
读书报告
一、NumPy
1.基础用法
创建ndarray:创建多维数组对象。
数组操作:对数组执行各种操作,例如修改维度、选择数据、切片等。
数学函数:进行数学运算,例如求平均值、标准差、方差等。
随机数生成:使用NumPy中的随机数生成函数生成随机数。
线性代数:进行线性代数运算,例如矩阵乘法、逆矩阵求解等。
文件操作:读写文件,例如将数组保存到文件或从文件加载数组。
2.基本函数用法
np.array():创建numpy数组
np.zeros():返回全0数组
np.ones():返回全1数组
np.arange():创建等差数列数组
np.linspace():创建等间隔数列数组
np.reshape():改变数组形状
np.add():加法运算
np.subtract():减法运算
np.multiply():乘法运算
np.divide():除法运算
np.dot():矩阵乘法
np.sum():求和
np.mean():求平均值
c.数组索引和切片
索引名[i]:获取第i个元素
索引名[start:end]:获取从start到end之间的元素
索引名[:, col_num]:获取所有行中第col_num列的元素
索引名[condition]:根据条件获取元素
d.数学函数
np.sin():正弦函数
np.cos():余弦函数
np.exp():指数函数
np.log():自然对数函数
np.sqrt():平方根函数
np.power():幂函数
e.统计函数
np.min():最小值
np.max():最大值
np.std():标准差
np.var():方差
np.median():中位数
3.具体使用及结果
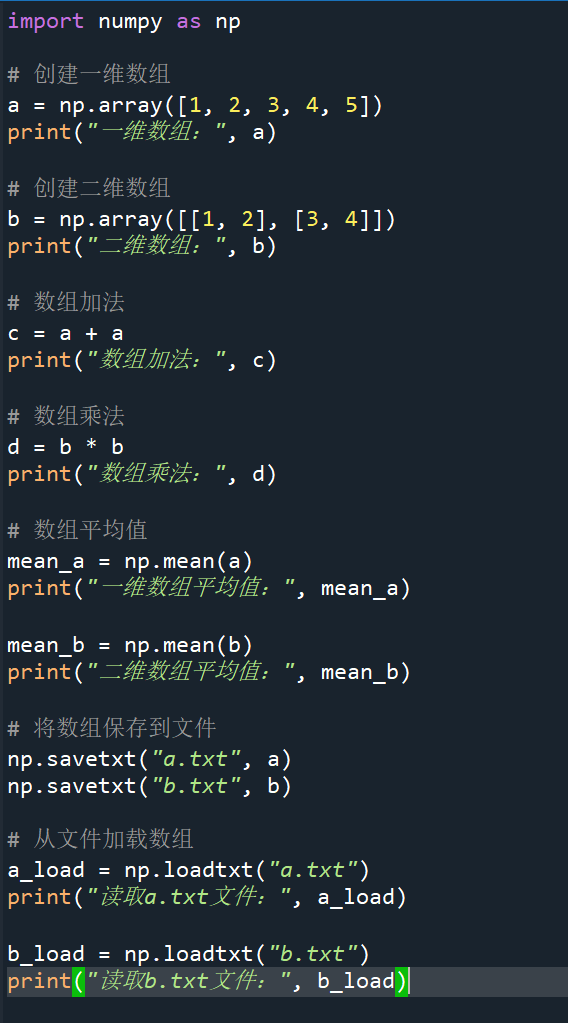
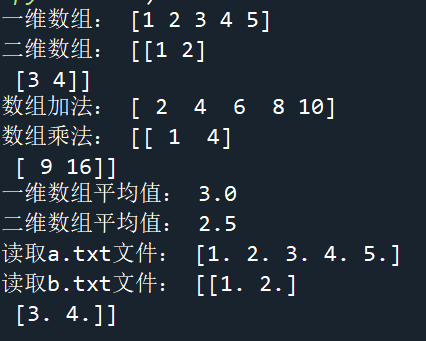
二、SciPy
1.基本函数用法
scipy.cluster 矢量量化/Kmeans
scipy.constants 物理和数学常数
scipy.fftpack 傅里叶变换
scipy.integrate 积分
scipy.interpolate 插值
scipy.io 数据输入输出
scipy.linalg 线性代数
scipy.ndimage n维图像包
scipy.odr Orthogonal distance regression
scipy.optimize 优化
scipy.signal 信号处理
scipy.sparse 稀疏矩阵
scipy.special 任何特殊的数学函数
scipy.stats 统计数据
2.具体使用及结果
此处只列举部分函数的用法
a.计算逆矩阵
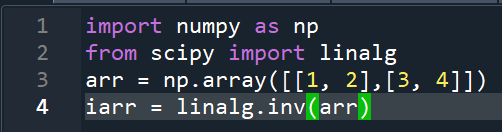
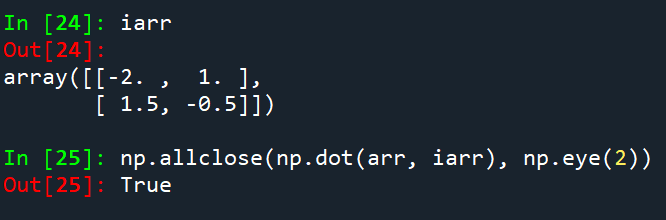
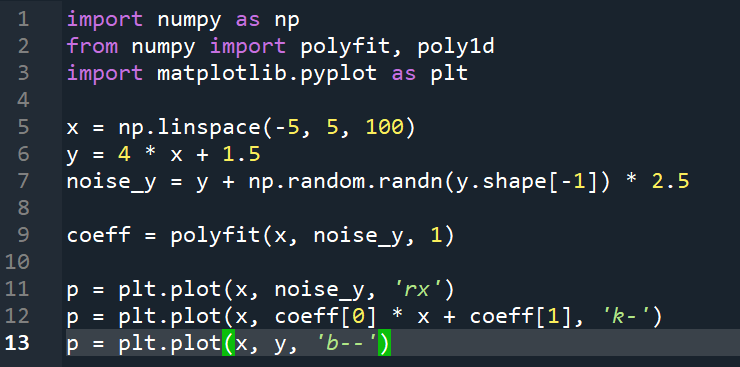
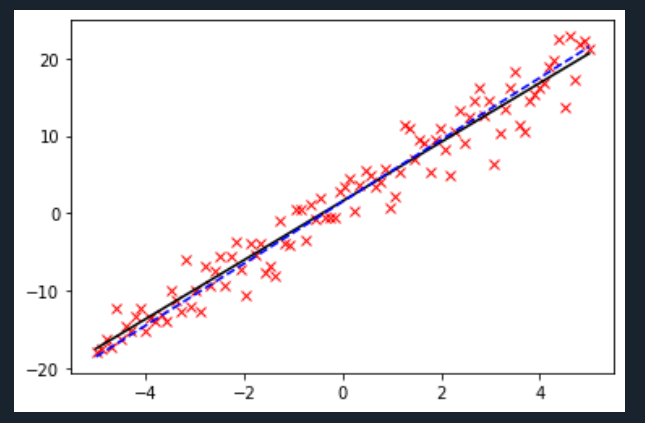
b.拟合
三、Pandas
1.基本函数用法
pd.read_csv(filename) 读取 CSV 文件
pd.read_excel(filename) 读取 Excel 文件
pd.read_sql(query, connection_object) 从 SQL 数据库读取数据
pd.read_json(json_string) 从 JSON 字符串中读取数据
pd.read_html(url) 从 HTML 页面中读取数据
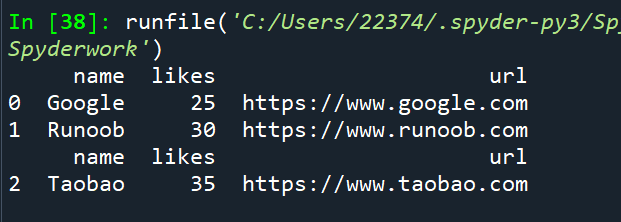
df.head(n) 显示前 n 行数据
df.tail(n) 显示后 n 行数据
df.info() 显示数据的信息,包括列名、数据类型、缺失值等
df.describe() 显示数据的基本统计信息,包括均值、方差、最大值、最小值等
df.shape 显示数据的行数和列数
df.dropna() 删除包含缺失值的行或列
df.fillna(value) 将缺失值替换为指定的值
df.replace(old_value, new_value) 将指定值替换为新值
df.duplicated() 检查是否有重复的数据
df.drop_duplicates() 删除重复的数据
df[column_name] 选择指定的列
df.loc[row_index, column_name] 通过标签选择数据
df.iloc[row_index, column_index] 通过位置选择数据
df.ix[row_index, column_name] 通过标签或位置选择数据
df.filter(items=[column_name1, column_name2]) 选择指定的列
df.filter(regex='regex') 选择列名匹配正则表达式的列
df.sample(n) 随机选择 n 行数据
df.sort_values(column_name) 按照指定列的值排序
df.sort_values([column_name1, column_name2], ascending=[True, False]) 按照多个列的值排序
df.sort_index() 按照索引排序
df.groupby(column_name) 按照指定列进行分组
df.aggregate(function_name) 对分组后的数据进行聚合操作
df.pivot_table(values, index, columns, aggfunc) 生成透视表
pd.concat([df1, df2]) 将多个数据框按照行或列进行合并
pd.merge(df1, df2, on=column_name) 按照指定列将两个数据框进行合并
df.loc[row_indexer, column_indexer] 按标签选择行和列
df.iloc[row_indexer, column_indexer] 按位置选择行和列
df[df['column_name'] > value] 选择列中满足条件的行
df.query('column_name > value') 使用字符串表达式选择列中满足条件的行
df.describe() 计算基本统计信息,如均值、标准差、最小值、最大值等
df.mean() 计算每列的平均值
df.median() 计算每列的中位数
df.mode() 计算每列的众数
df.count() 计算每列非缺失值的数量
2.具体使用及结果
此处只列举部分函数及用法
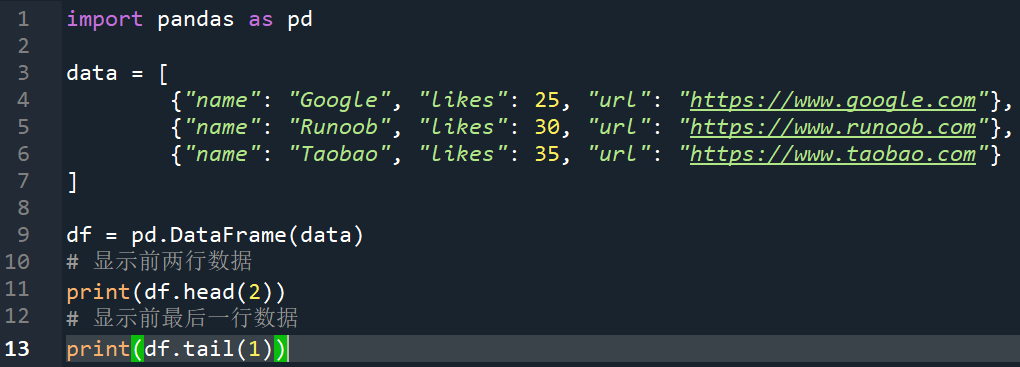
a.查看数据
b.数据统计和描述
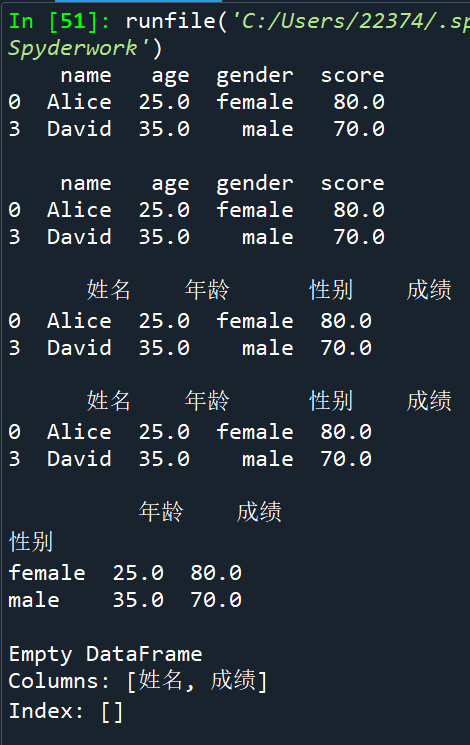

四、Matplotlib
1.基本函数用法
plot():用于绘制线图和散点图
scatter():用于绘制散点图
bar():用于绘制垂直条形图和水平条形图
hist():用于绘制直方图
pie():用于绘制饼图
imshow():用于绘制图像
subplots():用于创建子图
2.具体使用及结果
a.绘制函数1
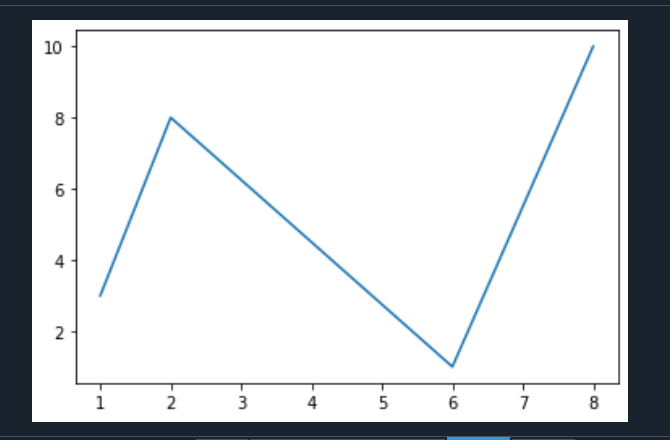
b.绘制函数2
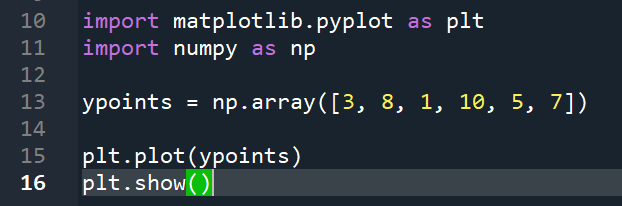
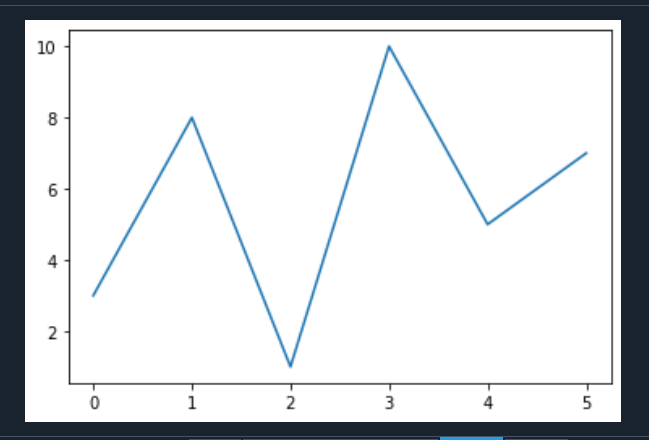
c.绘制函数3
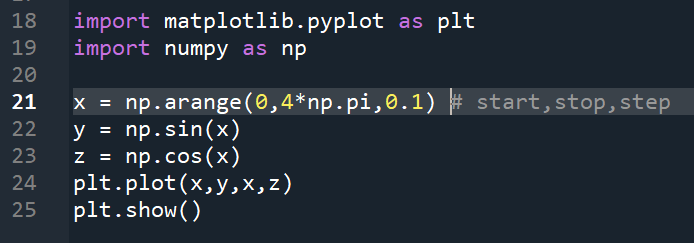
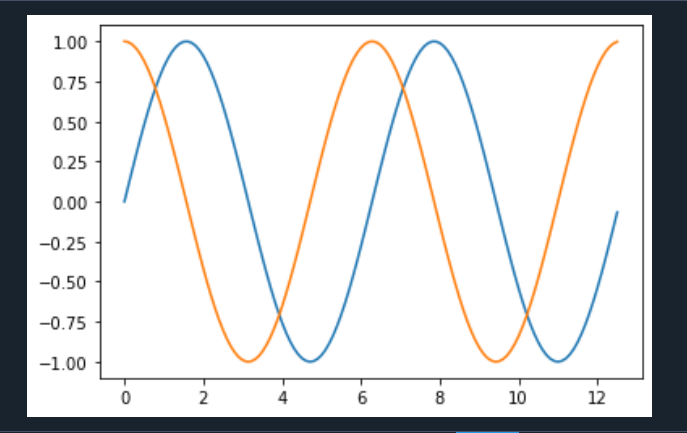

 浙公网安备 33010602011771号
浙公网安备 33010602011771号