第二次结对作业
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11248> |
|---|---|
| 作业目标 | <爬取作业分数,通过txt输出> |
| 作业源代码 | https://gitee.com/zhou-xinyu/pair |
| 周新宇 | <211806361> |
| 卢志伟 | <211806397> |
题目要求
直接通过网络爬取云班课的数据,据经验值排序。通过txt文件输出。
时间分布
| 需求分析| 因为需求已经给定,所以只用了10分钟 |
|编写代码|编写代码的时候集百家之长,所以用时较长,3个小时|
结对过程
由于有个哥哥孤军奋战自己把作业完成了,也就导致我们小组在云班课里没有小组的尴尬情况,不过不急,先把作业完成。
下次一定得先把小组抢到了再说。
互相评价
两个流感患者一边吸溜着鼻涕一边挠头想代码。
周新宇:懒蛋一个
卢志伟:懒蛋一个
学习过程
二十天没用码云,又忘记了怎么添加仓库怎么用。不过不慌,查了一下大佬的教程,再小白的人都会用https://www.cnblogs.com/liuhongyu27/p/13655254.html
写代码实在是为难我们两个,所以打算集百家之长,学习一下别人的思路,看看别人的代码注释。
本来以为一个爬虫这么高大上的东西,实现起来应该很困难吧,不过卡了别人的代码发现,有的大佬用写了92行,有的用了270行。却能实现一样的要求。爷爷是编程的魅力吧
url好说,一个链接搞定。https://www.mosoteach.cn/web/index.php?c=clazzcourse
cookie是什么。。。听都没听说过
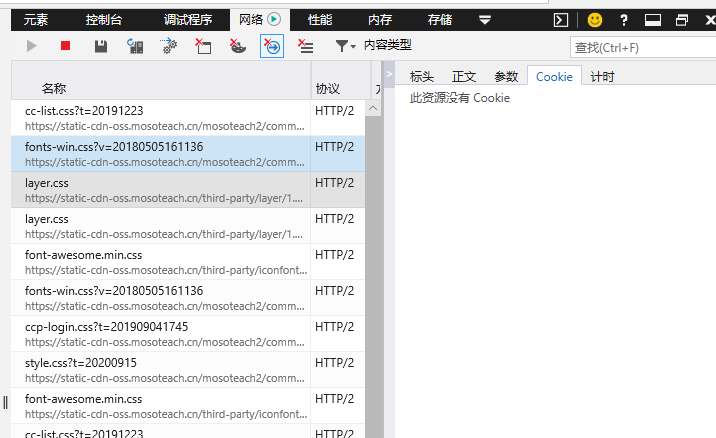
1、打开浏览器,可以使用电脑自带的浏览器合下载的其它浏览器。
2、打开浏览器之后,在出现的网页里点击键盘中的f12键。
3、点击f12键之后,会弹出一个控制台。
4、在控制台的中,找到上面的网络Internet选项并点击它。
5、点击网络后会弹出内容类型的下拉列表,在这个下拉列表中找到文档,并将文档的前面空格勾选起来。
6、点击内容类型中的文档之后,刷新页面,再点击任意详细的文档信息记录,我们就可以看到右侧显示网页的cookies了。
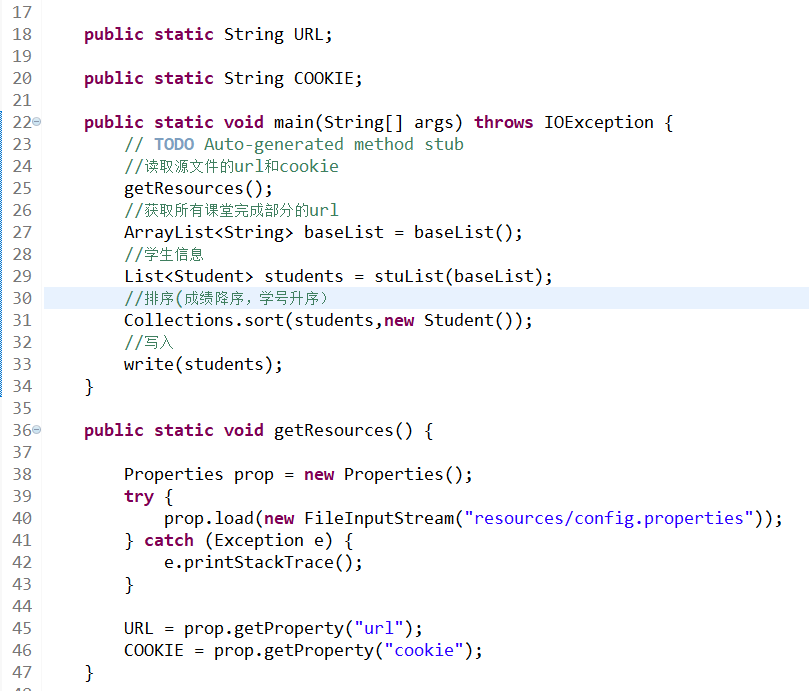
读取源文件的url和cookie,获取所有课堂完成部分的url和学生信息,然后用Collections工具类的sort静态方法将成绩进行排序
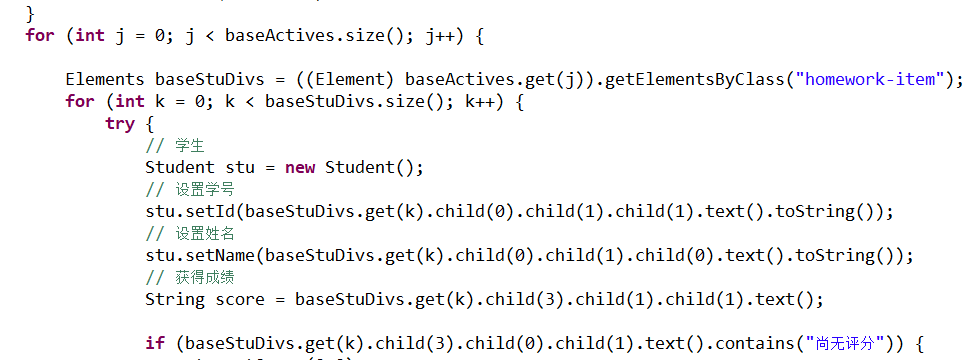
通过类选择器得到一个学生列表
最后生成一个txt文件来记录学生成绩,写入时计算最高分,平均分
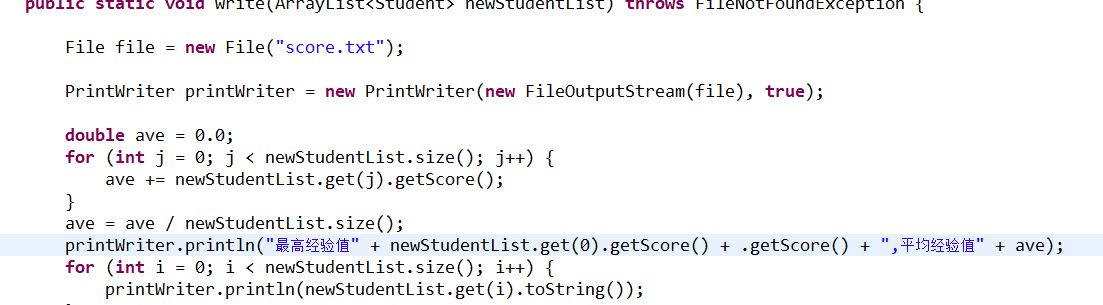
不知道怎么回事,代码没有实现,并没有生成txt文件,可惜可惜。不过已经做到力所能及的事情了。
结对照片
参考资料
大佬的随笔:https://www.cnblogs.com/lrkqcy/p/13766175.html
码云教程:https://www.cnblogs.com/liuhongyu27/p/13655254.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号