


jieba分词 | 西游记相关分词,出现次数最高的20个。
一、代码
1 import jieba 2 3 def takeSecond(elem): 4 return elem[1] 5 6 def main(): 7 path = "西游记.txt" 8 file = open(path,"r",encoding="utf-8") 9 text=file.read() 10 file.close() 11 12 words = jieba.lcut(text) 13 counts = {} 14 for word in words: 15 if len(word) == 1: 16 continue 17 elif word == "大圣" or word=="老孙" or word=="行者" or word=="孙大圣" or word=="孙行者" or word=="猴王" or word=="悟空" or word=="齐天大圣" or word=="猴子": 18 rword = "孙悟空" 19 elif word == "师父" or word == "三藏" or word=="圣僧": 20 rword = "唐僧" 21 elif word == "呆子" or word=="八戒" or word=="老猪": 22 rword = "猪八戒" 23 elif word=="沙和尚": 24 rword="沙僧" 25 elif word == "妖精" or word=="妖魔" or word=="妖道": 26 rword = "妖怪" 27 elif word=="佛祖": 28 rword="如来" 29 elif word=="三太子": 30 rword="白马" 31 else: 32 rword = word 33 counts[rword] = counts.get(rword,0) + 1 34 35 excludes={'一个','那里','怎么','我们','不知','两个','甚么','不是','只见','原来','不敢','不曾','这个','闻言','如何','正是','只是','出来','一声','真个','不得','这里','今日','那个'} 36 37 for delWord in excludes: 38 try: 39 del counts[delWord] 40 except: 41 continue 42 43 44 items = list(counts.items()) 45 items.sort(key = takeSecond,reverse=True) 46 47 for i in range(20): 48 item=items[i] 49 keyWord =item[0] 50 count=item[1] 51 print("{0:<10}{1:>5}".format(keyWord,count)) 52 53 main()
二、运行结果
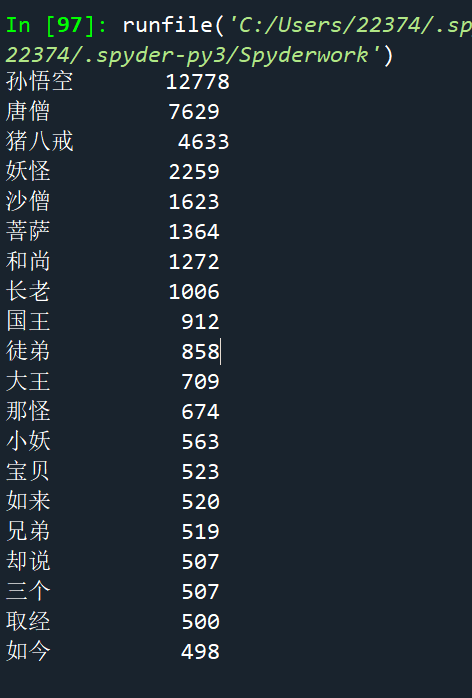


 浙公网安备 33010602011771号
浙公网安备 33010602011771号