20192103 2020-2021-2 《Python程序设计》实验四报告
20192103 2020-2021-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1921
姓名: 刘廷奇
学号:20192103
实验教师:王志强
实验日期:2021年6月24日
必修/选修: 公选课
一、实验内容
- Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
二、实验过程
1. 概念理解:
(1)词袋模型
词袋模型(Bag-of-words model),像是句子或是文件这样的文字可以用一个袋子装着这些词的方式表现,这种表现方式不考虑文法以及词的顺序。
文档的向量表示可以直接将各词的词向量表示加和。例如:
John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典,**{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10} **
那么第一句的向量表示为:[1,2,1,1,1,0,0,0,1,1],其中的2表示likes在该句中出现了2次,依次类推。
词袋模型同样有一下缺点:
- 词向量化后,词与词之间是有大小关系的,不一定词出现的越多,权重越大。
- 词与词之间是没有顺序关系的。
(2)连续词汇(CBOW)学习
在连续的单词模型中,上下文由给定目标单词的多个单词表示。例如,我们可以使用“cat”和“tree”作为“攀爬”的上下文单词作为目标单词。这需要修改神经网络架构。如下所示,修改包括将隐藏层连接的输入复制C次,上下文单词的数量,以及在隐藏层神经元中添加除C操作。[警报读者指出,下图可能会让一些读者认为CBOW学习使用了几个输入矩阵。不是这样。它是相同的矩阵WI,它接收代表不同上下文词的多个输入向量]
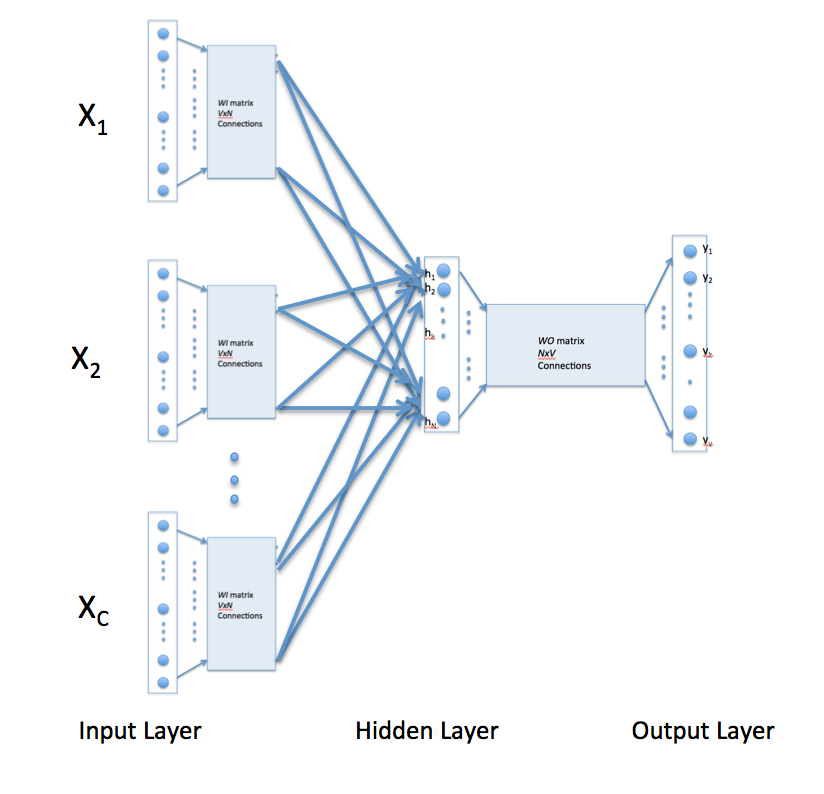
利用上述配置来指定C上下文字,使用1-out-of-V表示编码的每个字意味着隐藏层输出是与输入处的上下文字相对应的字矢量的平均值。输出层保持不变,并且以上面讨论的方式完成训练。
(3)Skip-Gram模型
Skip-gram模型反转了目标和上下文单词的使用。在这种情况下,目标字在输入处被馈送,隐藏层保持相同,并且神经网络的输出层被多次复制以适应所选数量的上下文字。以“cat”和“tree”为例,作为上下文单词,“爬”作为目标词,skim-gram模型中的输入向量为[0 0 0 1 0 0 0 0] t,而两个输出层将具有[0 1 0 0 0 0 0 0] t和[0 0 0 0 0 0 0 1] t分别作为目标向量。代替产生一个概率向量,将为当前示例产生两个这样的向量。以上面讨论的方式产生每个输出层的误差向量。然而,将来自所有输出层的误差向量相加以通过反向传播来调整权重。这确保了每个输出层的权重矩阵WO在整个训练中保持相同。
2. 使用CBOW模型,分析莎士比亚文选中的词汇:
(1)准备材料并作预料清洗:
由于材料中存在非英文单词的其他字符,所以需要先对其进行清洗得到需要的单词文本。
# -*- coding:utf-8 -*-
"""
作者:亦 皓
时间:2021年06月21日
"""
import re
my_file_path = 'shakespeare.txt'
save_file_path = 'shakespeare_cleaned.txt'
# 打开文件
my_file = open(my_file_path, 'r', encoding='utf-8')
# 只保留中英文、数字和.的正则表达式
cop = re.compile("[^\u4e00-\u9fa5^.^a-z^A-Z^0-9]")
line_num=1
for line in my_file.readlines():
print('---- processing ', line_num, ' article----------------')
line_num=line_num+1
string = cop.sub(" ", line)
save_file = open(save_file_path, 'a', encoding='utf-8')
save_file.write(string)
save_file.flush()
save_file.close()
# 关闭文件
my_file.close()

(2)gensim训练词向量模型:
gensim训练词向量分为三步,第一步获取sentences,第二部设置超参数,第三步模型保存。
<1> 获取sentences:直接读取shakespeare_cleaned.txt文件,sentences是已经分词过的字符串列表,其为一维数组。
<2> 设置超参数:word2vec模型的超参数如下所示:
model = word2vec.Word2Vec(sentences, hs=1, min_count=1, window=5, size=200)
- sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
- size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
- window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为c,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
- sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
- hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
- min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
<3> 模型保存
# -*- coding:utf-8 -*- """ 作者:亦 皓 时间:2021年06月16日 """ # import modules & set up logging shakespeare import logging import os from gensim.models import word2vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = word2vec.LineSentence('./shakespeare_cleaned.txt') model = word2vec.Word2Vec(sentences, hs=1, min_count=1, window=5, size=200) model.save("shakespeare.model")
(3)调用词向量模型进行测试:
1、相似性
持数种单词相似度任务:
相似词+相似系数(model.most_similar)、model.doesnt_match、model.similarity(两两相似)
2、词向量
通过以下方式来得到单词的向量:
1 # -*- coding:utf-8 -*- 2 """ 3 作者:亦 皓 4 时间:2021年02月16日 5 """ 6 from gensim.models import Word2Vec 7 8 model = Word2Vec.load("shakespeare.model") # 导入训练好的model 9 print("测试1# 单词 honest,love 的相似词中相似率最高的为:", model.wv.most_similar(positive=['honest', 'love'], topn=1)) 10 11 print("测试2# First Better greatest lunch 中差别最大的词为:", model.wv.doesnt_match("First Better greatest lunch".split())) 12 13 print("测试3# honours, Whether的相似度为:", model.wv.similarity('honours', 'Whether')) 14 15 print("测试4# 输出fight的近似词:") 16 for key in model.wv.similar_by_word("fight", topn=5): 17 print(key[0], key[1]) 18 print("测试5# 输出的向量:", model.wv.__getitem__('Better'))
结果显示:
测试1# 单词 honest,love 的相似词中相似率最高的为: [('lies', 0.9200366139411926)] 测试2# First Better greatest lunch 中差别最大的词为: greatest 测试3# honours, Whether的相似度为: 0.43724662 测试4# 输出fight的近似词: last 0.9451447129249573 put 0.9314762353897095 watchful 0.9188637733459473 heaven 0.9185464382171631 command 0.9172909259796143 测试5# 输出的向量: [-0.06699569 0.01617903 0.01823069 0.04562613 0.02445887 0.00284738 -0.03371223 -0.09672338 0.01900439 0.01873839 0.00463057 0.02441882 0.03263871 -0.00094737 0.0446073 -0.03870494 -0.04102157 -0.01287576 0.04451469 0.05489408 -0.00789456 -0.0279666 -0.00838227 0.00983625 -0.01237774 -0.01247551 -0.0290442 -0.01552401 0.03309647 0.07312648 0.03531109 0.00187926 0.05684604 -0.01280195 0.01841912 0.03781545 -0.01112699 0.03274786 -0.02836249 -0.03545839 -0.02025985 -0.03461348 -0.04703348 0.08335583 0.02305591 -0.02907482 -0.06440009 0.05557092 0.02365478 0.02517412 -0.06268574 0.02495834 -0.02806567 -0.04015472 -0.0161448 -0.07507759 0.02799249 0.00547924 -0.05197961 0.03000016 0.084795 -0.02090319 0.00349557 -0.03505312 -0.02232206 -0.03817129 0.05356568 -0.03535968 0.0284666 -0.01798884 0.00929409 -0.03288862 0.03720145 -0.02298678 0.03213813 0.05708868 -0.0102173 0.03067191 -0.00203374 0.02259132 0.02428583 0.06176442 -0.01030927 -0.04594169 0.00308089 -0.01238897 0.02096123 -0.00909929 -0.04792728 0.1344735 -0.04238546 0.04237226 -0.06910371 -0.04969184 -0.08321558 -0.01235363 -0.05850493 0.08172184 -0.12042347 0.03568861 -0.01371954 -0.08182655 -0.01754959 0.04139086 0.02987615 -0.00909976 -0.0423135 0.1070986 -0.01270053 -0.05330019 0.03727992 0.0483785 -0.04232701 0.01060789 0.00495224 -0.008589 -0.06342883 0.00820889 -0.0170385 -0.03921989 -0.02200507 -0.00548373 -0.02671601 0.00962604 -0.03535017 0.06872729 -0.05534382 -0.10688455 -0.01219376 -0.0857593 0.01900148 -0.01204819 -0.04688123 -0.00704413 -0.00978228 0.0111156 0.00578401 -0.05683793 -0.01376251 -0.01436697 0.0608184 -0.04045716 -0.03128746 -0.0541997 0.00266912 -0.00560187 0.04679392 -0.0068001 0.02903086 -0.01399632 0.02934035 0.00378431 -0.00330732 -0.04056502 -0.01079299 0.03196225 0.02427186 0.03629823 0.03135628 0.00360445 0.02142306 -0.020002 -0.03829349 0.04249463 -0.05141458 -0.01234756 0.04370045 0.03112992 -0.02176946 0.03934734 -0.00982814 0.03035656 -0.01511338 -0.00585528 -0.03257927 0.01247251 -0.02951111 -0.01081949 0.01928993 0.02217238 -0.03827615 -0.04731882 -0.0077866 0.0230904 0.01569317 -0.01079687 -0.00130575 0.0304474 0.03601635 0.01544886 -0.02586186 0.01181022 -0.01027526 0.00524375 -0.11492699 -0.02224771 0.03087084 0.07214064 -0.01901922 0.04930056]
三、实验中遇到的问题
问题一:学习词向量时涉及到神经网络模型的很多概念不清楚,比如隐层,反向传播等。
解决方法:对于影响整体理解的内容要花时间去看视频讲解,在公式推导过程中要保持耐心,虽然最终不能理解其中迭代的、反向传播的公式计算部分,但做到能够理解参数的含义。
问题二:参考资料和现在使用的库版本不同。
解决方法:最初下载安装好gensim、RNN等库后,写一些样例代码就全片飞红,需要去阅读错误提示,之后去网站上查找最新的库函数来代替旧的函数。
四、本实验代码链接及参考资料
https://gitee.com/liu-tingqi/PythonWork/tree/master/lab4
https://blog.csdn.net/qq_36426650/article/details/87738919
五、课程体会
python课让我找到了CS专业学生的感觉——写代码、学技能、知方向,而不是天天写ppt和word,到了课后实验需要自己花大量时间去从零初学。python的课程从简开始,我可以跟得上老师的进度还是要感谢老师给的宝藏资料,课堂上直接以代码来讲解切实解决了我们实践上将会遇到的问题,让我们在课下时间有信心去自己重写代码,回忆老师的思路,回顾上课的内容。学习的过程在于自己动手的过程,本学期老师布置了适当量的实践作业,从学习python的基本操作,到网络编程,再到网络爬虫,也给了我们充分的时间来独立完成。在这门课上我的收获很多,欣喜~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号