物车.py', '麻.log']
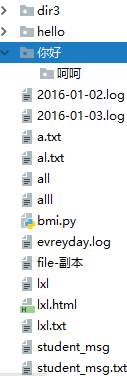
(6)os.remove() 删除一个文件,注意删除的是一个文件
(7)os.rename("oldname","newname") 重命名文件/目录
(8)os.stat('path/filename') 获取文件/目录信息
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。 stat 结构
(9)os.system("bash command") 运行shell命令,直接显示
(10)os.popen("bash command).read() 运行shell命令,获取执行结果
帮助你显示当前路径下的所有文件和文件夹
os.system('dir 路径') # 使用python语言直接执行操作系统的命令
不需要print(),因为操作系统执行,执行操作系统的命令,没有返回值,实际的操作/删除一个文件
创建一个文件夹 exec
os.listdir('路径') # 使用python语言的os模块提供的方法 间接调用了操作系统命令
需要print()
os.listdir('路径')和os.system('dir 路径'),os.popen('dir'),read()有返回值
功能是一样的,
os.system('执行字符串数据类型的操作系统命令'),
os.popen('执行字符串数据类型的操作系统命令,并返回结果')
# exec/eval执行的是字符串数据类型的 python代码
# os.system和 os.popen是执行字符串数据类型的 命令行代码
# getcwd # 获取当前执行命令的时候所在的目录
# chdir # 修改当前执行命令的时候所在的目录
(11)os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
并不是指当前文件所在的目录
当前文件是在哪个目录下执行的
ret=os.getcwd() print(ret) #C:\Users\ASUS\PycharmProjects\untitled3\作业 import os ret=os.getcwd() print(ret) #C:\Users\ASUS\PycharmProjects\untitled3\博客
(12)os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
(13)os.path.abspath(path) 返回path规范化的绝对路径,如果是相对路径转化成绝对路径
print(os.path.abspath('你好')) # C:\Users\ASUS\PycharmProjects\untitled3\作业\你好
os.path.split(path) 将path分割成目录和文件名二元组返回
import os print(os.path.abspath(r'C:\Users\ASUS\PycharmProjects\untitled3\博客\十六天.py')) # C:\Users\ASUS\PycharmProjects\untitled3\博客\十六天.py print(os.path.split(r'C:\Users\ASUS\PycharmProjects\untitled3\博客\十六天.py')) # ('C:\\Users\\ASUS\\PycharmProjects\\untitled3\\博客', '十六天.py')
(14)os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
import os print(os.path.dirname(r'C:\Users\ASUS\PycharmProjects\untitled3\博客\十六天.py')) #C:\Users\ASUS\PycharmProjects\untitled3\博客
(15)os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
ret2 = os.path.basename(r'C:\Users\ASUS\PycharmProjects\untitled3\博客\十六天.py') print(ret2) #十六天.py
# 如果你两个值都需要 os.path.split
# 如果你只要一个值 os.path.dirname/os.path.basename
(16)os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
ret=os.path.exists(r'C:\Users\ASUS\Desktop\python\day19\code\day19\4.os模块.py') print(ret) #True
(17)os.path.isabs(path) 如果path是绝对路径,返回True
ret=os.path.isabs(r'C:\Users\ASUS\Desktop\python\day19\code\day19\4.os模块.py') print(ret) #True ret=os.path.isabs('4.os模块.py') print(ret) #False
(18)os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
print(os.path.isfile('2016-01-02.log')) #True print(os.path.isfile(r'C:\Users\ASUS\PycharmProjects\untitled3\作业\2016-01-02.log')) #True
(19)os.path.isdir(path) 如果path是一个存在的目录(文件夹),则返回True。否则返回False
print(os.path.isdir(r'C:\Users\ASUS\PycharmProjects\untitled3\作业\你好')) #True print(os.path.isdir(r'C:\Users\ASUS\PycharmProjects\untitled3\作业\2016-01-03.log')) #False
(20)os.path.join(path1[, path2[, ...]]) 将个路径组合后返回不管你存不存在,就是追加
print(os.path.join(r'C:\Users\ASUS\PycharmProjects\untitled3\作业\你好','aaa')) # C:\Users\ASUS\PycharmProjects\untitled3\作业\你好\aaa
(21)os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
print(os.path.getsize(r'C:\Users\ASUS\PycharmProjects\untitled3\作业\2016-01-02.log')) # 141 字节数
(22)os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
(23)os.path.getsize(path) 返回path的大小
二,练习题
1.使用python代码统计一个文件夹中所有文件的总大小
你需要统计文件夹大小
拿到这个文件夹下所有的文件夹 和 文件
是文件就取大小
是文件夹 再打开这个文件夹 : 文件/文件夹
def func(path): import os num=0 ret=os.listdir(path) for i in ret: print(i) new_path=os.path.join(path,i) if os.path.isfile(new_path): num=num+os.path.getsize(new_path) else: ret=func(new_path) num=num+ret return num print(func(r'C:\Users\ASUS\PycharmProjects\untitled3\作业')) #200926
def func(path): #C:\Users\ASUS\PycharmProjects\untitled3\作业 import os num=0 ret=os.listdir(path) #['dir3','hello'......] for i in ret: #dir3 print(i) new_path=os.path.join(path,i) #C:\Users\ASUS\PycharmProjects\untitled3\作业\dir3 if os.path.isfile(new_path): num=num+os.path.getsize(new_path) else: ret=func(new_path) #C:\Users\ASUS\PycharmProjects\untitled3\作业\dir3 后面不执行了 200后面返回来的 num=num+ret return num print(func(r'C:\Users\ASUS\PycharmProjects\untitled3\作业')) def func(path): #C:\Users\ASUS\PycharmProjects\untitled3\作业\dir3 import os num=0 ret=os.listdir(path) #['哈哈','呵呵] for i in ret: #哈哈.txt print(i) new_path=os.path.join(path,i) #C:\Users\ASUS\PycharmProjects\untitled3\作业\dir3\哈哈.txt if os.path.isfile(new_path): num=num+os.path.getsize(new_path) #100 100 num=200 else: ret=func(new_path) num=num+ret return num #200 print(func(r'C:\Users\ASUS\PycharmProjects\untitled3\作业'))
lst = [r'D:\sylar\s15',] # 列表的第一个目录就是我要统计的目录 size_sum = 0 while lst: # [r'D:\sylar\s15',] lst = ['D:\sylar\s15\day01','D:\sylar\s15\day01'..] path = lst.pop() # path = 'D:\sylar\s15' lst = [] path_list = os.listdir(path) # path_list = ['day01',day02',aaa,day15.py] for name in path_list: # name = day01 abs_path = os.path.join(path,name) if os.path.isdir(abs_path): # 文件夹的逻辑 lst.append(abs_path) # lst.append('D:\sylar\s15\day01') lst = ['D:\sylar\s15\day01'] else: size_sum += os.path.getsize(abs_path) print(size_sum)
三.序列化模块(列表,元组,字符串)
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。 但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。 你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢? 没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串, 但是你要怎么把一个字符串转换成字典呢? 聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。 eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。 BUT!强大的函数有代价。安全性是其最大的缺点。 想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。 而使用eval就要担这个风险。 所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
1.json模块(json.dumps()和json.loads())
(1)json.dumps()序列化 转化成字符串
import json dic={'name':'liuxioalei','gender':'nan','age':'twenty'} print(json.dumps(dic),type(json.dumps(dic))) print(dic,type(dic)) # {"name": "liuxioalei", "gender": "nan", "age": "twenty"} <class 'str'> # {'name': 'liuxioalei', 'gender': 'nan', 'age': 'twenty'} <class 'dict'>
(2)json.loads() 反序列化
import json dic={'name':'liuxioalei','gender':'nan','age':'twenty'} ret=json.dumps(dic) print(json.loads(ret),type(json.loads(ret))) print(ret,type(ret)) #{'name': 'liuxioalei', 'gender': 'nan', 'age': 'twenty'} <class 'dict'> # {"name": "liuxioalei", "gender": "nan", "age": "twenty"} <class 'str'>
json常见问题
(1) int 型转化过去转化不回来转化
import json dic = {1 : 'value',2 : 'value2'} ret = json.dumps(dic) # 序列化 print(dic,type(dic)) # {1: 'value', 2: 'value2'} <class 'dict'> print(ret,type(ret)) # {"1": "value", "2": "value2"} <class 'str'> res = json.loads(ret) # 反序列化 print(res,type(res)) # {'1': 'value', '2': 'value2'} <class 'dict'>
(2)元组变成字符串反序列变成元组
import json dic = {1 : [1,2,3],2 : (4,5,'aa')} ret = json.dumps(dic) # 序列化 print(dic,type(dic)) # {1: [1, 2, 3], 2: (4, 5, 'aa')} <class 'dict'> print(ret,type(ret)) #{"1": [1, 2, 3], "2": [4, 5, "aa"]} <class 'str'> res = json.loads(ret) # 反序列化 print(res,type(res)) # {'1': [1, 2, 3], '2': [4, 5, 'aa']} <class 'dict'>
(3)集合不可以序列化
import json s = {1,2,'aaa'} json.dumps(s) #TypeError: Object of type 'set' is not JSON serializable
(4)字典的键必须是字符串,(数字强制转换成字符串了)
json.dumps({(1,2,3):123})
# TypeError: keys must be a string
(5)dump(),load(),loads(),dumps()在处理文字上,如果操作文件中遇到汉字需要加ensure_ascii=False,否则读出文件还需解码
import json
f = open('file','w')
json.dump({'国籍':'中国'},f) #json.dump()/json.load()将汉字转化成字节直接写入文件
ret = json.dumps({'国籍':'中国'}) #转成字
print(type(ret)) #<class 'str'> 字节形字符串
f.write(ret+'\n')
file文件

import json
f = open('file','w')
json.dump({'国籍':'中国'},f)
f.close()
with open('file','r') as f:
for i in f:
json.loads(i)
print(i)
{"\u56fd\u7c4d": "\u4e2d\u56fd"}
json.dump({'国籍':'美国'},f,ensure_ascii=False)
ret = json.dumps({'国籍':'美国'},ensure_ascii=False)
f.write(ret+'\n')
f.close()
写进文件里依然乱码
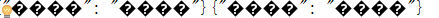
但是从文件里反序列化可以出来汉字
{"国籍": "美国"}
json 在所有的语言之间都通用 : json序列化的数据 在python上序列化了 那在java中也可以反序列化
能够处理的数据类型是非常有限的 : 字符串 列表 字典 数字
字典中的key只能是字符串
四.练习题
1.向文件中记录字典
import json dic = {'key' : 'value','key2' : 'value2'} ret = json.dumps(dic) # 序列化 with open('json_file','a') as f: f.write(ret)

2.从文件中读取字典
with open('json_file','r') as f: str_dic = f.read() dic = json.loads(str_dic) print(dic.keys())
3.dump() 和 load() 直接操作文件的
import json f = open('json_file','w') dic = {'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件 f.close()
f = open('json_file') dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回 f.close() print(type(dic2),dic2) load和dump
4.不支持连续的存取
5.需求 :就是想要把一个一个的字典放到文件中,再一个一个取出来
dic = {'key1' : 'value1','key2' : 'value2'}
with open('json_file','a') as f:
str_dic = json.dumps(dic)
f.write(str_dic+'\n')
str_dic = json.dumps(dic)
f.write(str_dic + '\n')
str_dic = json.dumps(dic)
f.write(str_dic + '\n')
with open('json_file','r') as f:
for line in f:
dic = json.loads(line.strip())
print(dic.keys())
6.ensure_ascii
当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False
即可,此时存入json的中文即可正常显示。
import json f = open('file','w') json.dump({'国籍':'中国'},f) ret = json.dumps({'国籍':'中国'}) f.write(ret+'\n') f文件 {"\u56fd\u7c4d": "\u4e2d\u56fd"}{"\u56fd\u7c4d": "\u4e2d\u56fd"} json.dump({'国籍':'美国'},f,ensure_ascii=False) ret = json.dumps({'国籍':'美国'},ensure_ascii=False) f.write(ret+'\n') f.close() f文件{"����": "����"}{"����": "����"}
五.pickle模块
2. dumps 序列化的结果只能是字节
# print(pickle.loads(ret)) #二进制字符
3.只能在python中使用
4.在和文件操作的时候,需要用rb wb的模式打开文件
5.可以多次dump 和 多次load
# dump
# with open('pickle_file','wb') as f:
# pickle.dump(dic,f)
# load
# with open('pickle_file','rb') as f:
# ret = pickle.load(f)
# print(ret,type(ret))
# dic = {(1,2,3):{'a','b'},1:'abc'}
# dic1 = {(1,2,3):{'a','b'},2:'abc'}
# dic2 = {(1,2,3):{'a','b'},3:'abc'}
# dic3 = {(1,2,3):{'a','b'},4:'abc'}
# with open('pickle_file','wb') as f:
# pickle.dump(dic, f)
# pickle.dump(dic1, f)
# pickle.dump(dic2, f)
# pickle.dump(dic3, f)
# with open('pickle_file','rb') as f:
# ret = pickle.load(f)
# print(ret,type(ret))
# ret = pickle.load(f)
# print(ret,type(ret))
# ret = pickle.load(f)
# print(ret, type(ret))
# ret = pickle.load(f)
# print(ret, type(ret))
# ret = pickle.load(f)
# print(ret, type(ret))
可以实现多次写读
with open('pickle_file','rb') as f:
while True:
try:
ret = pickle.load(f)
print(ret,type(ret))
except EOFError:
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号