
顾琳杰-第一次个人编程作业
| 博客班级 | <2018级计算机和综合实验班> |
|---|---|
| 作业要求 | <第一次个人编程作业> |
| 作业目标 | <数据采集,分析和展示> |
| 作业源代码 | <first-personal-work> |
| 学号 | <211814168> |
| 过程 | 花费时间 |
|---|---|
| 数据分析 | 1h |
| 代码实现 | 2h |
| 词云图实现 | 3h |
| 上传代码 | 1h |
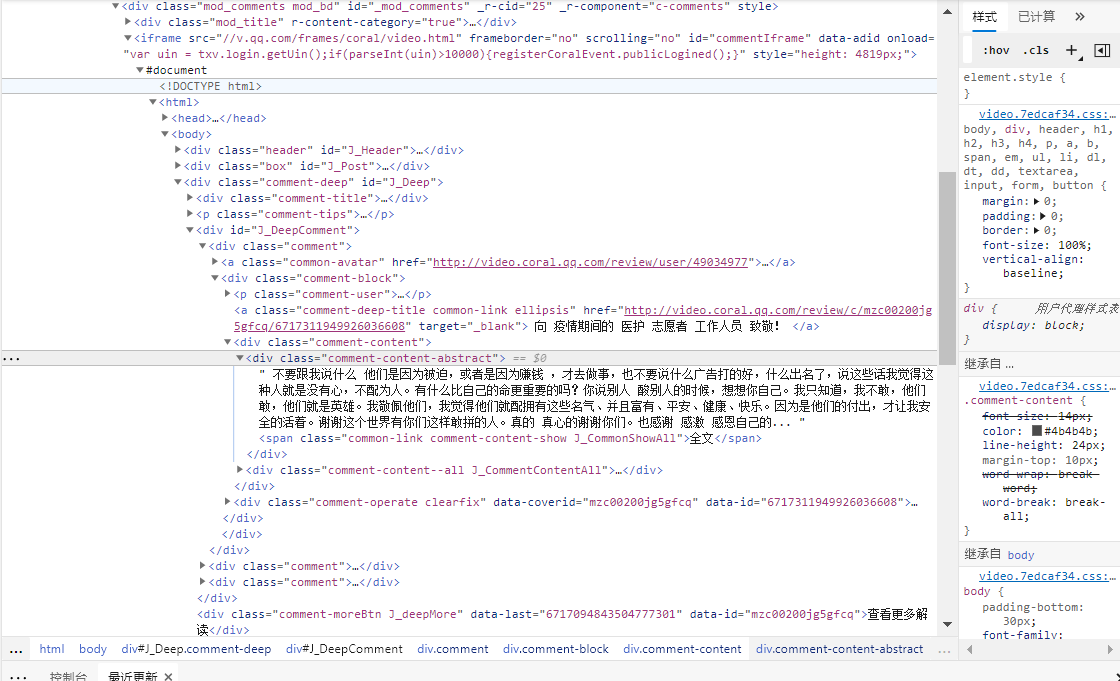
| 一、数据采集 | |
| 上学期刚学习的爬虫,现在却反而要再次预习才会爬取了。寻找评论所在区域,对其进行多次尝试爬取。 | |
 |
|
 |
|
| 二、数据处理 | |
| 对爬取的评论做分词处理 |
def word_counter(read_buff):
words_dict = dict()
for word in read_buff: # 统计字典中key相同的词
words_dict[word] = words_dict.get(word, 0) + 1
# get()方法,如果key存在返回对应value值,否则返回默认值0
# 对字典排序
return sorted(words_dict.items(), key=lambda item: item[1], reverse=True)
def breakup_sentence(sentence, read_buff):
msg_list = jieba.cut(sentence)
for msg in msg_list:
if len(msg) > 1: # 去除空字符和单个字符的
read_buff.append(msg)
def main():
read_buff = list()
load_data(read_buff)
words_dict = word_counter(read_buff)
write_to_file(words_dict)
三、词云图
使用jieba对热词进行处理,由于第一次接触,并不是很了解。所以经过我百度,询问同学,多次修改过后,粗略的高出了一张词云图。

总结
1、对于学过的爬虫已经不太记得了,需要再次复习,拾起来。
2、echarts.js插件不太会使用,争取在以后的作业中逐步熟练。
3、git的分支目前仍旧不清楚该如何处理,git对我来说是个大问题。
参考资料
Python爬虫实战:爬取腾讯视频的评论
echarts如何实现关键词云图
echarts 简单词云制作,自定义图案词云echarts-wordcloud.js
许文豪——第一次个人编程作业

