蔡泽渊---第一次个人编程作业
作业介绍
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 爬取腾讯视频《在一起》评论,并进行分词及统计,最后以词云图的形式展现在HTML,并上传到Github |
| 作业源代码 | 作业链接 |
| 学号 | 211806154 |
时间安排
| 步骤 | 花费时间 |
|---|---|
| 爬取评论数据 | 3h |
| 使用jieba分词进行分词并统计数量 | 2h |
| 将处理完的数据在hbuilder上制成词云图 | 5h |
| 上传到远程仓库Github | 2h |
具体步骤
1.数据采集
首先进入链接 腾讯视频《在一起》 后发现,点击
可以获取全部评论信息。
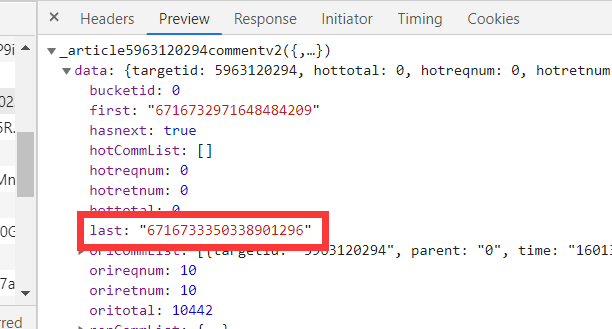
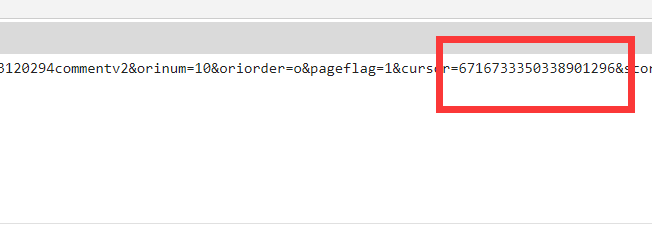
进入全部评论信息F12打开开发者模式,通过点击更多评论,发现规律即请求URL 中只有 cursor 和 source 进行了改变,其他是不变的,而cursor为上一页最后一名用户的 id,source则是依次加一。
cursor
source
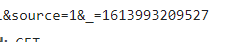
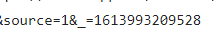
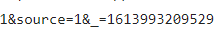
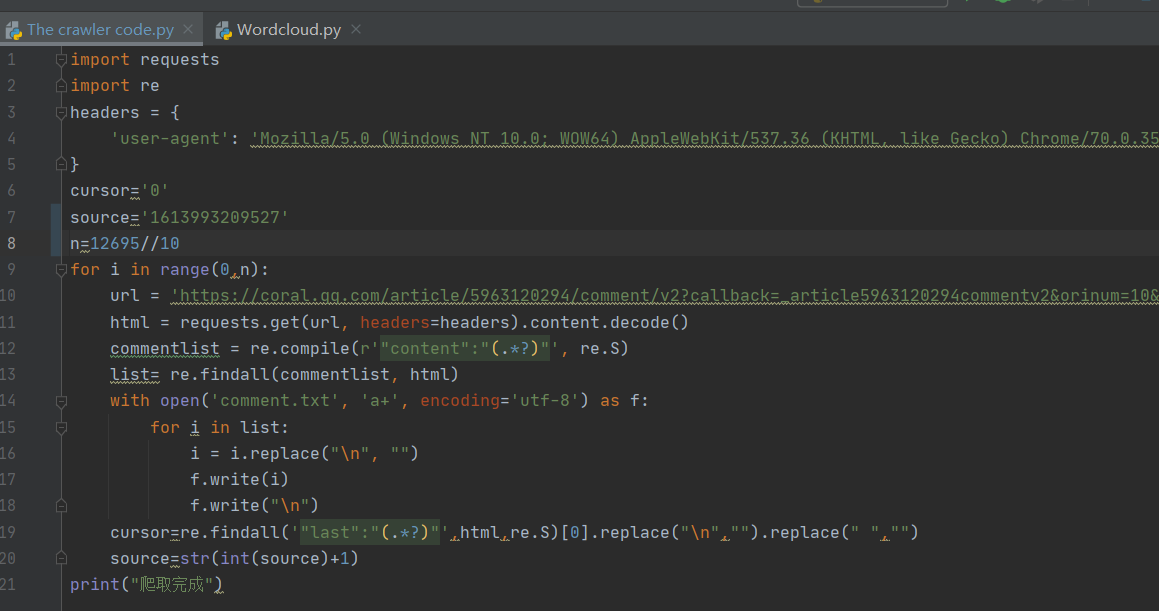
找到规律后,参考了下模板,开始编写代码。
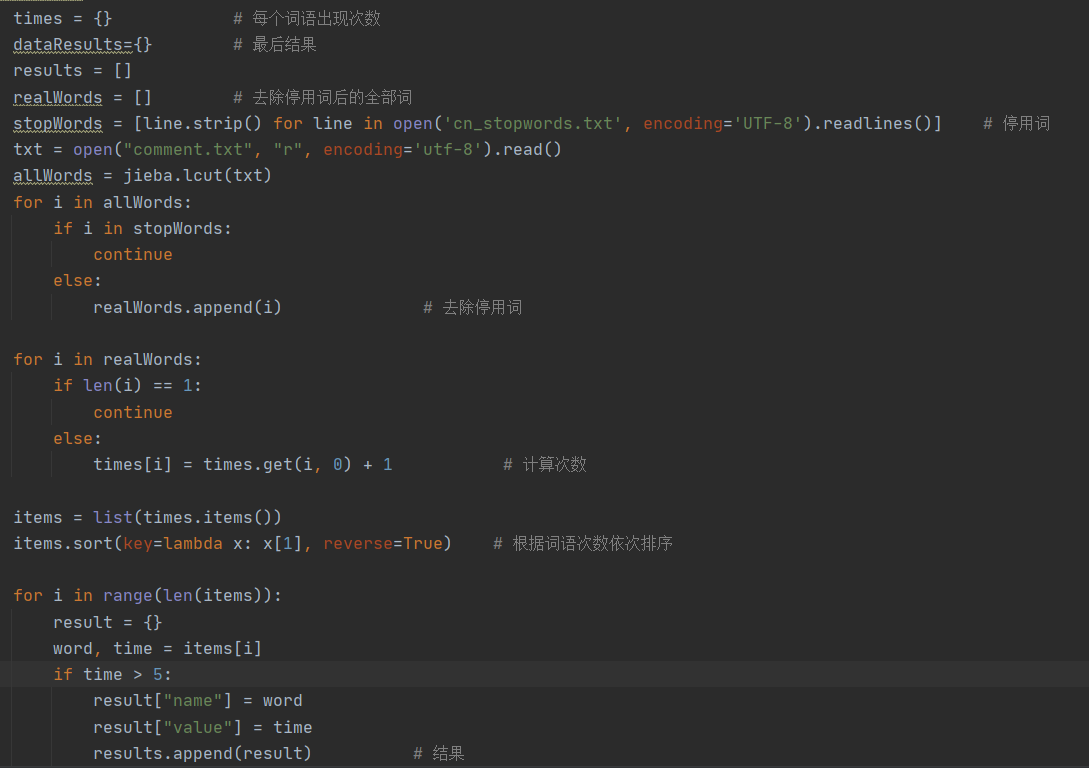
2.数据处理
导入jieba分词库进行分词处理,接着在github 这儿这儿 里面找到国内常用停用词表,去除停用词,最后按每个词的次数依次排列。
3.数据分析展示
由于没有学过前端,花了很长时间对echarts.js进行了解。通过github导入了三个文件echarts.min.js,echarts.wordcloud.js,jquery.min.js。接着查找了相关代码模板,套入完成!

4.上传至Github
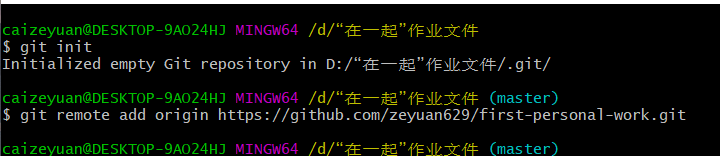
(1)创建并连接至github
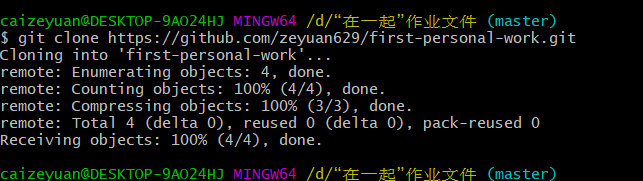
(2)克隆github至本地
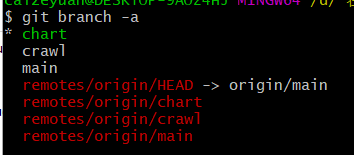
(3)创建分支
(4)写完的文件add并commit

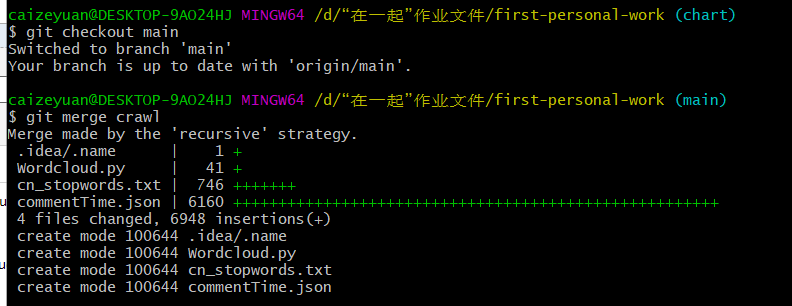
(5)合并上传至远程仓库


5.遇到的问题
(1)经过春节洗礼后,爬虫知识忘了一大半,刚开始上手一脸懵。
(2)一开始分词处理不知道要处理成什么样的数据。
(3)第一次编写词云图,本来度娘后直接用python库直接生成html,后来助教在群里提醒后重新学习了echarts.js进行修改。
6.参考资料
“结巴”中文分词:做最好的 Python 中文分词组件
echarts.js
echarts-wordcloud
commit规范

 浙公网安备 33010602011771号
浙公网安备 33010602011771号