mysql学习(一)
一、连接数据库
mysql -uroot -p //后面可以加上密码 ----------------------------------------- -- 连接后:
show databases; -- 查看所有数据库
use school --切换数据库 use 数据库名
show tables; -- 查看数据库中的所有表
describe student; -- 显示数据库中所有表的信息
create database westos; --创建一个数据库
exit; -- 退出连接
--单行注释
/*
多行注释
*/
二、操作数据库
mysql不区分大小写
操作数据库——>操作数据库中的表——> 操作数据库中表的数据
1、创建数据库
CREATE DATABASE IF NOT EXISTS westos
2、删除数据库
DROP DATABASE IF EXISTS westos
3、使用数据库
USE school --如果前面的表或者字段名是一个特殊的字符,就需要带 ` `
4、查看数据库
SHOW DATABASES --查看所有的数据库
三、数据库的列类型
数值
- tinyint 十分小的数据1个字节
- smallint 较小的数据2个字节
- mediumint 中等大小3个字节
- int 标准的整数4个字节 (常用)
- bigint 较大的数据8个字节
- float 浮点数4个字节
- double 浮点数8个字节 (精度问题)
- decimal 字符串形式的浮点数,金融计算的时候,一般用
字符串
- char 字符串固定大小 0-255
- varchar 可变字符串 0-65535 (常用)
- tinytext 微型文本 2^8-1
- text 文本串2^16-1 (保存大文本)
时间日期
- date YYYY-MM-DD 日期
- time HH:mm:ss 时间格式
- datetime YYYY-MM-DD HH:mm:ss 最常用的时间格式
- timestamp 时间戳1970.1.1到现在的毫秒数
- year 年份表示
null
没有值,未知
注意,不要使用null进行运算,结果为null
四、数据库的字段属性
Unsigned
- 无符号整数
- 声明了该列不能为负数
zerofill
- 0填充的
- 不足的位数,使用0来填充,int(3) 5——>005
自增
- 自动在上一条记录的基础上+1
- 通常用来设计唯一的主键~index,必须是整数类型
- 可以自定义设计主键的起始值和步长
创建简单的数据库
-- AUTO_INCREMENT COMMENT 自增 -- 字符串使用单引号括起来 -- NOT NULL不能为空 -- DEFAULT '123456'设置默认值 -- COMMENT '学号',设置注释 -- PRIMARY KEY(`id`)主键,一般一个表只有一个主键 CREATE TABLE IF NOT EXISTS `mate`( `id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号', `name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名', `pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码', `sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别', `birthday` DATETIME DEFAULT NULL COMMENT '出生日期', `address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址', `email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱', PRIMARY KEY(`id`) )ENGINE = INNODB DEFAULT CHARSET = utf8

CREATE TABLE [IF NOT EXISTS] `表名`( `字段名` 列类型 [属性] [索引] [注释], `字段名` 列类型 [属性] [索引] [注释], `字段名` 列类型 [属性] [索引] [注释] )[表类型][字符集类型][注释]
-- 修改表名:ALTER TABLE 旧表名 REBNAME AS 新表名 ALTER TABLE mate RENAME AS mate1 -- 增加表的字段:ALTER TABLE 表名 ADD 字段名 列属性 ALTER TABLE mate1 ADD age INT(11) -- 修改表的字段(重命名,修改约束) -- ALTER TABLE 表名 MODIFY 字段名 列属性[] ALTER TABLE mate1 MODIFY age VARCHAR(11) -- 修改约束 -- ALTER TABLE 表名 CHANGE 旧 新 字段名 列属性[] ALTER TABLE mate1 CHANGE age age1 INT(1) -- 字段重命名 -- 删除表的字段 ALTER TABLE mate1 DROP age1
删除表尽量都添加if判断语句
DROP TABLE IF EXISTS mate1 -- 删除表
使用外键
CREATE TABLE `grade`( `gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年纪id', `gradename` VARCHAR(50) NOT NULL COMMENT '年纪名称', PRIMARY KEY(`gradeid`) )ENGINE = INNODB DEFAULT CHARSET = utf8 -- 学生表的gradeid 字段要去引用年纪表的gradeid -- 设置外键key -- 给这个外键添加引用 references 引用 CREATE TABLE IF NOT EXISTS `student` ( `id` INT (4) NOT NULL AUTO_INCREMENT COMMENT '学号', `name` VARCHAR (30) NOT NULL DEFAULT '匿名' COMMENT '姓名', `pwd` VARCHAR (20) NOT NULL DEFAULT '123456' COMMENT '密码', `sex` VARCHAR (2) NOT NULL DEFAULT '女' COMMENT '性别', `birthday` DATETIME DEFAULT NULL COMMENT '出生日期', `gradeid` INT(10) NOT NULL COMMENT '学生年纪', `address` VARCHAR (100) DEFAULT NULL COMMENT '家庭住址', `email` VARCHAR (50) DEFAULT NULL COMMENT '邮箱', PRIMARY KEY (`id`), KEY `FK_gradeid` (`gradeid`), CONSISTENT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade` (`gradeid`) ) ENGINE = INNODB DEFAULT CHARSET = utf8
创建表成功后添加外键
CREATE TABLE `grade`( `gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年纪id', `gradename` VARCHAR(50) NOT NULL COMMENT '年纪名称', PRIMARY KEY(`gradeid`) )ENGINE = INNODB DEFAULT CHARSET = utf8 -- 学生表的gradeid 字段要去引用年纪表的gradeid -- 设置外键key -- 给这个外键添加引用 references 引用 CREATE TABLE IF NOT EXISTS `student` ( `id` INT (4) NOT NULL AUTO_INCREMENT COMMENT '学号', `name` VARCHAR (30) NOT NULL DEFAULT '匿名' COMMENT '姓名', `pwd` VARCHAR (20) NOT NULL DEFAULT '123456' COMMENT '密码', `sex` VARCHAR (2) NOT NULL DEFAULT '女' COMMENT '性别', `birthday` DATETIME DEFAULT NULL COMMENT '出生日期', `gradeid` INT(10) NOT NULL COMMENT '学生年纪', `address` VARCHAR (100) DEFAULT NULL COMMENT '家庭住址', `email` VARCHAR (50) DEFAULT NULL COMMENT '邮箱', PRIMARY KEY (`id`), ) ENGINE = INNODB DEFAULT CHARSET = utf8 -- 创建表的时候没有外键关系 ALTER TABLE `student` CONSISTENT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade` (`gradeid`);
总结:数据库就是单纯的表,只能用来存数据,只有行(数据)和列(字段)
五、数据库的增添
-- 插入语句`student` -- insert into 表名([字段1,字段2,字段3])values('值1'),('值1')('值1') INSERT INTO `student` (`name`) VALUES ('lihua'); -- 由于主键自增我们可以省略(如果不写表的字段,他们就会一一匹配) -- insert into `student` values('zhangsan'); -- 一般写插入语句,主句和字段意义对应 -- 插入多个字段 INSERT INTO `student` (`name`) VALUES ('里斯'),('虾滑'); INSERT INTO `student` (`name`,`pwd`,`sex`) VALUES ('琼斯','12433','男
增添结果
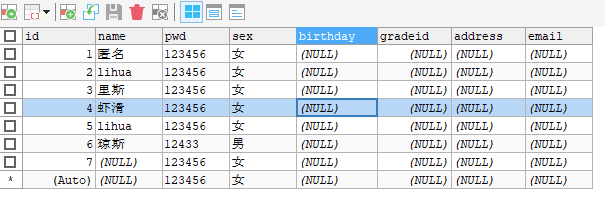
增添语法:
insert into 表名([字段1,字段2,字段3])values('值1'),('值1')('值1')
修改
-- 修改学员名字 UPDATE `student` SET `name` = '魏**' WHERE id = 1; -- 不指定条件下,会改动所有的表 UPDATE `student` SET `name`="长江7号" -- 修改多个属性,逗号隔开 UPDATE `student` SET `name` = '魏++',`email` = '3296330862@qq.com' WHERE id = 1;
修改语法
UPDATE 表名 SET 列名 = value ,... where [条件]
`birthday`=CURRENT_TIME
删库跑路阶段:
delete命令
-- 删除数据 DELETE FROM `student`; -- 删除指定数据 DELETE FROM `student` WHERE id = 1;
2、truncate命令
作用:完全清空一个数据库表,表的结构和索引不会改变
TRUNCATE `student`
3、delete和TRUNCATE区别
相同点:都能删除数据,都不会删除表的结构
区别: TRYNCATE 重新设置自增列 计数器会归零(delete不会影响自增)
TRUNCATE 不会影响事务
数据库中的 查
数据库内容
CREATE DATABASE IF NOT EXISTS `school`; -- 创建一个school数据库 USE `school`;-- 创建学生表 DROP TABLE IF EXISTS `student`; CREATE TABLE `student`( `studentno` INT(4) NOT NULL COMMENT '学号', `loginpwd` VARCHAR(20) DEFAULT NULL, `studentname` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名', `sex` TINYINT(1) DEFAULT NULL COMMENT '性别,0或1', `gradeid` INT(11) DEFAULT NULL COMMENT '年级编号', `phone` VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空', `address` VARCHAR(255) NOT NULL COMMENT '地址,允许为空', `borndate` DATETIME DEFAULT NULL COMMENT '出生时间', `email` VARCHAR (50) NOT NULL COMMENT '邮箱账号允许为空', `identitycard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号', PRIMARY KEY (`studentno`), UNIQUE KEY `identitycard`(`identitycard`), KEY `email` (`email`) )ENGINE=MYISAM DEFAULT CHARSET=utf8; -- 创建年级表 DROP TABLE IF EXISTS `grade`; CREATE TABLE `grade`( `gradeid` INT(11) NOT NULL AUTO_INCREMENT COMMENT '年级编号', `gradename` VARCHAR(50) NOT NULL COMMENT '年级名称', PRIMARY KEY (`gradeid`) ) ENGINE=INNODB AUTO_INCREMENT = 6 DEFAULT CHARSET = utf8; -- 创建科目表 DROP TABLE IF EXISTS `subject`; CREATE TABLE `subject`( `subjectno`INT(11) NOT NULL AUTO_INCREMENT COMMENT '课程编号', `subjectname` VARCHAR(50) DEFAULT NULL COMMENT '课程名称', `classhour` INT(4) DEFAULT NULL COMMENT '学时', `gradeid` INT(4) DEFAULT NULL COMMENT '年级编号', PRIMARY KEY (`subjectno`) )ENGINE = INNODB AUTO_INCREMENT = 19 DEFAULT CHARSET = utf8; -- 创建成绩表 DROP TABLE IF EXISTS `result`; CREATE TABLE `result`( `studentno` INT(4) NOT NULL COMMENT '学号', `subjectno` INT(4) NOT NULL COMMENT '课程编号', `examdate` DATETIME NOT NULL COMMENT '考试日期', `studentresult` INT (4) NOT NULL COMMENT '考试成绩', KEY `subjectno` (`subjectno`) )ENGINE = INNODB DEFAULT CHARSET = utf8; -- 插入学生数据 其余自行添加 这里只添加了2行 INSERT INTO `student` (`studentno`,`loginpwd`,`studentname`,`sex`,`gradeid`,`phone`,`address`,`borndate`,`email`,`identitycard`) VALUES (1000,'123456','张伟',0,2,'13800001234','北京朝阳','1980-1-1','text123@qq.com','123456198001011234'), (1001,'123456','赵强',1,3,'13800002222','广东深圳','1990-1-1','text111@qq.com','123456199001011233'); -- 插入成绩数据 这里仅插入了一组,其余自行添加 INSERT INTO `result`(`studentno`,`subjectno`,`examdate`,`studentresult`) VALUES (1000,1,'2013-11-11 16:00:00',85), (1000,2,'2013-11-12 16:00:00',70), (1000,3,'2013-11-11 09:00:00',68), (1000,4,'2013-11-13 16:00:00',98), (1000,5,'2013-11-14 16:00:00',58);
-- 插入年级数据
INSERT INTO `grade` (`gradeid`,`gradename`) VALUES(1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'),(5,'预科班');
查询语句
-- 查询全部的学生 SELECT * FROM student -- 查询指定字段 SELECT `StudentNo`,`StudentName` FROM student -- 别名,给结果起一个新的名字 SELECT `StudentNo` AS 学号,`StudentName` AS 学生姓名 FROM student AS s -- 函数 Concat(a,b) SELECT CONCAT('姓名:',StudentName) AS 新名字 FROM student
去重 distinct
-- 查询一下有那些同学参加了考试
SELECT *FROM result -- 查询全部的考试成绩
SELECT `StudentNo` FROM result -- 查询有哪些同学参加了考试
SELECT DISTINCT `StudentNo` FROM result -- 发现重复的数据,去重
数据库的列(表达式)
SELECT VERSION() -- 查询系统版本(函数) SELECT 100*3 -1 AS 计算结果 -- 用来计算(表达式) SELECT @@auto_increment_increment -- 查询自增步长(变量) -- 学员考试成绩 +1 查看 SELECT `StudentNo`,`studentresult` +1 AS '提分后' FROM result
where条件子句
!= 和 not 有一样的效果
-- 查询成绩在95~100 分之间 SELECT StudentNo,`StudentResult` FROM result WHERE studentresult>=95 && studentresult<=100 -- and && SELECT studentNo,`studentresult`FROM result WHERE studentresult>=95 && studentresult<=100 -- 模糊查询(区间) SELECT studentno,`studentresult` FROM result WHERE studentresult BETWEEN 95 AND 100 -- 1000号学生之外的同学的成绩 SELECT studentno,`studentresult` FROM result WHERE studentno!=1000; -- != not SELECT studentno,`studentresult` FROM result WHERE NOT studentno = 1000
模糊查询
-- 模糊查询 -- 查询姓刘的同学 -- like结合 %(代表0到任意个字符) _(一个字符) SELECT `StudentNo`,`StudentName` FROM `Student` WHERE StudentName LIKE '刘%' -- 查询姓刘的同学,名字后面只有一个字 SELECT `StudentNo`,`StudentName` FROM `Student` WHERE StudentName LIKE '刘_' -- 查询姓刘的同学,名字后面只有两个字的 SELECT `StudentNo`,`StudentName` FROM `Student` WHERE StudentName LIKE '刘__' -- 查询姓名中有家字的 SELECT `StudentNo`,`StudentName` FROM `Student` WHERE StudentName LIKE '%家%' -- in SELECT `StudentNo`,`StudentName` FROM `Student` -- 显示查询需要展示的信息 WHERE StudentNo IN (1000,1001) -- 查询在北京的学生 SELECT `StudentNo`,`StudentName` FROM `Student` WHERE `address` IN ('北京') -- null not null-- -- 查询地址为空的学生 null SELECT `StudentNo`,`StudentName` FROM `Student` WHERE address='' OR address IS NULL -- 查询出生日期不为空的学生 SELECT `StudentNo`,`StudentName` FROM `Student` WHERE `borndate` IS NOT NULL
联表查询
/*思路 1、分析需求,分析查询的字段来自哪些表(连接查询) 2、确定使用那种连接查询 确定交叉点 判断的条件:学生表中stidentNo = 成绩表 studentNo*/ SELECT s.studentNo,studentName,subjectNo,studentresult FROM student AS s INNER JOIN result AS r WHERE s.studentNo = r.studentNo -- Right Join SELECT s.studentNo,studentName,subjectNo,studentresult FROM student s INNER JOIN result r ON s.studentNo = r.studentno SELECT s.studentNo,studentName,subjectNo,studentresult FROM student s -- 左表 LEFT JOIN result r -- 右表 ON s.studentNo = r.studentno
| 操作 | 描述 |
| inner join | 如果表中至少有一个匹配,就返回行 |
| left join | 会从左表中返回所有的值,即使右表中没有匹配 |
| right join | 会从右表中返回所有的值,即使左表中没有匹配 |
联接三个表进行查询 student result subject
SELECT s.studentno,studentname,subjectname,studentresult FROM student s RIGHT JOIN result r ON s.studentno = r.studentno -- 查询完的表在r中 INNER JOIN `subject` sub ON r.subjectno = sub.subjectno
FROM student s RIGHT JOIN result r -- 以右边的表r为准
FROM student s LEFT JOIN result r -- 以左边的表s为准
自连接
-- 查询父子信息:把一张表看作是两个一模一样的表 SELECT a.`categoryname` AS '父栏目',b.`categoryname` AS '子栏目' FROM `category` AS a,`category` AS b WHERE a.`categoryid` = b.pid

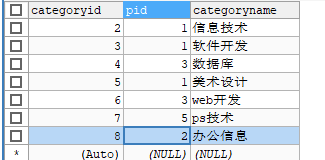
把一张表看作是两张不一样的表结合起来(比较第一张表的 categoryid 和 pid 是否相等)
分组和过滤
-- 查询不同课程的平均分,最高分,最低分,平均分大于80 -- 核心:根据不同课程分组 SELECT any_value(`subjectname`) AS 学科,AVG(studentresult) AS 平均分,max(studentresult) AS 最高分,min(studentresult) AS 最低分 FROM result r INNER JOIN `subject` sub ON sub.`subjectno` = r.`subjectno` GROUP BY r.subjectno -- 通过什么字段来分组 HAVING 平均分>80 -- 过滤分组记录必须满足的次要条件
聚合函数
-- =================聚合函数===================== -- 统计表中的数据 SELECT COUNT('studentno') FROM student; -- 会忽略所以的null值 SELECT COUNT(*) FROM student; -- 不会忽略null值,本质计算行数 SELECT COUNT(1) FROM student; -- 不会忽略null值,本质计算行数 SELECT SUM(`studentresult`) AS 总和 FROM result SELECT avg(`studentresult`) AS 平均分 FROM result SELECT max(`studentresult`) AS 最高分 FROM result SELECT min(`studentresult`) AS 最低分 FROM result

 浙公网安备 33010602011771号
浙公网安备 33010602011771号