


徐鑫泽---第一次个人编程作业
| 这个作业属于哪个课程 | <2018 级计算机和综合实验班> |
|---|---|
| 这个作业要求在哪里 | <作业要求的链接> |
| 这个作业的目标 | <数据采集,可视化,前端> |
| 作业源代码 | first-personal-work |
| 学号 | <211808579> |
| 计划安排 | |
| 步骤 | 计划时间 |
| ---------- | -------------------------------------- |
| 理解作业要求 | 30分钟 |
| 计划如何完成 | 30分钟 |
| 相关资料的学习 | 2天 |
| 创建仓库并连接 | 15分钟 |
| 编写爬虫代码 | 1天 |
| 词频统计及json转化 | 半天 |
| 制作此云图 | 半天 |
| git上传 | 1小时 |
- 编写爬虫
首先进入网页观察评论源码
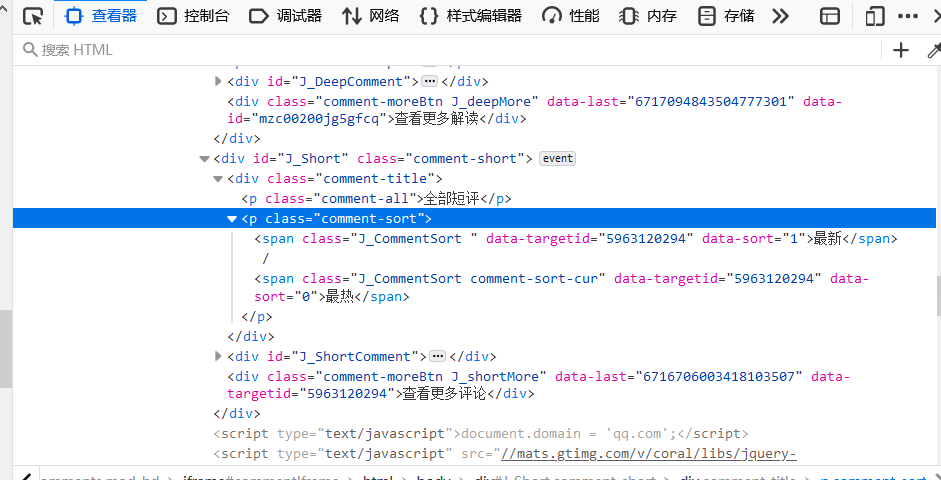
对网页进行分析发现每当点击更多评论时会发现有新地址跳出
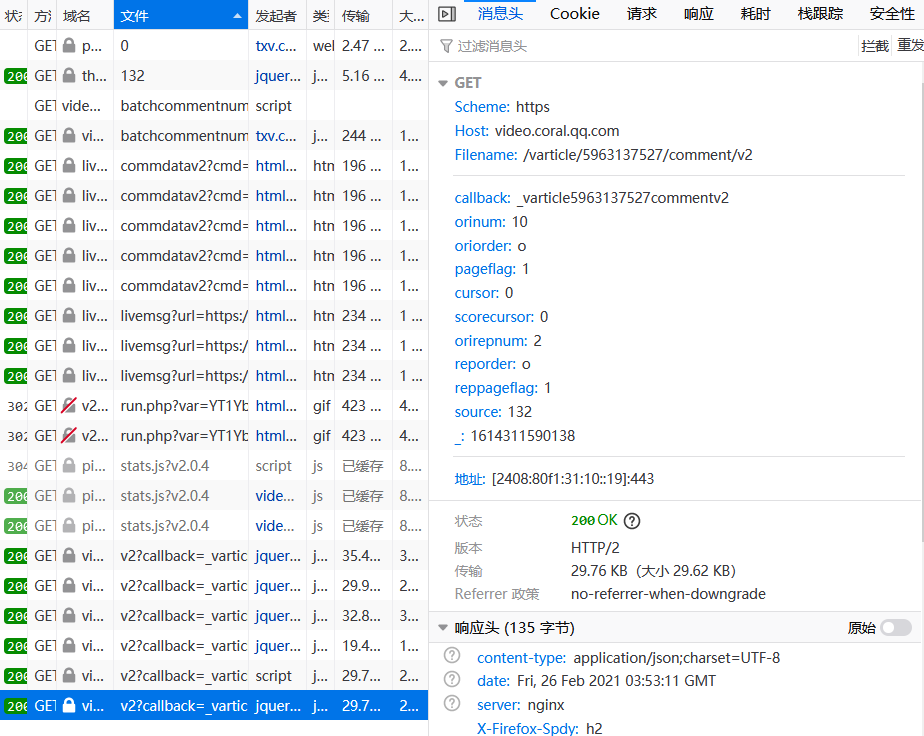
通过比较网址发现只有 cursor 和 source 进行了改变,其他是不变的,source 是在第一个的基础上进行加一操作,所以只需要获取到 cursor 即可。
- 编写爬取内容
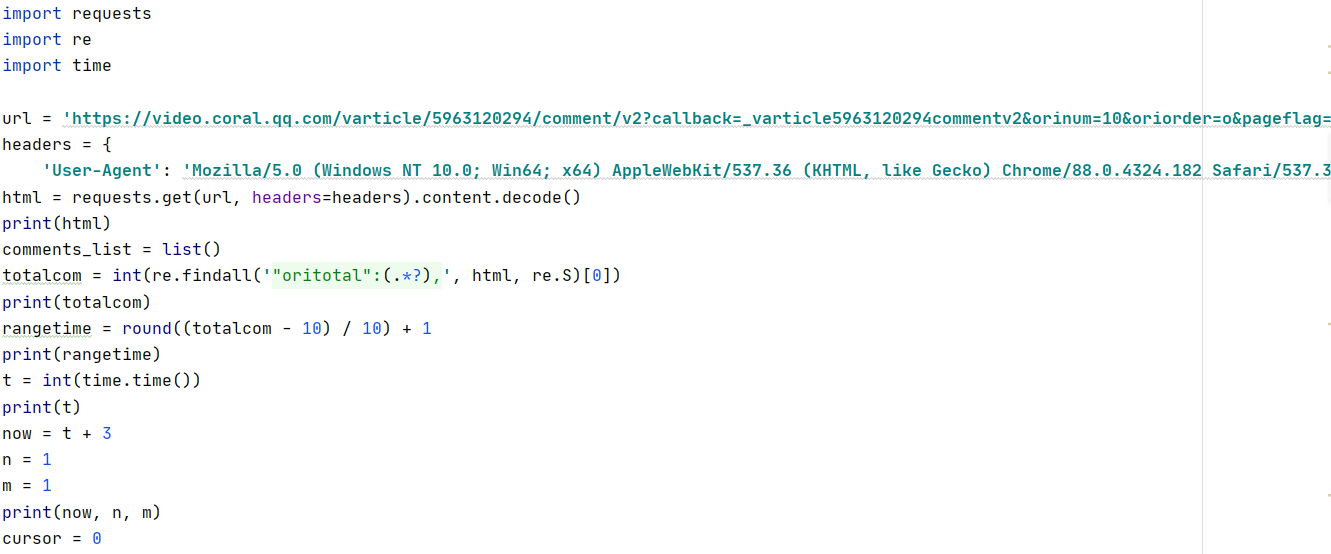
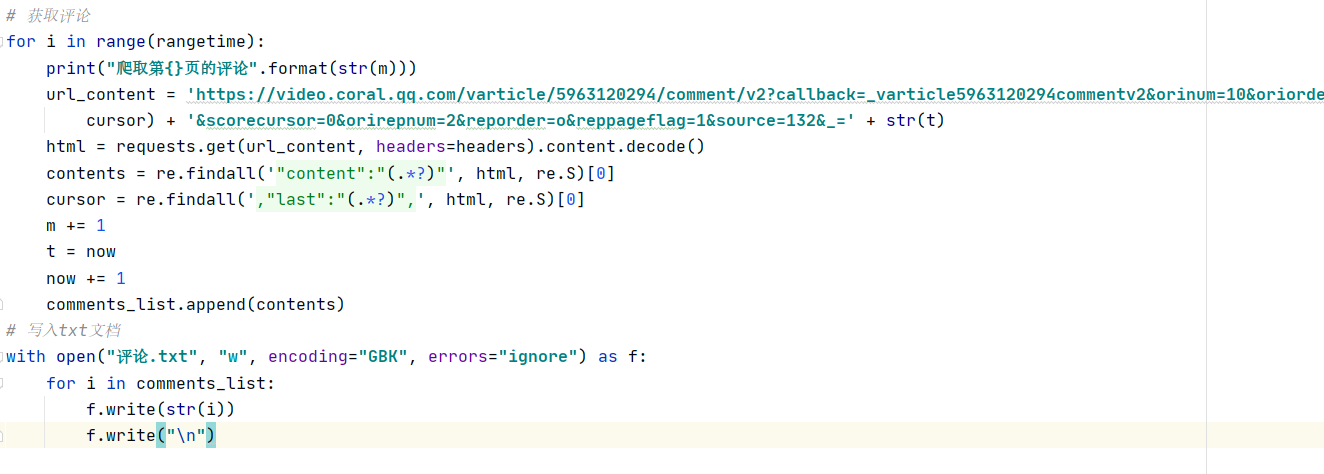
3. 编写json
在做词频统计的时候,在import jieba时出现问题
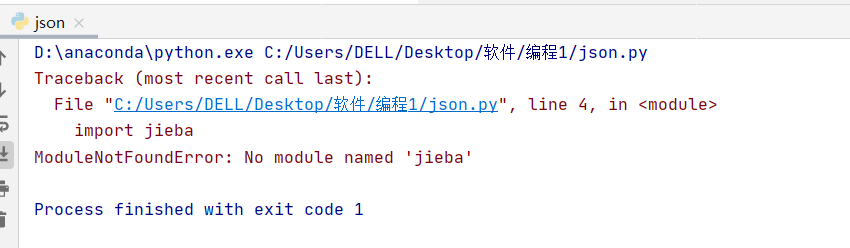
然而在终端下载时显示已经下载过jieba,通过百度了解到可能因为默认的安装路径不对,而直接在终端下载
可能会面临网络不稳定等多种因素(本人亲自下了几次都失败了,又慢又完不成),于是乎下载国内的镜像,并且修改下载路径终于可以使用jieba。
参考网页
pycharm安装jieba包(中文词分解析)
呜。。。这个jieba真的花了我太多时间了
而后进行频数统计在完成代码的过程中遇到报错“UnicodeDecodeError: 'utf-8' codec can't decode byte”一时间也不知道如何
解决,最后搜索得到了解答
python 报错"UnicodeDecodeError: 'utf-8' codec can't decode byte"的解决办法
哈哈正如他所说的“原文件的编码方式是“ANSI”. 哦哦哦哦哦哦哦哦哦哦哦。。。。不报错才怪呢!”
- 制作词云图
在顺利完成js之后,就到了词云图的环节,在这里我要感谢我的同学李明特,他在这个环节帮到了我许多,还给我提供了一个比较丰富的资源,并且跟我讲解了制作词云图的方法,这可以说是到现在为止比较顺利的缓解了!!
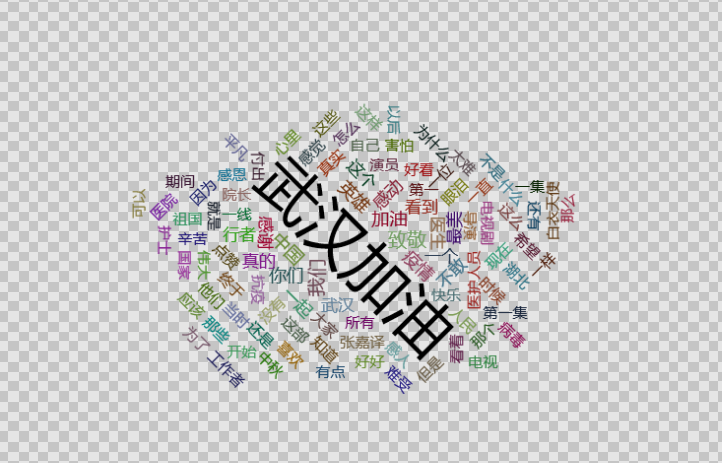
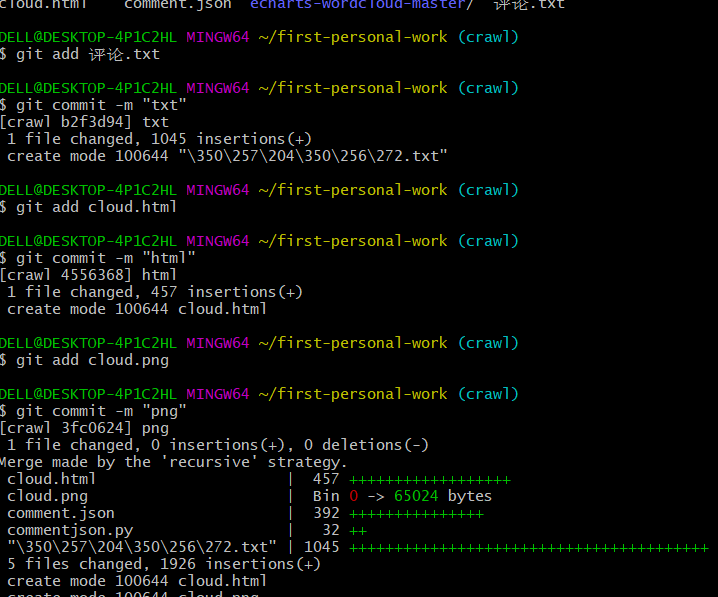
- 将所有文件上传到远程仓库
将所有的文件一一git add 到暂存区,在经过 get commit -m 上传
合并分支
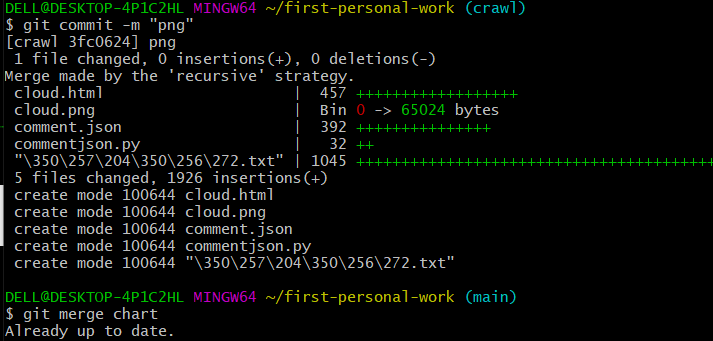
最后git push 将所有文件传输到远程仓库中
- 个人总结
总的来说这次的作业并不算顺利,有许多爬虫的知识都遗忘了,需要拿书现学。
对于git的操作和用途了解很少,很难快速准确的达到要求。
在库的安装上花费了比较多的时间,需要加强练习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号