

张天池---第一次个人编程作业
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 运用Git,灵活运用数据采集分析方法,以及可视化等 |
| 作业源代码 | 在这儿呢,这儿 |
| 学号 | 211806144 |
时间记录
| 数据采集 | Ajax异步抓包 | 1.5H |
|---|---|---|
| 数据处理词频统计 | jieba分析数据 | 4.5H |
| 绘制词云图 | 4H |
统计记录
| 代码行数 | 110行 |
|---|---|
| 需求分析时间 | 0.5H |
| 编码时间 | 15H |
过程分析
首先用chrome浏览器打开腾讯视频《在一起》评论页面(不出所料,猜到了这个是下拉型,首先瞄准了Ajax异步爬取)
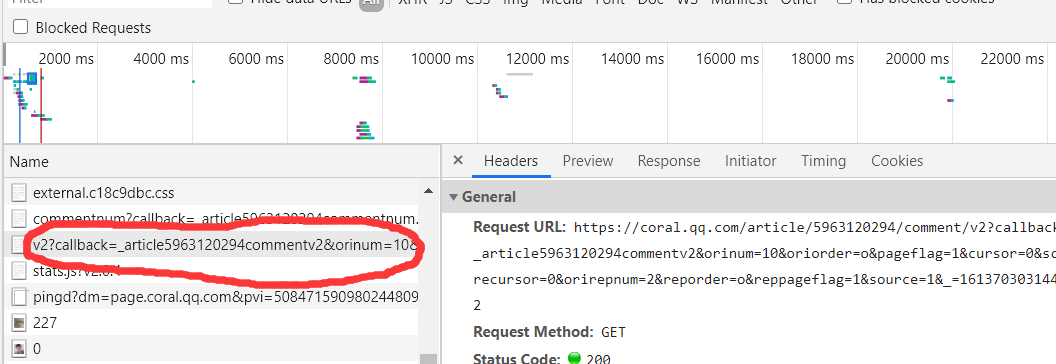

仔细观察发现,我们发现url两处不同的地方,就是上图的这个v2?=和cursor,下拉发现每一次点击更多评论的下拉框按钮都会出现相应的v2?标签,点开发现了规律,也就是你每翻到下一页的评论url的末尾那一串数字会+1,可是cursor的规律还是没有找到,于是决定去js里面查找,复制其中一个url打开,结果可以说是非常amazing,多试了几次终于发现规律:cursor=?的值存在上面一个JS中

开爬!!!
这里吐槽一句,还是pycharm用的顺手一点,功能贼全,安装库也很简单轻松,spyder和jupyter就算了吧,哈哈...
代码如下,相关知识有些忘了,参考了一下别的大佬的,这里截取我的一部分代码
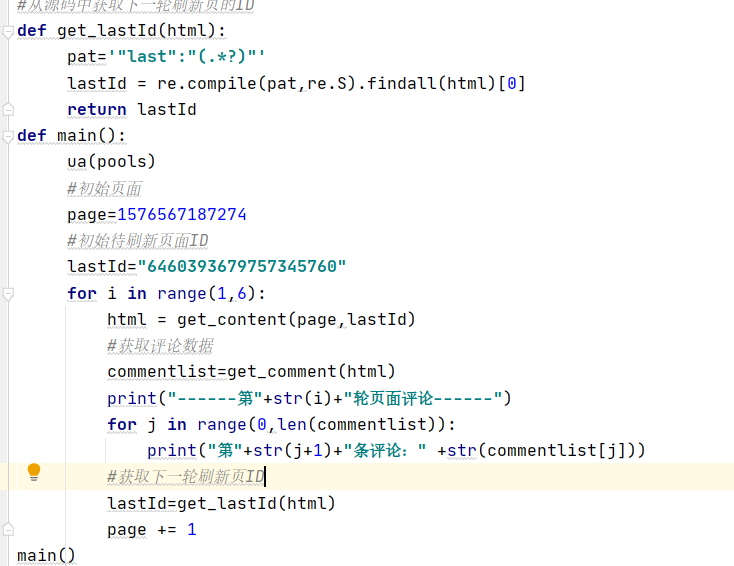
此时遇到了一些问题,每个页面的第一条爬取不成功,会自动跳到第二条进行爬取,更改了一下j变量为变量j+1
成功爬取相关评论,爬取结束!!!
开始进行数据分析,词条统计,并绘制词云图
注:其实并不一定需要进行词条统计,另一种思路,可以先将评论爬出来,将评论中多余的字符撇去,一样可以进行词云图绘制
关键代码:

这样子就把相关的词频统计出来了,但是之后我用了一种方法出现的词云图会出现问题,就是出现的词的数量并不多如下:

这样子太少了,对比一下其他同学的感觉自己就是个弟弟
所以换了一个代码,并简略了一下,将统计词频与绘制词云图函数功能放在了一起,我用了推特鸟的呈现效果,还是不错的,最终呈现如下效果:

但是老师规定的是要用echarts,所以在参考了相关代码后还是要用词频统计代码进行操作,键值对形式将词频输出,说是用导出json,用sublime最终在页面中呈现效果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号