作业12-流与文件
- 本周学习总结
1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容。
- 字节流读文件结束的判断方法,可以使用
abstract int read()返回-1为结束,也可以使用捕获错误的方法,当捕获到EOFException错误是为结束。 - 使用缓冲流一定要使用flush方法或者close方法,否则内容只是在缓冲流中并未真正写入文件中,有些时候也可以设置autoflush。
- 正则表达式的使用:
Pattern pattern=Pattern.compile("正则表达式");//编译正则表达式到模式中
Matcher matcher=pattern.matcher(输入内容str);//创建输入内容与模式的匹配器
matcher.matches();//判断匹配器是否匹配成功
- 正则表达式的使用带来很多便利,例如判断是否是合法QQ号是可以使用
^[1-9]*[1-9][0-9]*$,是否是合法邮箱的时候可以使用\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*是否是合法IP可以使用(\d+)\.(\d+)\.(\d+)\.(\d+)等等。 - 采用不同的编码解码方式会产生乱码:OS的默认解码集是GBK,如果遇到UTF-8编码的文件读取是可以InputStreamRead指定解码方式。
- 字节流InputStream与OutputStream是按照字节来处理的,一般int型占4字节,double型占8字节,纯英文的字符串一个字符一个字节,如果包含汉字的话,得看编码方式,如果是GBK编码,那一个汉字两个字节,如果是UTF-8编码的话一个汉字三个字节。
- 字符流Writer与Reader是按照字符来处理的,纯英文的话一个字符就是一个字节,汉字的话同上。
- 面向系统综合设计-图书馆管理系统或购物车
使用流与文件改造你的图书馆管理系统或购物车。
2.1 简述如何使用流与文件改造你的系统。文件中数据的格式如何?
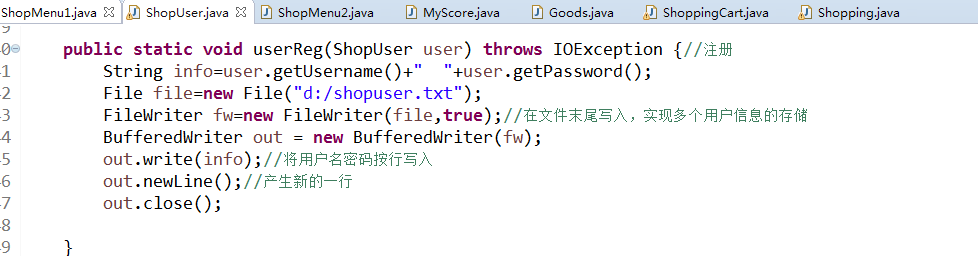
答:使用缓冲流BufferedWriter与BufferedReader写与读实现ShopUser这个类的登陆注册方法。文件中的格式是用户名 密码.如下: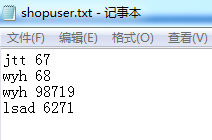
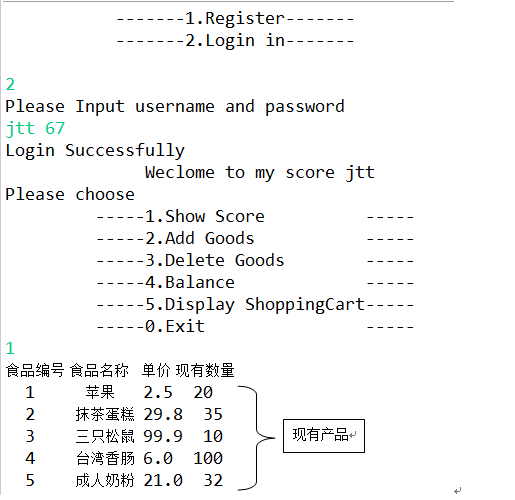
使用数据流DataOutputStream和DataInputStream初始化该商店里所有的商品。试想用户只要在购买商品的时候输入产品编号和数量就可以在该文件中查找到商品名称与单价。但是没有成功。购买商品时还是采取输入编号,名称,单价和数量的方法。如下将显示运行之后输出的所有产品。(作的过程中让我想到其实还有一类用户登录该购物系统,那就是卖家,他能够对该商品文件操作。这次还未完成。)
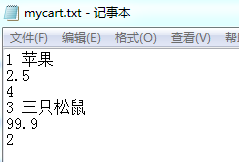
同样使用BufferedWriter与BufferedReader写与读我的购物车中的内容。其中的格式是
产品编号 产品名称
产品单价
产品数量
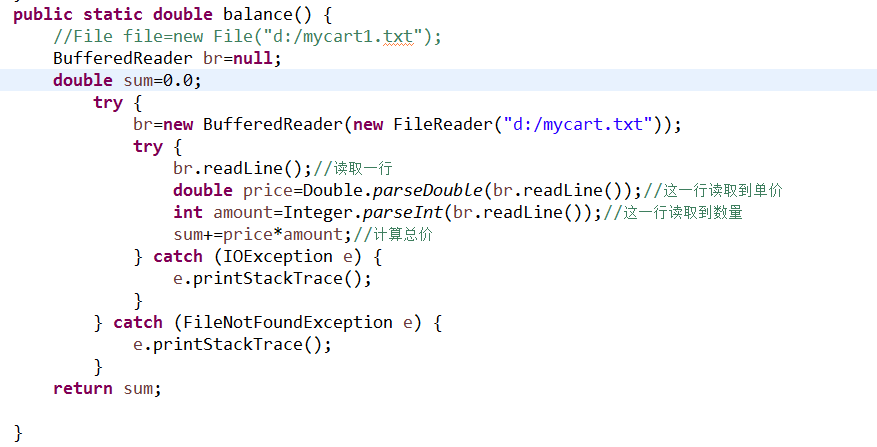
这样设计是为了在结算的时候可以在读取第二行的时候记录下单价,读取第三行的时候记录下数量。
2.2 简述系统中文件读写部分使用了流与文件相关的什么接口与类?为什么要用这些接口与类?
答:使用了DataOutput接口下的DataOutputStream与DataInput接口下的DataInputStream,使用这两个类初始化了当前商店里所有的商品,起初是想着这样可以分段获取商品的属性信息。
使用了BufferedReader与BufferedWriter类,是为了将我所购的东西存储在文件中并读取出来和存储和读取用户的帐号密码信息。因为其中有newLine方法,还联合使用了FileWriter类中的public FileWriter(File file, boolean append)方法,可以实现多次写入文件。
2.3 截图读写文件相关代码。关键行需要加注释。
登陆注册方法的实现

现有产品的初始化


添加商品

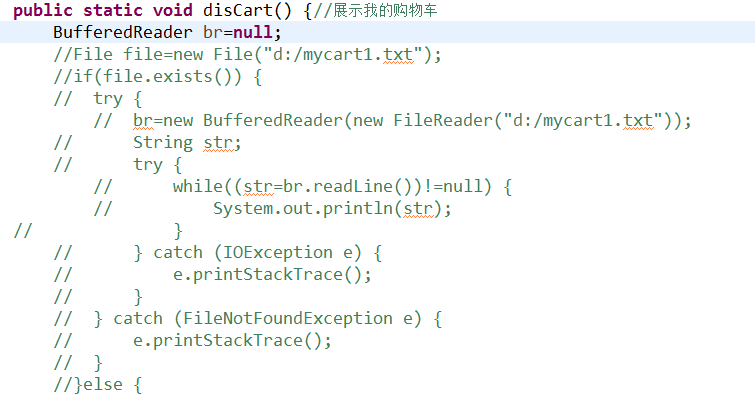
展示我的购物车
其中还有一个删除方法,不知道如何删除文件中的某一行,所以想着使用复制文件的方法,修改后的购物车信息放入文件mycart1.txt,之后的展示购物车和结算将判断下是否存在修改之后的文件,但是目前还未成功。所以现有功能只有添加,展示,结算功能。

结算
- 代码量统计
3.1 统计本周完成的代码量
| 周次 | 总代码量 | 新增代码量 | 总文件数 | 新增文件数 |
|---|---|---|---|---|
| 13 | 1043 | 1043 | 14 | 14 |
5(选做)流与文件学习指导
5-1 字符流与文本文件:使用 PrintWriter(写),BufferedReader(读)
将Student对象(属性:int id, String name,int age,double grade)写入文件student.data、从文件读出显示。
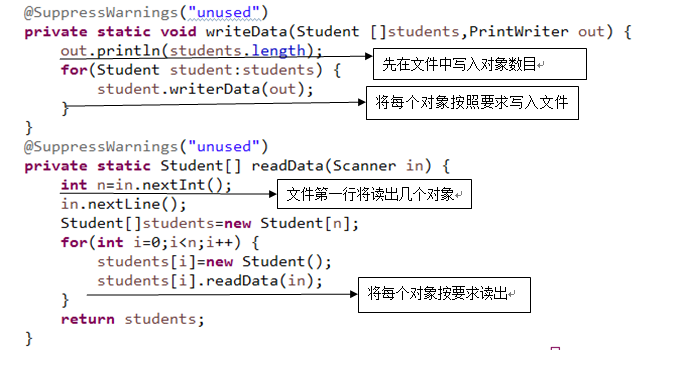
5.1.1生成的三个学生对象,使用PrintWriter的println方法写入student.txt,每行一个学生,学生的每个属性之间用|作为分隔。使用Scanner或者BufferedReader将student.txt的数据读出。(截图关键代码,出现学号)


运行结果

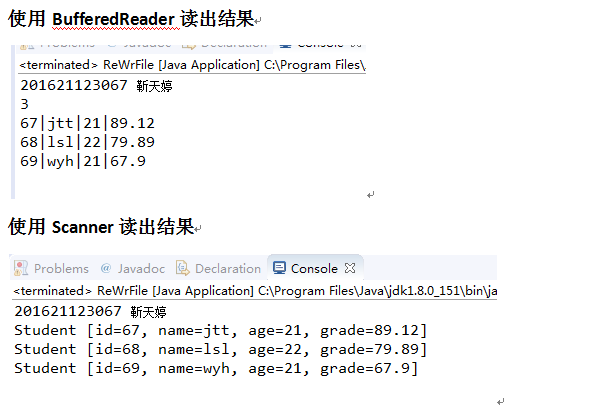
5.1.2生成文件大小多少(使用右键文件属性查看)?分析该文件大小
答:生成的文件有53字节,因为文件中总共有53个字符,包括每一行的回车和换行,又没有中文汉字,ASCII编码一个字符就是一字节,所以文件为53字节。
5.1.3如果调用PrintWriter的println方法,但在后面不close。文件大小是多少?为什么?
答:文件大小为零字节。因为创建的PrintWriter是不带自动行刷新的Writer,不使用close或者flush就不会刷新流的缓冲,就不会将内容写进文件中。我们可以添加语句out.flush();或者创建带自动行刷新的Writer。如下:
PrintWriter out=new PrintWriter("D:\\student.txt");
PrintWriter out1=new PrintWriter(out,true);
writeData(students,out1);

5-2缓冲流
5.2.1 使用PrintWriter往文件里写入1千万行(随便什么内容都行),然后对比使用BufferedReader与使用Scanner从该文件中读取数据的速度(只读取,不输出),使用哪种方法快?截取测试源代码,出现学号。请详细分析原因?提示:可以使用junit4对比运行时间

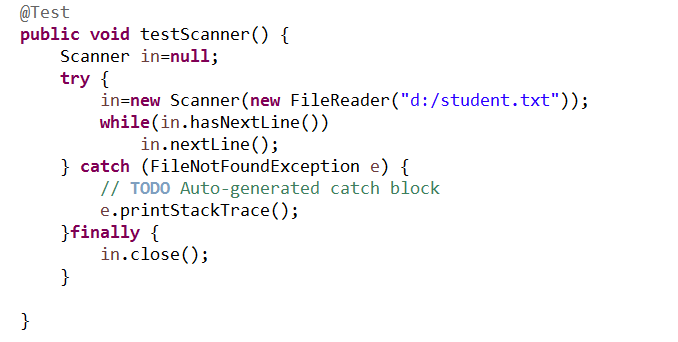
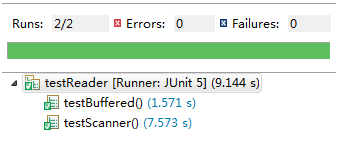
答:从以上截图可以看出使用BufferedReader读取文件比使用Scanner读取文件快。因为:BufferedReader是在字符输入流中读取文件,可以缓冲每个字符,从而可以高效的读取行,而Scanner需要一个一个字符扫描过去,遇到空格才获取下一行,因此速率远远慢于BufferedReader。
5.2.2 将PrintWriter换成BufferedWriter,观察写入文件的速度是否有提升。记录两者的运行时间。试分析原因。


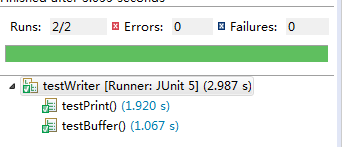
答:换成BufferedWriter之后,写入文件的速度有些许提升。
5-3字符编码
5.3.1 现有EncodeTest.txt 文件,包含一些中文,该文件使用UTF-8编码。使用FileReader与BufferedReader将EncodeTest.txt的文本读入并输出。是否有乱码?为什么会有乱码?如何解决?(截图关键代码,出现学号)
答:有乱码。因为文件读入的时候是按照OS的默认字符集,也就是GBK解码的,而文件用UTF-8编码,这样编码方式与解码方式不同就会产生乱码。

解决办法:我们可以先将读入的字符集用GBK编码然后在用UTF-8解码,这样应该就恢复为原字符了,直接输出。
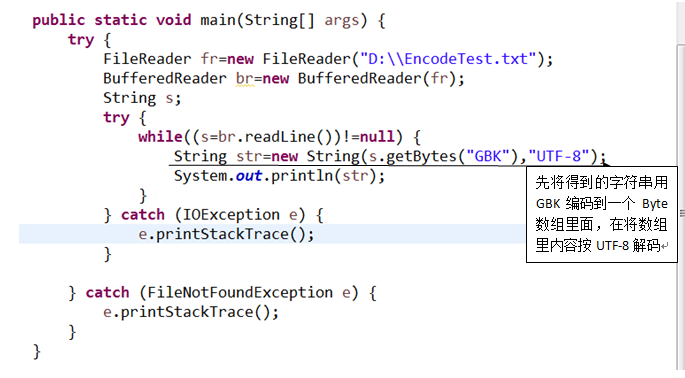
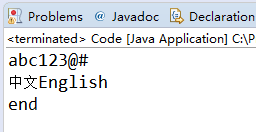
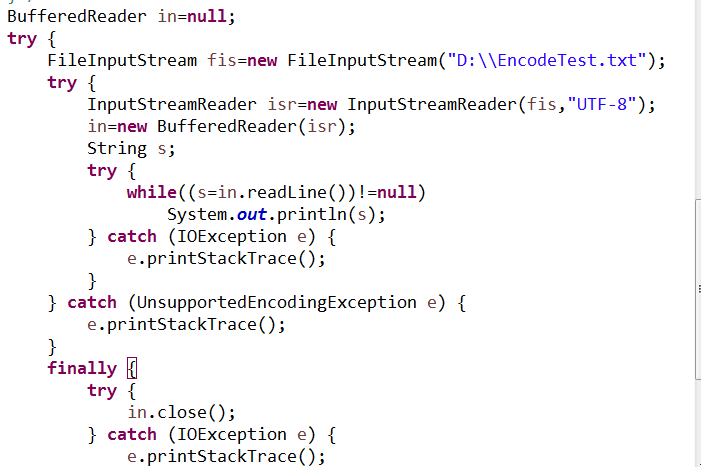
似乎这种方法并不是每种情况都是用,最好的办法还是用InputStreamReader取代FileReader,使用其中的方法直接指定解码方式,不必在编码解码方式中变化。
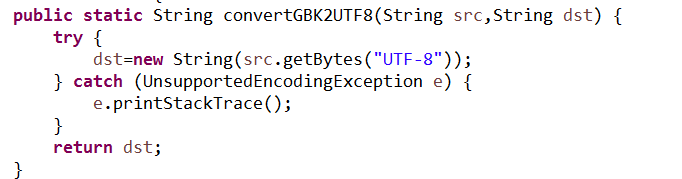
5.3.2 编写方法convertGBK2UTF8(String src, String dst),可以将以GBK编码的源文件src转换成以UTF8编码的目的文件dst。

5-4字节流、二进制文件:DataInputStream, DataOutputStream、ObjectInputStream
5.4.1 参考DataStream目录相关代码,尝试将三个学生对象的数据写入文件,然后从文件读出并显示。(截图关键代码,出现学号)
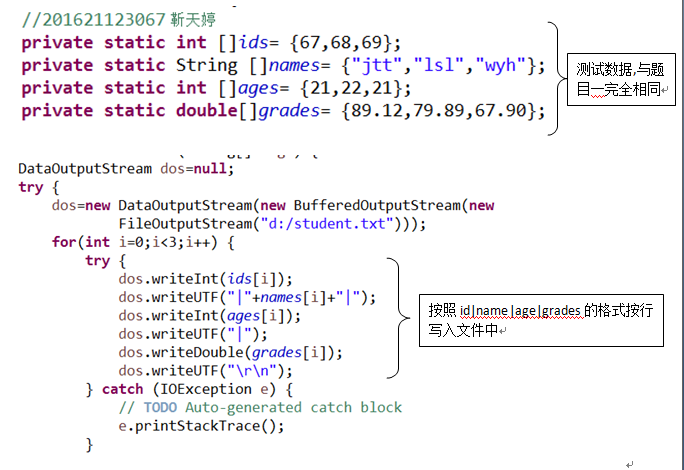


5.4.2 这里生成的文件和题目1生成的文件有何不一样?生成的文件有多大?分析该文件大小?将该文件大小和题目1生成的文件对比是大了还是小了,为什么?存储数据的时候,到底是二进制文件比较节省空间还是文本文件比较节省空间?使用二进制存储文件有何好处?
答:这里生成的文件是二进制文件,题目一生成的文件是文本文件。保持这次文件内容与上次文件内容相同的情况下题目一文件有50字节,这次生成的文件为90字节。相比较来看文件大了.因为PrintWriter字符流写入文件,一个字符就是一个字节,而OutputStream字节流泻如文件使要看具体的数据类型的。如一个整型数据占4字节。
我认为这90个字节是因为总共有6个int型,那就是4X6=24个字节。3个double型,那就是8X3=24个字节。还有回车换行符6个,英文字符9个,那就是1X15=15个字节。还有剩下的27个字节,是9个|的字节数。
可能这个题目主要是分析汉字的字节数吧。如下测试数据,文本文件字节数为55字节,二进制文件为102 字节。其中一个汉字的代表字节数不同。使用PrintWriter字符流输入文件一个汉字字符两个字节,而使用OutPutStream字节流输入一个中文汉字占三个字节,这主要是因为使用了UTF-8编码,如果使用GBK编码,一个中文汉字占两个字节。

我认为二进制文件会比较节省空间。虽然上面的是反例。因为比如你输入的PI,3.14159265,二进制文件只有8字节,而文本文件有10字节。
好处:二进制文件存储数据比较精确,如上存储数据为67.90,文本文件不会存储后面的0,这样精确度降低;二进制文件比较节省空间;二进制文件存储数据与计算机内存中存储的一致,都是二进制,减去了数据转换的麻烦。
5-8正则表达式
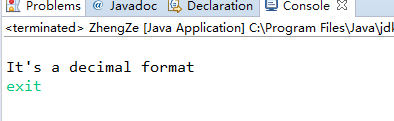
5.8.1 使用正则表达式判断给定的字符串是否是10进制数字格式?尝试编程进行验证,要给测试数据集及运行结果(可以转化为PTA)。(截图关键代码,出现学号)
测试数据:
201621123067
靳天婷
exit
运行结果:
It's a decimal format
It's not a decimal format


5.8.2 解释自己编写的正则表达式。
答:[0-9]表示条件限定在0-9之间的一个字符,表示这种条件的字符出现一次及以上后面加一个“+”。后面如果加“*”表示该种条件字符出现0次即以上,如果是这样的话,只输入一个空格也会输出It's a decimal format。
还可以使用如下表达式,包括了负数和小数。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号