

20199304 2019-2020-2 《网络攻防实践》第10周作业
20199304 2019-2020-2 《网络攻防实践》第10周作业
| 问题 | 回答 |
|---|---|
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/besti/19attackdefense |
| 这个作业的要求在哪里 | https://edu.cnblogs.com/campus/besti/19attackdefense/homework/10723 |
| 我在这个课程的目标是 | 学习教材第十章,了解缓冲区溢出漏洞和Shellcode的相关知识 |
| 这个作业在哪个具体方面帮助我实现目标 | 相关知识点 |
1. 实践内容
1.1 软件安全概述
攻击者能够轻易地对系统和网络实施攻击,很大程度上是因为安全漏洞在软件中的大规模存在,攻击者可以利用这些漏洞来违背系统和网络的安全属性。安全漏洞在软件开发周期的各个环节(包括设计、编码、发布等)中都可能被引入,而只有软件设计与开发人员充分认识到安全漏洞的危害、掌握安全漏洞机理,以及如何避免漏洞的安全编程经验,并在软件厂商的软件开发生命周期中切实执行安全设计开发的流程,才有可能尽榄地减少发布软件中的安全漏洞数量,降低它们对网络与现实世界所带来的影响与危害。
1.1.1 软件安全漏洞威胁
软件自从诞生之日起,就和 bug 形影不离,而其中可以被攻击者利用并导致危害的安全缺陷(Security bug)被称为软件安全漏洞(Software Vulnerability)。
美国国家标准技术研究院NIST 将安全漏洞定义为: “在系统安全流程、设计、实现或内部控制中所存在的缺陷或弱点,能够被攻击者所利用并导致安全侵害或对系统安全策略的违反”,包括三个基本元素:
- 系统的脆弱性或缺陷、
- 攻击者对缺陷的可访问性,
- 攻击者对缺陷的可利用性。
因此一个安全脆弱性或缺陷真正被称为安全漏洞,必须是攻击者具备至少一种攻击工具或技术能够访问和利用到这一缺陷。软件安全漏洞则被定义为在软件的需求规范、开发阶段和配置过程中引入的缺陷实例,其执行会违反安全策略。软件安全漏洞同样符合安全漏洞的三个基本元素, 同时被限制于在计算机软件中。
1.1.2 软件安全困境
软件安全困境三要素:
-
复杂性:计算机软件经过数1年的发展,现代软件已经变得非常复杂,而且发展趋势表明,软件的规模还会更快地膨胀,变得更加复杂。而软件规模越来越大,越来越复杂,也就意味着软件的bug会越来越多。虽然这其中大多数 bug 并不会造成安全问题,或者无法被攻击者所利用,但只要攻击者能够从中发现出少数几个可利用的安全漏洞,他们就可以利用这些安全漏洞来危害软件的使用者。
-
可扩展性:导致软件安全困境的第二个要素是软件的可扩展性。现代软件为了支持更加优化的软件架构,支持更好的客户使用感受,往往都会提供一些扩展和交互渠道。但正是现代可扩展软件本身的特性使得安全保证更加困难,首先,很难阻止攻击者和恶意代码以不可预测的扩展方式来入侵软件和系统;其次,分析可扩展性软件的安全性要比分析一个完全不能被更改的软件要因难得多。
-
连通性:互联网的普及使得全球更多的软件系统都连通在一起,不仅是接入互联网的计算机数量快速增加,一些控制关键基础设施的重要信息系统也与互联网建立起了连通性。高度的连通性使得—个小小的软件缺陷就有可能影呐非常大的范围,从而引发巨大的损失。
软件的这三个要素共同作用,使得软件的安全风险管理成为了一个巨大的挑战,从而很难根除安全漏洞。
1.1.3 软件安全漏洞类型
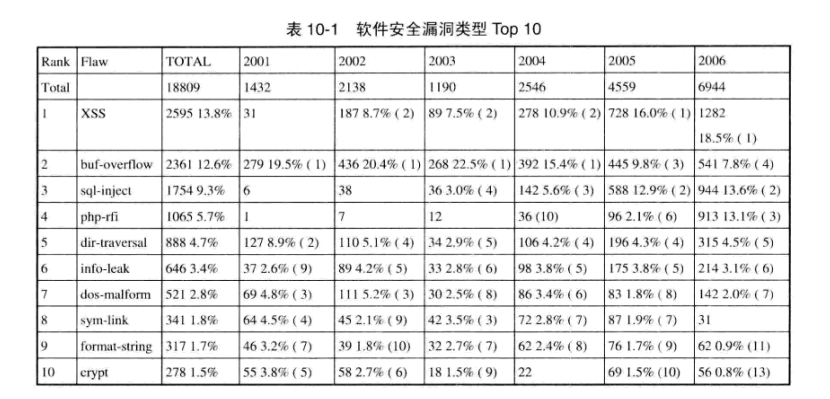
作为软件安全漏涧标准目录 CVE 的维护机构,MITRE 曾给出了在 CVE 中归档的安全漏洞类型统计情况及发展趋势, 从安全漏洞的技术机理方面一共列举出了37类, 并统计了2001-2006 年中最流行的 Top 10 安全漏洞类型,如下图所示
-
内存安全违规类(MemorySafety Violations):
内存安全违规类漏利是在软件开发过程中在处理RAM (random-access memory) 内存访问时所引入的安全缺陷,如缓冲区溢出漏洞和 Double Free、Use-after-Free 等不安全指针问题等。内存安全违规类漏洞主要出现在 C/C++ 等编程语言所编写的软件程序中,由于这类语言支待任意的内存分配与归还、任意的指针计算、转换,而这些操作通常没有进行保护确保内存安全,因而非常容易引入此类漏洞。 -
输入验证类(Input Validation Errors):
输入验证类安全漏洞是指软件程序在对用户输入进行数据验证存在的错误,没有保证输入数据的正确性、合法性和安全性,从而导致可能被恶意攻击与利用。输入验证类安全新洞根据输入位置、恶意输入内容被软件程序的使用方式的不同,又包含格式化字符串、SQL 注入、代码注入、远程文件包含、目录遍历、XSS、HTTP Header 注入、HTTP 响应分割错误等多种安全漏洞技术形式。输入验证类安全漏洞,特别是针对目前流行的 Web 应用程序的输入验证类漏洞,近年来已经成为攻击者最普遍利用的目标。 -
竞争条件类(Race Conditions Errors):
竞争条件类缺陷是系统或进程中一类比较特殊的错误,通常在涉及多进程或多线和处理的程序中出现,是指处理进程的输出或者结果无法预测,并依赖于其他进程事件发生的次序或时间时,所导致的错误。 -
权限混淆与提升类(Privilege confusion and escalation bugs):
权限混淆与提升类漏洞是指计算机程序由千自身编程疏忽或被第三方欺骗,从而滥用其权限,或赋予第三方不该给予的权限。权限混淆与提升类漏洞的具体技术形式主要有 Web 应用程序中的跨站请求伪造(Cross-Site Request Forgery,CSRF)、Clickjacking、FTP反弹攻击、权限提升、"越狱" (jailbreak) 等。
1.2 缓冲区溢出基础概念
缓冲区溢出 (Buffer Overflow) 是最早被发现也是最基础的软件安全漏洞技术类型之一。
1.2.1 缓冲区溢出的基本概念
- 缓冲区溢出是计算机程序中存在的一类内存安全违规类漏洞,在计算机程序向特定缓冲区内填充数据时,超出了缓冲区本身的容量,导致外溢数据覆盖了相邻内存空间的合法数据,从而改变程序执行流程破坏系统运行完整性。理想情况下,程序应检查每个输入缓冲区的数据长度,并不允许输入超出缓冲区本身分配的空间容量,但是大量程序总是假设数据长度是与所分配的存储空间是相匹配的,因而很容易产生缓冲区溢出漏洞。
- 缓冲区溢出攻击发生的根本原因,可以认为是现代计算机系统的基础架构——冯·诺伊曼休系存在本质的安全缺陷,即采用了 “存储程序” 的原理,计算机程序的数据和指令都在同一内存中进行存储而没有严格的分离。这一缺陷使得攻击者可以将输入的数据,通过利用缓冲区溢出漏洞,覆盖修改程序在内存空间中与数据区相邻存储的关键指令,从而达到使程序执行恶意注入指令的攻击目的。
1.2.2 缓冲区溢出攻击背景知识
编译器与调试器的使用:C/C++ 等高级编程语言编写的源码,需要通过编译器(Compiler) 和连接器(Linker)才能生成可直接在操作系统平台上运行的可执行和序代码。向调试器(Debugger)则是程序开发人员在运行时刻调试与分析程序行为的基本工具。对于最常使用的 C/C++ 编程语言。最著名的编译与连接器是GCC,类UNIX 平台上进行程序的调试经常使用的调试器是 GDB 调试器。gdb的常用命令如下表
| 命令 | 作用 |
|---|---|
| break/clear | 来启用或禁用断点 |
| enable/disable | 来启用或禁用断点 |
| watch | 可设置监视表达式值改变时的程序中断 |
| run | 运行程序 |
| attach | 调试已运行进程 |
| continue | 继续运行 |
| next | 单步代码执行并不进入函数调用 |
| nexti | 单步指令执行并不进入函数调用 |
| step | 单步代码并跟入函数调用 |
| stepi | 单步指令并跟入函数调用 |
| info | 查看各种信息 |
| backtrace | 显示调用栈 |
| x | 限制指定地址内容 |
| 显示表达式值 | |
| list | 列出程序源码需调试程序带符号编译 |
| disass | 反汇编指定函数 |
对于 Windows 平台,微软的 Visual Studio、VS.Net 是比较常用的集成开发环境,但对于以调试 C/C++ 语言为主的软件安全漏洞及渗透利用代码,使用 VC++ 即可,VC++集成开发环境中集成了微软自身的 C/C++ 编译器与连接器,以及自带的调试与反汇编功能。
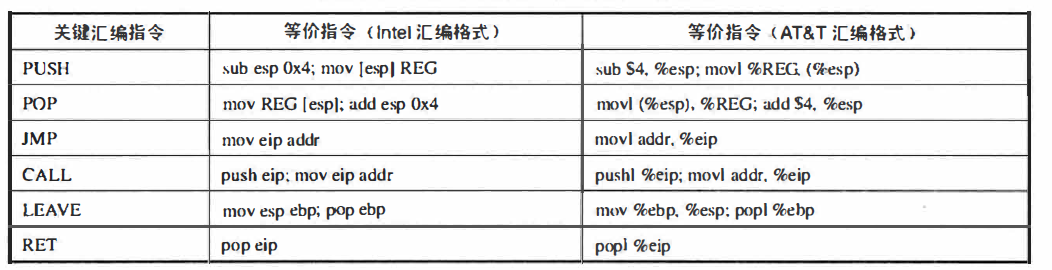
- 汇编语言基础知识:
汇编语言,尤其是 IA32 (Intel 32位)架构下的汇编语言,是理解软件安全漏洞机理,掌握软件渗透攻击代码技术的底层基础。在IA32汇编语言中,首先我们需要熟悉常用的寄存器和它们对应的功能,我们从应用的角度一般将寄存器分为4类,即通用寄存器、段寄存器、控制寄存器和其他寄存器。通用寄存器如eax 、ebx 、ecx、edx等,主要用于普通的算术运算,保存数据、地址、偏移量、计数值等。我们需要特别注意通用寄存器中的 "栈指针" 寄存器 esp,它在栈溢出攻击时是个关键的操纵对象。段寄存器在 IA32 架构中是16位的,一般用作段基址寄存器。控制寄存器用来控制处理器的执行流程,其中最关键的是 eip ,也被称为 “指令指针” 它保存了下一条即将执行的机器指令的地址,因而也成为各种攻击控制程序执行流程的关键攻击目标对象,而如何修改与改变将要被装载至 eip 寄存器的内存数据,以及修改为何地址,是包括缓冲区溢出在内渗透攻击的关键所在。其他寄存器中值得关注的是 “扩展标志” eflags 寄存器,由不同的标志位组成,用于保存指令执行后的状态和控制指令执行流程的标志信息。
![]()
![]()


在熟悉 IA32 架构寄存器之后,我们还需要熟悉一些常用汇编指令的含义,有 IA32 架构汇编语言中,又分为 Intel 和 AT&T 两种具有很多差异的汇编格式。在类 UNIX 平台下,通常使用 AT&T 汇编格式,而在 DOS/Windows 平台下,则主要使用 Intel 汇编格式。
-
进程内存管理:
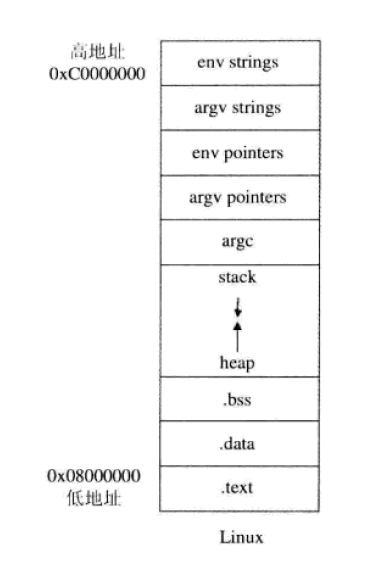
Linux 操作系统中的进程内存空间布局和管理机制: 程序在执行时,系统在内存中会为程序创建一个虚拟的内存地址空间,在 32 位机上即 4GB 的空间大小,用于映射物理内存,并保存程序的指令和数据;Linux 的进程内存空间布局如下图所示,3GB(即0xc0000000)以下为用户态空间,3GB-4GB 为内核态空间;操作系统将可执行程序加载到新创建的内存空间中,程序一般包含 .text、.bss 和 .data 三种类型的段,.text段包含程序指令,在内存中被映射为只读,.data 段主要包含静态初始化的数据,而 .bss 段则主要包含未经初始化的数据,两者都被映射至可写的内存空间中;加载完成后,系统紧接着就开始为相序初始化 “栈” (Stack)和“ 堆” (Heap),“栈” 是一种后进先出的数据结构,其地址空间从商地址向低地址增长,Linux程序运行的环境变量 env 、运行参数 argv、运行参数数量 argc 都被放置在 “栈” 底,然后是主函数及调用 “栈” 中各个函数的临时保存信息,“堆” 则是一种先进先出的数据结构,用于保存程序动态分配的数据和变量,其地址空间从低地址往高地址增长,与 “栈” 正好相反;程序执行时,就会按照程序逻辑执行 .text 中的指令,并在 “堆” 和 “栈” 中保存和读取数据。
![]()
-
Windows 操作系统的进程内存空间布局则与 Linux系统有着一些差异,如下图所示,2GB-4GB 为内核态地址空间,用于映射 Windows 内核代码和一些核心态 DLL,并用于存储一些内核态对象,0GB-2GB为用户态地址空间,高地址段映射了一些大量应用进程所共同使用的系统 DLL,如 Kernel32.dll、User32.dll等,在 1GB 地址位置用于装载一些应用进程本身所引用的 DLL 文件,可执行代码区间从0x00400000 开始, 然后是静态内存空间用于保存全局变量与静态变量,“堆” 同样是从低地址向高地址增长,用于存储动态数据,“栈” 也是从高地址向低地址增长,在单线程进程中一般的 “栈” 底在0x0012XXXX的位置。
![]()
-
函数调用过程:栈结构与函数调用过程的底层细节是理解栈溢出攻击的重要基础,因为栈溢出攻击就是针对函数调用过程中返回地址在栈中的存储位置,进行缓冲区溢出,从而改写返回地址,达到让处理器指令寄存器跳转至攻击者指定位置执行恶意代码的目的。
程序进行函数调用的过程有如下三个步骤:

| 步骤 | 简介 |
|---|---|
| 调用(call): | 调用者将函数调用参数、函数调用下一条指令的返回地址压栈,并跳转至被调用函数入口地址。 |
| 序言(prologue): | 被调用函数开始执行首先会进入序言阶段,将对调用函数的栈基址进行压栈保存,并创建自身函数的栈结构,具体包括将 ebp 寄存器赋值为当前栈基址,为本地函数局部变量分配栈地址空间,更新 esp 寄存器为当前栈顶指针等。 |
| 返回(return): | 被调用函数执行完功能将指令控制权返回给调用者之前, 会进行返回阶段的操作,通常执行 leave 和 ret 指令,即恢复调用者的栈顶与栈底指针,并将之前压栈的返回地址装载至指令寄存器 eip 中,继续执行调用者在函数调用之后的下一条指令。 |
1.2.3 缓冲区溢出攻击原理
缓冲区溢出漏洞根据缓冲区在进程内存空间中的位置不同,又分为栈溢出、堆溢出和内核溢出这三种具体技术形态,栈溢出是指存储在栈上的一些缓冲区变量由于存在缺乏边界保护问题,能够被溢出并修改栈上的敏感信息(通常是返回地址),从而导致程序流程的改变。堆溢出则是存储在堆上的缓冲区变量缺乏边界保护所遭受溢出攻击的安全问题,内核溢出漏洞存在于一些内核模块或程序中,是由于进程内存空间内核态中存储的缓冲区变量被溢出造成的。
下面以栈溢出安全漏洞为例,来讲解缓冲区溢出攻击的基本原理
#include <stdio.h>
void return_input(void){
char array[30];
gets(array);
printf("%s\n", array);
}
int main (void){
return_input();
return 0;
}
这段代码中return_input()函数中定义了一个局部变量array,为30字节长度的字符串缓冲区,按照我们对进程内存空间布局和各类型变量存储位置的了解,函数局部变量将被存储在栈上, 并位于main()函数调用时压栈的下一条指令(即return 0;) 返回地址之下,而在retum_input()函数中执行gets函数将用户终端输入至array缓冲区时,没有进行缓冲区边界检查和保护,因此如果用户输入超出30字节的字符串时,输入数据将会溢出array缓冲区,从而覆盖array缓冲区上方的EBP和RET, 一旦覆盖了RET返回地址之后,在return_input()函数执行完毕返回main()函数时,EIP寄存器将会装载栈中RET位置保存的值,此时该位置已经被溢出改写为溢出的字符串,而该字符串可能是进程无法读取的空间, 所以可能会造成程序的段错误(Segmentation fault)
在上述的示例代码中,我们输入的数据成功地溢出了缓冲区,修改了EBP和RET的内容,造成了程序进程的崩溃,如果是一些重要的程序进程,如网络服务进程,那么它的崩溃就意味着拒绝服务攻击。当然真正的黑客不会满足于只是造成程序的崩溃,他们还期望更进一步地控制程序的执行流程,从而通过溢出获得目标程序或系统的访问控制权。为了达到这一目标,就需要精心地构造缓冲区溢出攻击,解决如下三个问题:
- 如何找出缓冲区溢出要覆盖和修改的敏感位置?例如栈溢出中的RET返回地址在栈中的存储位置。
- 将敏感位置的值修改成什么?
- 执行什么代码指令来达到攻击目的?在程序控制权移父至攻击者注入的指令后,那么这段指令究成何种功能,如何编写?(这段代码被称为攻击的 payload ,通常会为攻出者给出一个远程的 Shell 访问, 因此也被称为 Shellcode)
来看这段示例代码
#include <stdio.h>
#include <string.h>
char shellcode[]=
// setreuid(0,0);
"\x31\xc0" // xor %eax,%eax
"\x31\xdb" // xor %ebx,%ebx
"\x31\xc9" // xor %ecx,%ecx
"\xb0\x46" // mov $0x46,%al
"\xcd\x80" // int $0x80
// execve /bin/sh
"\x31\xc0" // xor %eax,%eax
"\x50" // push %eax
"\x68\x2f\x2f\x73\x68" // push $0x68732f2f
"\x68\x2f\x62\x69\x6e" // push $0x6e69622f
"\x89\xe3" // mov %esp,%ebx
"\x8d\x54\x24\x08" // lea 0x8(%esp,1),%edx
"\x50" // push %eax
"\x53" // push %ebx
"\x8d\x0c\x24" // lea (%esp,1),%ecx
"\xb0\x0b" // mov $0xb,%al
"\xcd\x80" // int $0x80
// exit();
"\x31\xc0" // xor %eax,%eax
"\xb0\x01" // mov $0x1,%al
"\xcd\x80"; // int $0x80
char large_string[128];
int main(int argc, char **argv){
char buffer[96];
int i;
long *long_ptr = (long *) large_string;
for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) buffer;
for (i = 0; i < (int) strlen(shellcode); i++)
large_string[i] = shellcode[i];
strcpy(buffer, large_string);
return 0;
}
这段示例代码中 6字节长度的局部变量buffer在漏洞利用点strcpy()函数缺乏边界安全保护,攻击者通过精心构造large_string这一个128字节长度的数据, 仅在其在低地址包含一段 Shellcode代码(0—31),而其他均填充为指向buffer起始位置的地址(即被覆盖后large_string中的 Shellcode 起始地址),在漏洞利用点执行strcpy操作之后,buffer缓冲区会被溢出,main 函数的返回地址RET 将会被覆盖并改写为 Shellcode 的起始地址,因此在return时,EIP寄存器装载改写后RET值,并将程序执行流程跳转至 Shellcode 执行。
在这个示例代码中,溢出攻击的第一个关键问题——定位需要修改的敏感位置,即栈中的返回地址,根据对栈结构与内存布局,我们可以定位返回地址位于要溢出的buffer变量的高地址位置。第二个关键问题——将敏感位置的值修改为什么,示例代码中将其改写为直接指向 Shellcode 的地址。第三个关键问题——执行什么代码,示例代码中保护了一段代码,用于系统调用,开启一个命令行 shell。
1.3.Linux平台上的栈溢出与shellcode
1.3.1.Linux平台栈溢出攻击技术
Linux平台中的栈溢出攻击按照攻击数据的构造方式不同,主要有NSR、RSN和RS三种模式。
- NSR模式:NSR模式主要适用于被溢出的缓冲区变量比较大,足以容纳Shellcode的情况,其攻击数据从低地址到高地址的构造方式是一堆Nop指令(即空操作指令)之后填充Shellcode,再加上一些期望覆盖RET返回地址的跳转地址,从而构成了NSR攻击数据缓冲区。
- RNS模式:第二种栈溢出的模式为RNS模式,一般用于被溢出的变量比较小,不足于容纳Shellcode的情况,攻击数据从低地址到高地址的构造方式是首先填充一些期望覆盖RET返回地址的跳转地址,然后是一堆Nop指令填充出“着陆区”,最后再是Shellcode。在溢出攻击后,攻击数据将在RET区段即溢出了目标漏洞程序的小缓冲区,并覆盖了栈中的返回地址,然后跳转到Nop指令所构成的“着陆区”,并最终执行Shellcode。
- RS模式:第三种Linux平台上的栈溢出攻击模式是RS模式,在这种模式下能够精确定位出Shellcode在目标漏洞程序进程空间中的起始地址,因此也就无需引入Nop空指令构建“着陆区”。这种模式是将Shellcode放置在目标漏洞程序执行时的环境变量中,由于环境变量是位于Linux进程空间的栈底位置,因而不会受到各种变量内存分配与对齐因素的影响,其位置是固定的,可以通过如下公式进行计算:
ret=0xc0000000 - sizeof(void*) - sizeof(FILENAME) - sizeof(Shellcode)
1.3.2.Linux平台的Shellcode实现技术
事实上,Shellcode是一段机器指令,对于我们通常接触的IA32架构平台,Shellcode就是符合Intel 32位指令规范的一串CPU指令,被用于溢出之后改变系统正常流程,转而执行Shellcode以完成渗透测试者的攻击目的,通常是为他提供一个访问系统的本地或远程命令行访问。
-
Linux本地Shellcode实现机制
Linux系统本地Shellcode通常提供的功能就是为攻击者启动一个命令行Shell。Linux 中一个最简单的本地 Shellcode 的产生过程, 而这个过程事实上也体现了 Shellcode 的通用方法, 包括如下5个步骤:- 1.先用高级编程语言, 通常用C, 来编写 Shellcode 程序;
- 2.编译并反汇编调试这个 Shellcode 程序;
- 3.从汇编语言代码级别分析程序执行流程;
- 4.整理生成的汇编代码, 尽量减小它的体积并使它可注入, 并可通过嵌入C语言进行运行测试和调试;
- 5.提取汇编代码所对应的 opcode 二进制指令, 创建 Shellcode 指令数组。
-
Linux远程Shellcode实现机制
Linux系统上的远程Shellcode需要让攻击目标程序创建socket监听指定的端口等待客户端连接,启动一个命令行Shell并将命令行的输入输出与socket绑定,这样攻击者就可以通过socket客户端连接目标程序所在主机的开放端口, 与服务端socket建立起通信通道, 并获得远程访问Shell。
1.4 Windows平台上的栈溢出与Shellcode
从技术上分析,由于Windows操作系统与Linux操作系统在进程内存空间布局、系统堆栈的处理方式、系统功能调用方式等方面上的实现差异,虽然栈溢出的基础原理和大致流程是一致的,但在具体的攻击实施细节、Shellcode编制等方面还存在着一些差别。
1.4.1 Windows平台栈溢出攻击技术
成功攻击应用程序中栈溢出漏洞密切相关的主要有以下三点:
- 对程序运行过程中废弃栈的处理方式差异
- 进程内存空间的布局差异
- 系统功能调用实现方式差异
1.4.2 Windows平台Shellcode实现技术
- Windows平台Shellcode实现技术
- shellcode必须可以找到所需要的Windows32 API函数,并生成函数调用表
- 为了能够使用API函数,shellcode必须找到目标程序已加载的函数地址
- shellcode需考虑消除空字节,以免在字符串操作函数中被截断
- shellcode需确保自己可以正常退出,并使原来的目标程序进程继续运行或终止
- 在目标系统环境存在异常处理和安全防护机制时,shellcode需进一步考虑如何应对这些机制
- Windows远程Shellcode
- 创建一个服务器端socket,并在指定的端口上监听
- 通过accept()接受客户端的网络连接
- 创建子程序,运行“cmd.exe”,启动命令行
- 创建两个管道,命令管道将服务器端socket接收(recv)到的客户端通过网络输入的执行命令,连接至cmd.exe的标准输入;然后输出管道将cmd.exe的标准输出连接至服务器端socket的发送(send),通过网络将运行结果反馈给客户端
1.5 堆溢出攻击
堆溢出(Heap Overflow)是缓冲区溢出中第二种类型的攻击方式,由于堆中的内存分配与管理机制较栈更为复杂,不同操作系统平台的实现机制都具有显著的差异,同时通过堆中的缓冲区溢出控制目标程序执行流程需要更精妙的构造,因此堆溢出攻击的难度较栈溢出要复杂很多,真正掌握、理解并运用堆溢出攻击也更为困难一些。
下面简要地通过对函数指针改写、C++类对象虚函数表改写以及 Linux 下堆管埋漏洞攻击案例讲解,来说明堆溢出攻击的基本原理
-
函数指针改写:
这种攻击方式要求被溢出的缓冲区临近全局函数指针存储地址,且在其低地址方向上。如果向缓冲区填充数据的时候,如果没有边界控制和判断的话,缓冲区溢出就会自然的覆盖函数指针所在的内存区,从而改写函数指针的指向地址,则程序在使用这个函数指针调用原先的期望函数的时候就会转而执行 Shellcode -
C++ 类对象虚函数表改写:
C++类通过虚函数提供了一种 Late bingding 运行时绑定机制,编译器为每个虚函数的类建立起虚函数表、存放虚函数的地址,并在每个类对象的内存区中放入一个指向虚函数表的指针。对于使用了难函数机制的C++ 类, 如果它的类成员变量中存在可被溢出的缓冲区,那么就可以进行堆溢出攻击,通过覆盖类对象的虑函数指针,使只指向一个特殊构造的虚函数表, 从而转向执行攻击者恶意注入的指令。 -
Linux下堆管理 glibc 库 free() 函数本身漏洞:
Linux操作系统的堆管理是通过 glibc 库来实现的。其中对于堆管理的算法称为 dlmalloc。其通过称为 Bin 的双向循环链表来保存内存空闲块的信息。glibc 库中的 free 函数在内存回收的过程中,需要将已经释放的空闲块和与之相邻的空闲块进行合并。通过精心构造空闲块,在空闲块合并的过程中,将会发生位置覆盖。
1.6 缓冲区溢出攻击的防御技术
-
尝试杜绝溢出
-
最直接的方法就是写不存在缓冲区溢出的代码。
-
但是很多效率优先的代码很容易就出现缓冲区溢出。因此研究出了很多工具来帮助经验不足的程序员来编写安全的程序,还有一些查错程序,但是都不能完全检查出所有漏洞。
-
-
允许溢出单不允许程序改变进程。
-
允许溢出的产生,但是对关键的数据进行严格的保护,阻断溢出攻击。
-
黑客们则想到了绕过的方法,包括c++中的虚函数表指针、覆盖SEH异常处理结构等方法。
-
-
无法让攻击代码执行
-
尝试解决冯诺依曼体系的本质缺陷,通过堆栈不可执行来防御攻击。
-
相应的,黑客也提出了return-2-libc攻击技术,不是让cpu去执行代码,而是在系统中查找已经存在的代码,然后按顺序组合。
-
学习感想和体会
本章的学习涉及缓冲区溢出漏洞和Shellcode的相关知识,使我将操作系统与网络攻防的结合有了基础的认识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号