
20182204 实验四《Python程序设计》实验报告
20182204学号 2019-2020-2 《Python程序设计》实验4报告
课程:《Python程序设计》
班级: 1822
姓名: 20182204zwp
学号:20182204
实验教师:王志强老师
实验日期:2020年5月23日
必修/选修: 公选课
1.实验内容
1.python综合实践——游戏(破解)
2.python爬虫爬取音乐下载
2. 实验过程及结果
(1)
利用import win32gui,获取找到这个窗口的进程,利用win32process.GetWindowThreadProcessId获取应用的进程id
利用win32api.OpenProcess读取内存(打开应用进程)
利用ctypes.windll.LoadLibrary保存数据的缓冲区,再利用Cheat Engine 7.0工具进行分析其阳光的地址所在,然后用ReadProcessMemory进行读进程的地址,最后用WriteProcessMemory修改想要的阳光的值,就可以实现游戏的破解
(2)
利用import requests来请求网页,然后用from lxml import etree来解析网页,使得response.text来返回网址的文本格式
通过观察请求得到的网页内容,可以发现歌曲的 id 即为网页中 a 标签的 href 属性对应的值
而歌曲名则为 a 标签中的文本内容
利用format_html.xpath方法来获取歌曲的名称和歌手,再将外链中的歌曲id替换成我们爬取到歌曲id
源文件
(1)植物大战僵尸的破解
import ctypes import win32gui import win32process import win32api window_handle=win32gui.FindWindow(None,'植物大战僵尸中文版') #找到这个窗口的进程 print(window_handle) process_id=win32process.GetWindowThreadProcessId(window_handle)[1] #找到进程id print(process_id) #进程句柄 process_handle=win32api.OpenProcess(0x1F0FFF,False,process_id) #读写内存 kernel32=ctypes.windll.LoadLibrary(r"C:\Windows\System32\kernel32.dll") #用来保存数据的缓冲区 data1=ctypes.c_long() kernel32.ReadProcessMemory(int(process_handle),0x006A9EC0,ctypes.byref(data1),4,None) print(data1.value) data2=ctypes.c_long() kernel32.ReadProcessMemory(int(process_handle),data1.value+0x768,ctypes.byref(data2),4,None) print(data2.value) data3=ctypes.c_long() kernel32.ReadProcessMemory(int(process_handle),data2.value+0x5560,ctypes.byref(data3),4,None) print(data3.value) sun=input() kernel32.WriteProcessMemory(int(process_handle),data2.value+0x5560,ctypes.byref(ctypes.c_long(int(sun))),4,None)
实验结果截图

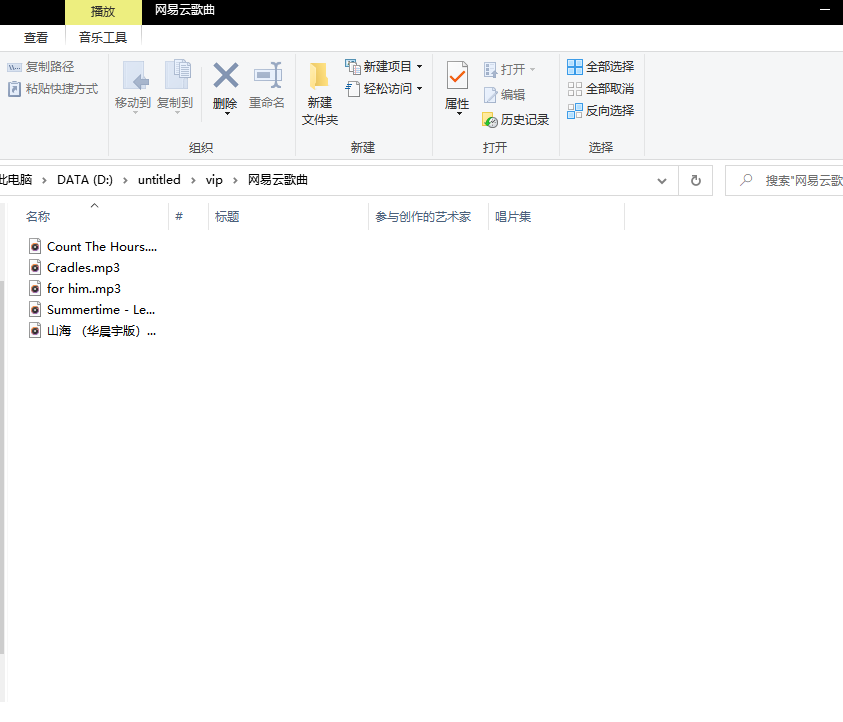
(2)网易云音乐的下载
import requests#用来请求网页 from lxml import etree#用来解析网页 import time import os#用来建立保存歌曲的文件夹 #请求网页 headers={ 'cookie': '_iuqxldmzr_=32; _ntes_nnid=e36214303c6415324b69ea6f8de21b0d,1589807158691; _ntes_nuid=e36214303c6415324b69ea6f8de21b0d; WM_TID=45naN%2BI5xn5FEAVQVVIvSFk%2F6SByf%2BoU; ntes_kaola_ad=1; MUSIC_U=ba89120379287c1fb3ce6d1169665af589ea507b47cdabf6f9194bfd331367208b48af3011315c15effc0efd4ea647f831276cbfe808a970e381395bf06ec255; __remember_me=true; __csrf=8cb5df9df891b3bedea25bd770a45726; JSESSIONID-WYYY=jMJWizSvZIcWc7vlv4nCKw%2B33NVM1NkeUt3heC9F%2FG%2Fl3TGlZxvfIe4cUHGI3U3IKPqO5%2FBvwihPOCdPuPRDdbvZ7V%2Bj%2FRQyW4e%5C%2BAilWQziwO9qCrhIHJm2A%2Fu9zFcS76skTlM%2B56Hism1cJaf8byZNNGAvb0ihDg6Q4awzbQbqgjtX%3A1591799199382; WM_NI=mI1GmeIcMiYSyqlZFGXRJqS2sbHHo8IyUti7995VUdYkA145Jj9%2BJRJsslpcNJBptmCbAV9wruOJ0Oi1eWLdGiAtVUEvP8TqkZ6yhlhYyHdH24XkQlzuWPD0ijFlsdkca0E%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeabed67ac8daaaab67d94ac8aa6c44f879a8bafaa60a195fb89c74dbb96b8b8b12af0fea7c3b92aaf97ffa8f06f8bbd838adc59bbafa4bbc54d9c8e8692d23ab1be88a9ee348ba79b95ec3dfbe7fbb7d8709bb58fd2b73f8ab6f7ccc95a8aadbd8df3698e968e91f76781be8fb7bc7db2ab81abb345abefabb8cf7085b78f95d55f87aaa0d9d77ba986fa9aeb68ac87b7a9e744f2ec988cd468baab99b1c73cabb68a8df270a9bdafd1c837e2a3; playerid=95221086', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36' }#请求头信息 url='https://music.163.com/playlist?id=5064290539'#目标网址 response=requests.get(url,headers=headers)#网页响应内容 response.encoding='utf-8'#设置返回网址的编码格式 html=response.text#返回网址的文本格式 #解析网页 format_html=etree.HTML(html) title=format_html.xpath('//ul[@class="f-hide"]/li/a/text()')#得到歌曲的名称 music_id=format_html.xpath('//ul[@class="f-hide"]//a/@href')#得到歌曲的id content=zip(title,music_id)#使用zip方法将名称和id对应 dir_name="网易云歌曲"#设置文件夹名称 if not os.path.exists(dir_name):#如果文件夹不存在则建立文件夹 os.mkdir(dir_name) pass for i in content: time.sleep(3)#每爬取一首间隔3秒 tit,mu_id=i#用两个变量tit,mu_id接收元组中的内容即分别接收title以及music_id的值 song_id=mu_id.split('=')[-1]#得到获取的music_id的数字部分 url='https://link.hhtjim.com/163/'+str(song_id)+'.mp3'#将外链中的歌曲id替换成我们爬取到歌曲id song=requests.get(url,headers=headers).content#解析得到的歌曲地址 with open(dir_name+'/'+tit+'.mp3','wb') as file:#将解析得到的内容写入我们之前创建的文件夹中 file.write(song) # 写入歌曲,保存
实验结果截图
3. 实验过程中遇到的问题和解决过程
- 问题1:游戏进程的读取
- 问题1解决方案:百度后深入了解到了win32gui.FindWindow的用法
- 问题2:音乐链接的获取
- 问题2解决方案:通过观察请求得到的网页内容,可以发现歌曲的 id 即为网页中 a 标签的 href 属性对应的值,而歌曲名则为 a 标签中的文本内容,所以我们可以通过使用zip方法将名称和id对应,解析网页得到歌曲的 id 以及 歌曲名
其他(感悟、思考等)
python的模块种类繁多,功能强大,综合应用可以实现许多强大的功能,例如进程的获取,利用系统进程来进行对某个应用进程 内部的数据地址的访问以及改写。
python的爬虫也十分强大,可以模仿一个人在操作获取网页的信息,然后筛选供我们所利用,python的许多import,我其实都一知半解没怎么搞懂,还没有真正理解和熟练应用,希望以后还能有时间和机会更加深入学习并且了解python的强大。

