


施龙飞--第一次个人编程作业
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | 第一次个人编程作业 |
| 作业目标 | 数据采集与处理,数据可视化--词云图,git的使用 |
| 作业源代码 | first-personal-work |
| 学号 | 211806182 |
一、实验规划
- 时间分布图
| 时间分布 | 分析思路 | 编写代码 | 知识学习 | 编写博客 |
|---|---|---|---|---|
| 20h+ | 6h+ | 10h+ | 5h+ | 1.5h |
终于到了可以写博客的时候(好兴奋?)
二、实验过程
- 采集数据
-
采集腾讯视频里电视剧《在一起》的全部评论信息
好家伙这不就是要用我上学期python学的爬虫吗,所以起先想着用xpath进行入手,走了一段弯路最后还是
决定选择正则(才不是我正则不熟练)同时还是对选择什么技术不大敏感啊。
- 然后分析网页找到规律


- 找到规律就开始准备敲代码了:
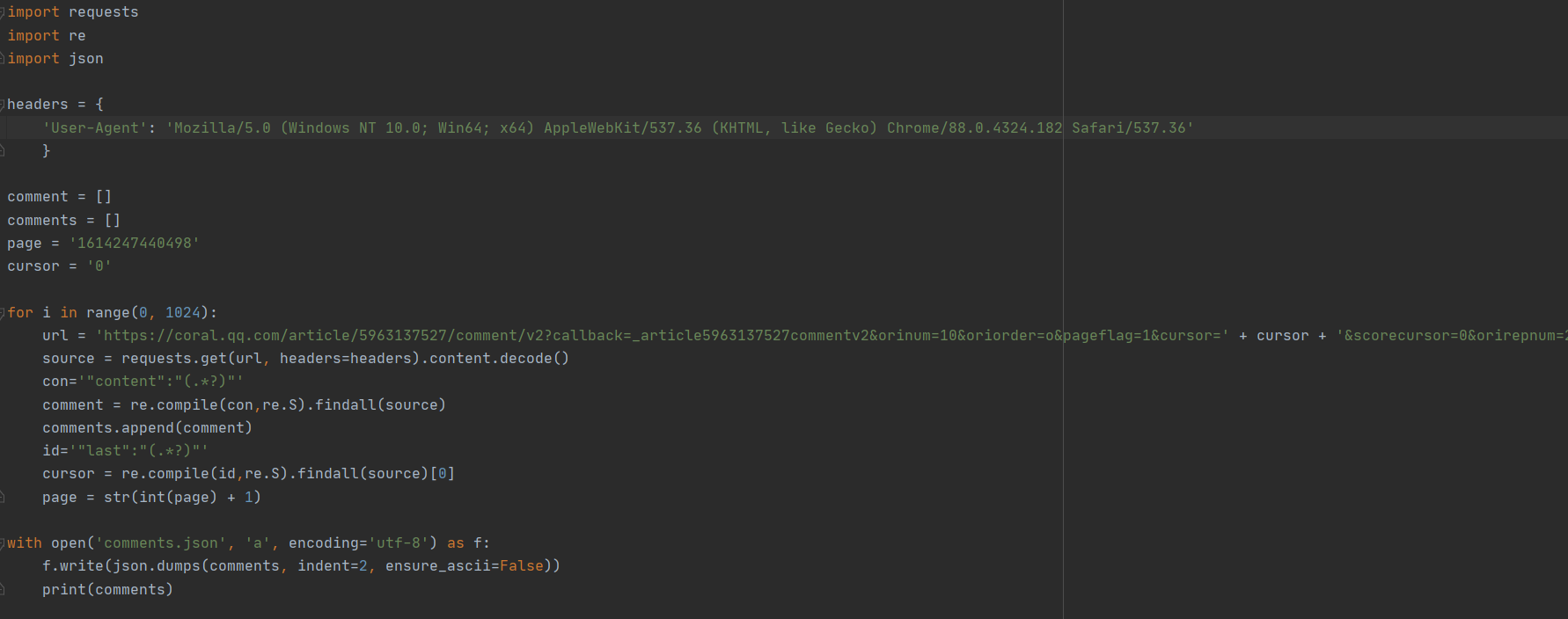
- 最后测试一下发现可以爬出结果,大功告成

- 数据处理
- 看到作业里要求用jieba进行分词,统计评论中的高频词及数量
虽然一点不会那也只能这样了啦,从头开始学呗还能咋的,结果发现自己敲bug贼多,
实在没有办法代码只好借鉴了CSDN的一位大神,这一来一去又是半天。
安装jieba

接下来就是分词的代码啦
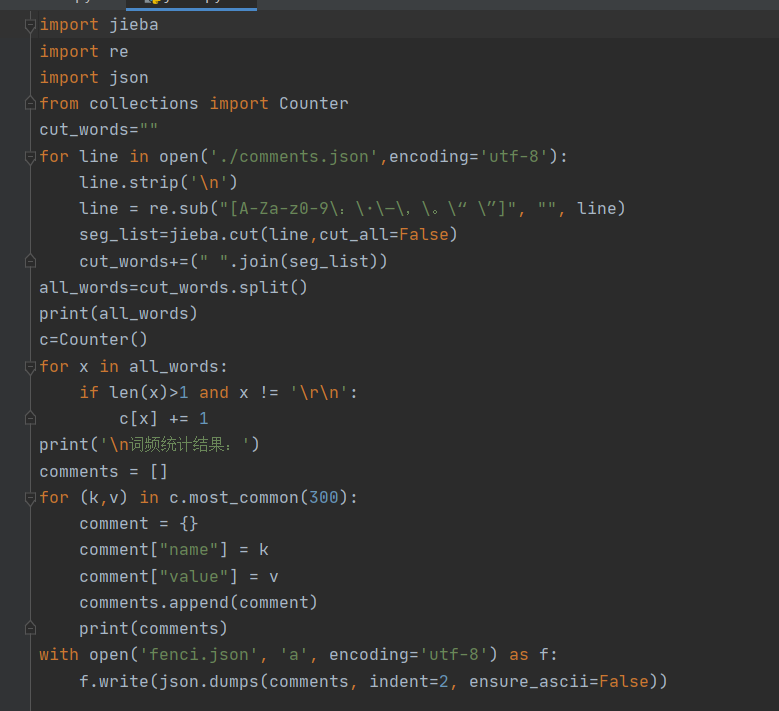
分词的部分结果(看到成功真的要泪流满面)

- 数据分析
- 将采集到的评论信息做成词云图
我真的没想到会栽在这一步,后来证实我做的确实没错,只是因为图片
没错因为图片,让我的词云图没办法显示(悲惨的我五张图都是没办法用的)
这让我一遍又一遍的改代码。后来询问大佬最后做出来了。
在大佬的帮助下结合js插件echarts.js和echarts-wordcloud.min.js完成index.html
安装wordcloud
词云图原型

词云图
因为觉得花象征着那些医生护士心灵的美好(虽然一个大男人选花怪怪的)

三、GitHub上传代码
-
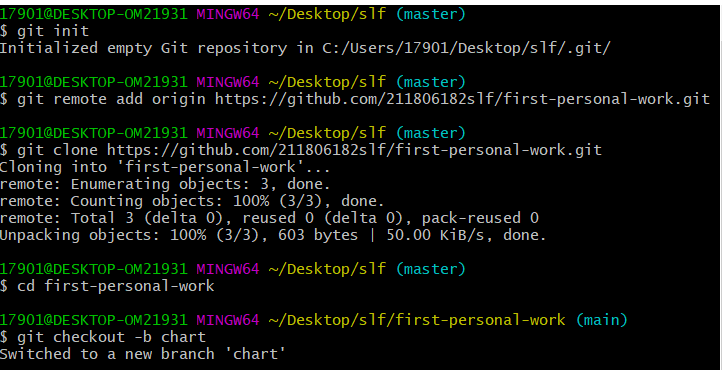
git init 初始化 (此步前记得在提交文件右键来GIT BASH)
![]()
-
git remote add origin + 仓库地址(连接仓库。)
-
git clone + 仓库地址 (将远程仓库的内容克隆到本地仓库。)
-
cd first-personal-work 进入文件夹。(注意上传的文件的要移入到此文件夹)
-
git checkout -b crawl (切换分支)注:注意加-b 否则会出错
![]()
-
git add + 文件名 (将文件添加到暂存区)
![]()
-
git commit -m + "注释" (给提交上去的文件加上注释,最好每一份都要有注释 以此类推每个文件提交一次注释一次这里提交了n次 )
![]()
-
git push -u origin crawl (推送到远程仓库)
![]()
-
git checkout main,切换回主分支
分别git merge crawl 和 git merge chart合并分支
10.git push(大功告成)
![]()


四、经验总结
1.此次实验让我加强了对自己认知,本来以为两天能搞定的我磨磨唧唧拖到现在。自己还有很多地方比较薄弱,基础也不是很好,还是要多学习啊
2.这次实验也让我知道烦躁确实对事情毫无帮助,有时候真的应该静静地想想。很多东西也要对自己有自信一点,不要一点挫折就否定自己。
3.希望以后多学点前端知识,以前业余时间学的前端是真不够用。虽然此次遇到了不少难题但是还是有一点收获的。
ps:(希望没有寒假作业了)
五、参考文献
python爬虫学习笔记(一)—— 爬取腾讯视频影评
jieba“结巴”中文分词:做最好的 Python 中文分词组件
echarts实现词云自定义形状的示例代码
Commit message 和 Change log 编写指南

 浙公网安备 33010602011771号
浙公网安备 33010602011771号