

| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11248 |
|---|---|
| 作业目标 | <通过cookie模拟登陆网页并爬取数据> |
| 作业源代码 | https://gitee.com/chenxian0804/pair |
| 陈 显 | <211806375> |
| 陈小雨 | <211806377> |
一、结对过程
①结对的感受
经过前一次的结对作业,我们原本就很默契的合作得到了更大的提升,此次结对作业我们分工明确,一个驾驶员,一个领航员,效率较上次得到了一定幅度的提升,我们之间变得更加信任对方,互相像对方学习身上所没有的优点。我们一致认为,结对过程就是一个享受的过程。
②对对方的评价
我对她的评价:集美貌与智慧一身,聪明伶俐的一个女孩子,在探讨和编程过程中,总能迅速的发现我的不足及时的指正,是一个非常棒的队友,此次结对过程非常顺利。
她对我的评价:陈显同学很认真,当遇到不会的问题总是会第一时间去面对问题,想着如何去解决它、突破它,是我学习上的榜样。
③结对照片

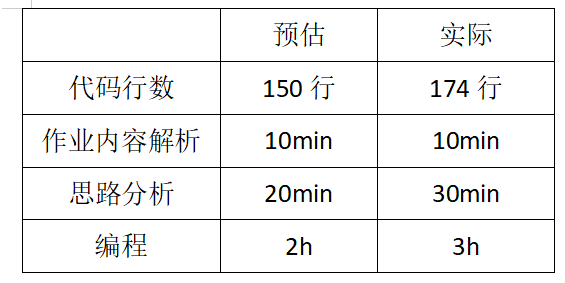
二、代码行数及时间预估
三、需求分析
☆ 嫌弃从本地网页爬取数据太low ,想直接通过网络爬取云班课的数据,根据经验值排序,看看自己和自己的同学在全班第几名,同时能计算出平均经验、最低经验、最高经验。
四、思路分析(编码过程)
-
①这次的作业是在第一次个人编程作业的基础上改为用网络直接爬取数据,那么面临的 一个问题就是如何进入云班课,万事开头难,这时候我们发现需要用cookie进行模拟登陆。
Properties pp=new Properties();
pp.load(new FileInputStream("resources/config.properties"));
String url=pp.getProperty("url");
String cookie = pp.getProperty("cookie");
Document index=getlogn(url,cookie);
pp.load(new FileInputStream("resources/config.properties"));
String url=pp.getProperty("url");
String cookie = pp.getProperty("cookie");
Document index=getlogn(url,cookie);
-
②由于要排序的只有课堂完成部分,那么就要找到这一模块,我首先是把所有的作业板块都提取下来,然后判断是否含有“课堂完成”来提取课堂完成部分,当然也可以直接通过span标签获取课堂完成部分内容。接着我通过判断是否为课堂完成部分进入活动板块的网页地址,获取成绩页面所有成绩,姓名,学号相关模块。
Elements all = index.getElementsByClass("interaction-row");
//爬取全班学生学号和姓名并存入集合
String NextUrlForList=getNextUrl(all.get(4));
//登录具体分数网页
Document newdix = getlogn(NextUrlForList, cookie);
//爬取全班学生学号和姓名并存入集合
String NextUrlForList=getNextUrl(all.get(4));
//登录具体分数网页
Document newdix = getlogn(NextUrlForList, cookie);
for (int i = 0; i < all.size(); i++) {
//判断该题目是否为“课堂完成部分”
if (all.get(i).toString().contains("课堂完成")) {
//获取分数网页的url
String NextUrl = getNextUrl(all.get(i));
//登录具体分数页面
Document NewIndex = getlogn(NextUrl, cookie);
//获取成绩,姓名,学号相关的模块
Elements AllScore = NewIndex.getElementsByClass("homework-item");
//判断该题目是否为“课堂完成部分”
if (all.get(i).toString().contains("课堂完成")) {
//获取分数网页的url
String NextUrl = getNextUrl(all.get(i));
//登录具体分数页面
Document NewIndex = getlogn(NextUrl, cookie);
//获取成绩,姓名,学号相关的模块
Elements AllScore = NewIndex.getElementsByClass("homework-item");
-
③通过for循环来获取全部同学的成绩以及信息,通过调用函数getStudentMess和getStudentSore分别获取学号和姓名,用学号来获取集合中学号相同的位置,并将该分数加入该学生的成绩中。设置一个sum用来计算全班总成绩。
//循环获取同学信息
for (int j = 0; j < AllScore.size(); j++) {
//提取学号
String StudentNum = getStudentMess(AllScore, j, 1);
//提取分数
int StudnetScore = getStudentSore(AllScore, j);
//遍历集合
for(Student stu:stulist) {
//获取集合中学号相同的位置
if (stu.getNumber().equals(StudentNum)) {
//将该分数加入该学生的成绩中
stu.setScore(stu.getScore()+StudnetScore);
//累加全班成绩
sum+=StudnetScore;
}
for (int j = 0; j < AllScore.size(); j++) {
//提取学号
String StudentNum = getStudentMess(AllScore, j, 1);
//提取分数
int StudnetScore = getStudentSore(AllScore, j);
//遍历集合
for(Student stu:stulist) {
//获取集合中学号相同的位置
if (stu.getNumber().equals(StudentNum)) {
//将该分数加入该学生的成绩中
stu.setScore(stu.getScore()+StudnetScore);
//累加全班成绩
sum+=StudnetScore;
}
-
④按经验值降序排序集合,并将输出结果保存在txt文件中。
Collections.sort(stulist);//按经验值降序排序集合
//将结果输出到score.txt
//将结果输出到score.txt
//定位txt文件位置</br>
PrintStream pStream = new PrintStream("D:\\Java6375\\Pairing2\\score.txt");</br>
System.setOut(pStream);</br>
//输出最高分,最低分,平均分</br>
System.out.println("最高经验值:"+stulist.get(0).getScore()+", 最低经验值:"+stulist.get(allmess.size()-1).getScore()+", 平均经验</br>值:"+String.format("%.1f", sum/allmess.size()));</br>
for(Student stu:stulist) {System.out.println(stu);}//遍历集合,输出结果</br>
}
-
⑤考虑到有些同学没有交作业,也就没有评分,如下图:
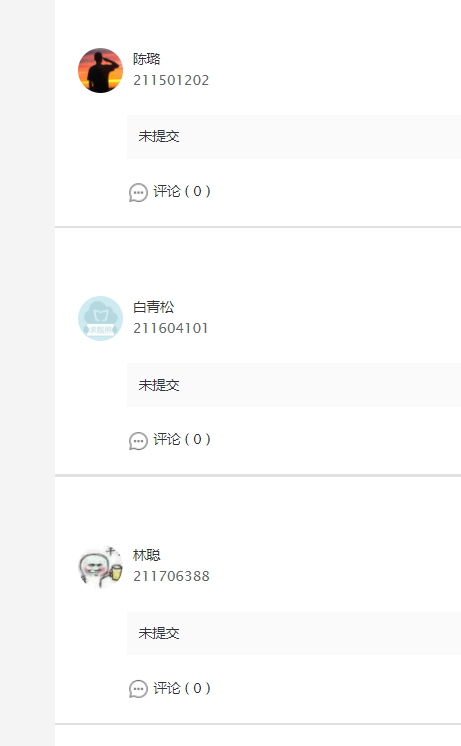
对于这种情况我们进行了操作,若含有尚无评分或者含有批注的,将成绩设为0:
if(text2.contains("尚无评分")||text2.contains("批注")) {
text2="0";
StudentScore=Integer.parseInt(text2);
}
else {
text2=text2.replaceAll("分","").replaceAll(" ","");
StudentScore = Integer.parseInt(text2);
}
return StudentScore;
}
text2="0";
StudentScore=Integer.parseInt(text2);
}
else {
text2=text2.replaceAll("分","").replaceAll(" ","");
StudentScore = Integer.parseInt(text2);
}
return StudentScore;
}
-
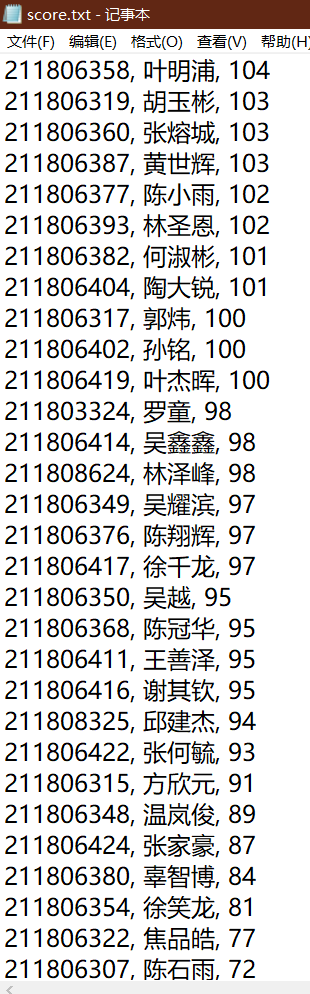
输出效果如下:

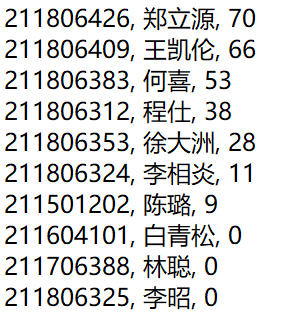
五、学习过程记录
在用jsoup批量获取分页数据的时候,jsoup响应数据默认值为1MB是个坑,所以要重置jsoup的默认爬取范围,代码如下:
public static Document getlogn(String url,String cookie) throws IOException {
Document index = Jsoup.connect(url).header("Cookie", cookie).maxBodySize(Integer.MAX_VALUE).get(); // 设置jsoup爬取页面的数据大小
return index;
Document index = Jsoup.connect(url).header("Cookie", cookie).maxBodySize(Integer.MAX_VALUE).get(); // 设置jsoup爬取页面的数据大小
return index;
六、Commit
七、小结
此次的结对作业对我来说是一个困难也是一个提升,毕竟从需求分析到最后博客写完我和我的队友花了将近七小时的时间,这次编程过程中我们不会的会询问我的隔壁宿舍大佬陈少龙,他总是耐心的为我们解答!在此特别感谢他的帮助,让我能够完成这份作业。在这珍稀的假期中,抽空写作业真是一件令人难过的事情,但我庆幸能在截止时间前写完这份作业,算是一个非常大的收获吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号