

《Linux内核分析》第八周笔记 进程的切换和系统的一般执行过程
20135132陈雨鑫 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000 ”
一、进程调度与进程调度的时机分析
1、进程调度
不同类型的进程有不同的调度需求
第一种分类:
I/O-bound
频繁的进行I/O
通常会花费很多时间等待I/O操作的完成
CPU-bound
计算密集型
需要大量的CPU时间进行运算
第二种分类:
批处理进程(batch process)
不必与用户交互,通常在后台运行
不必很快响应
典型的批处理程序:编译程序、科学计算
实时进程(real-time process)
有实时需求,不应被低优先级的进程阻塞
响应时间要短、要稳定
典型的实时进程:视频/音频、机械控制等
交互式进程(interactive process)
需要经常与用户交互,因此要花很多时间等待用户输入操作
响应时间要快,平均延迟要低于50~150ms
典型的交互式程序:shell、文本编辑程序、图形应用程序等
内核中的调度算法相关代码使用了类似OOD的策略模式。
2、进程调度的时机
-
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();

-
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
-
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
二、进程上下文切换相关代码分析
1、进程的切换
1)为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;
2)挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;
3)进程上下文包含了进程执行需要的所有信息
-
用户地址空间: 包括程序代码,数据,用户堆栈等
-
控制信息 :进程描述符,内核堆栈等
-
硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
4)schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
•next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
•context_switch(rq, prev, next);//进程上下文切换
•switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
2、代码分析
关键汇编代码:
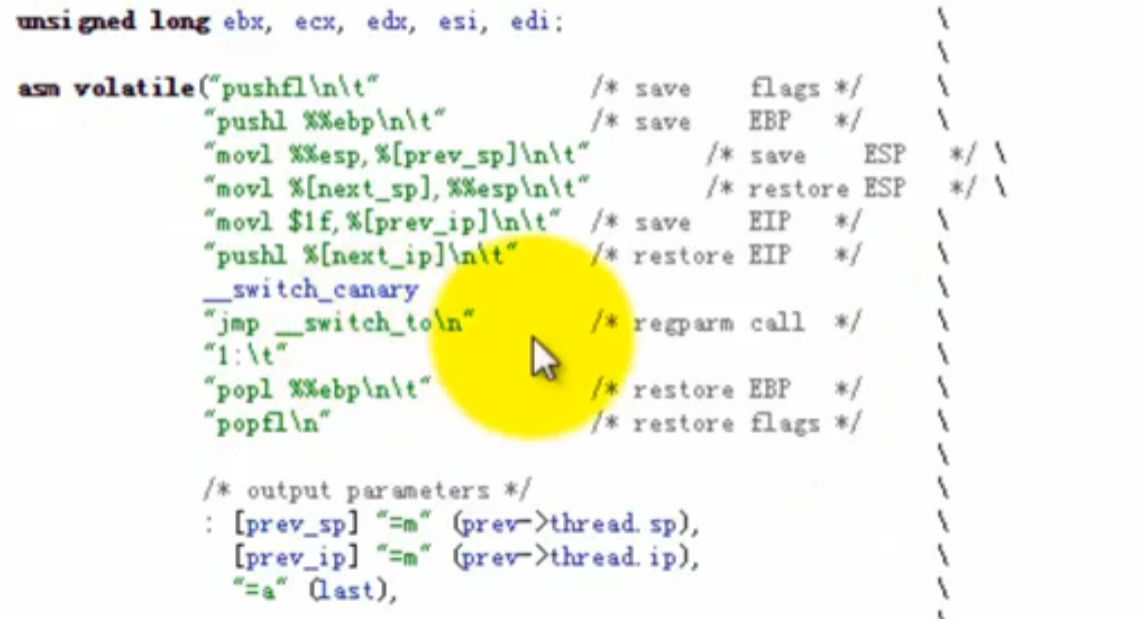
outout: thread.sp:内核态,sp是内核堆栈的栈顶
thread.ip:当前进程的eip

input: prev_sp:下一个进程的内核堆栈的栈顶
prev_ip:下一个进程执行的起点

这两句完成了内核堆栈的切换,将当前内核堆栈的栈顶保存起来,把下一个next进程的栈顶放到ESP寄存器中,之后的压栈动作都是在next进程堆栈中完成:

next_ip一般是$1f,对于新创建的子进程是ret_from_fork。
三、Linux系统的一般执行过程
1、最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
- 正在运行的用户态进程X
- 发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
- SAVE_ALL //保存现场
- 中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
- 标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
- restore_all //恢复现场
- iret - pop cs:eip/ss:esp/eflags from kernel stack
- 继续运行用户态进程Y
2、几种特殊情况
- 通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
- 内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
- 创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
- 加载一个新的可执行程序后返回到用户态的情况,如execve;
next_ip=ret_from_fork
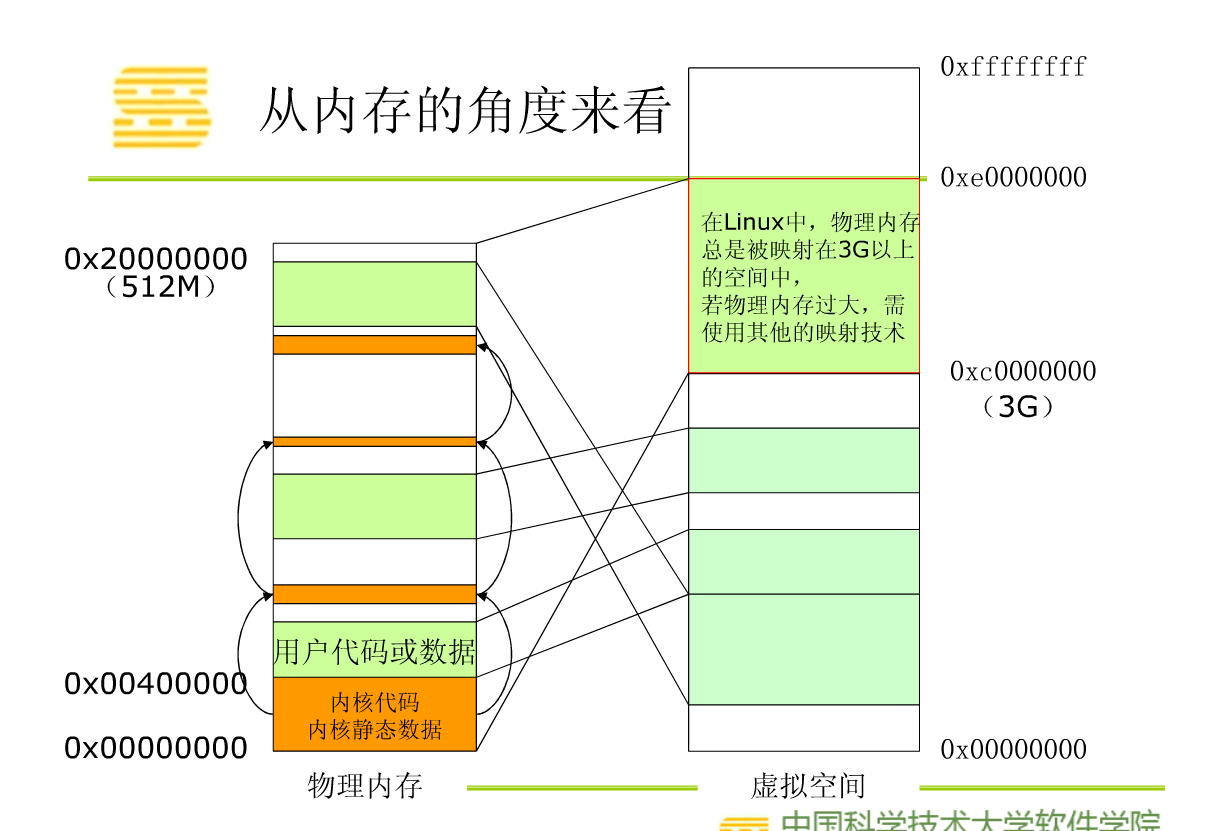
3、进程的地址空间一共有4G,其中0——3G是用户态可以访问,3G以上只有内核态可以访问
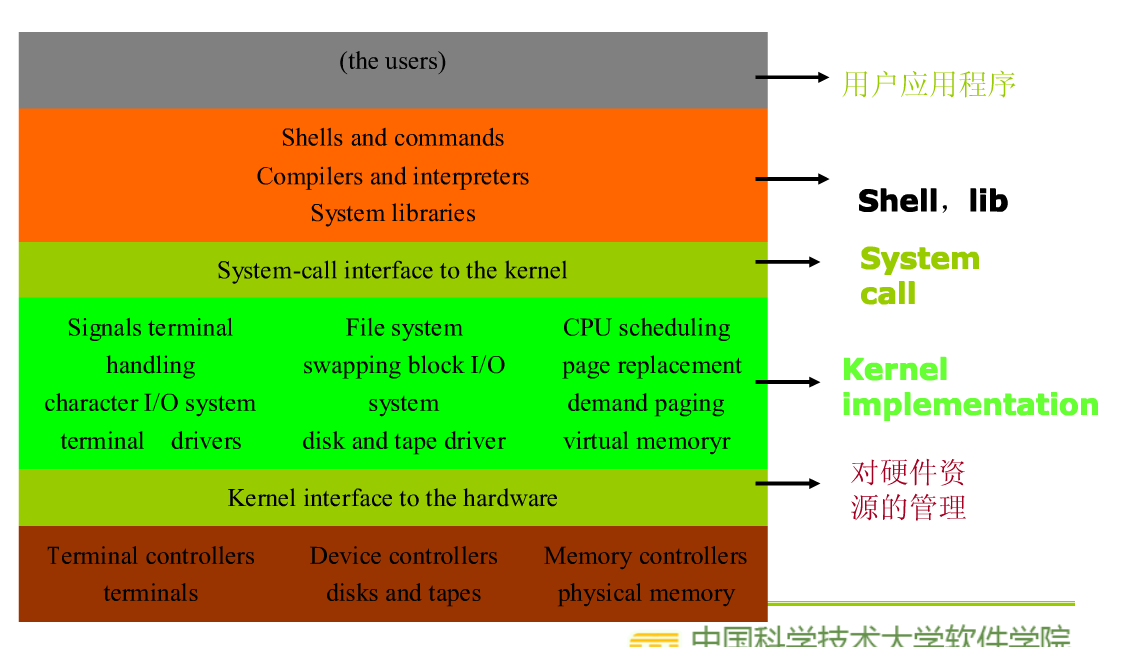
四、系统架构和执行过程概述
1、系统架构

2、典型的Linux操作系统的架构
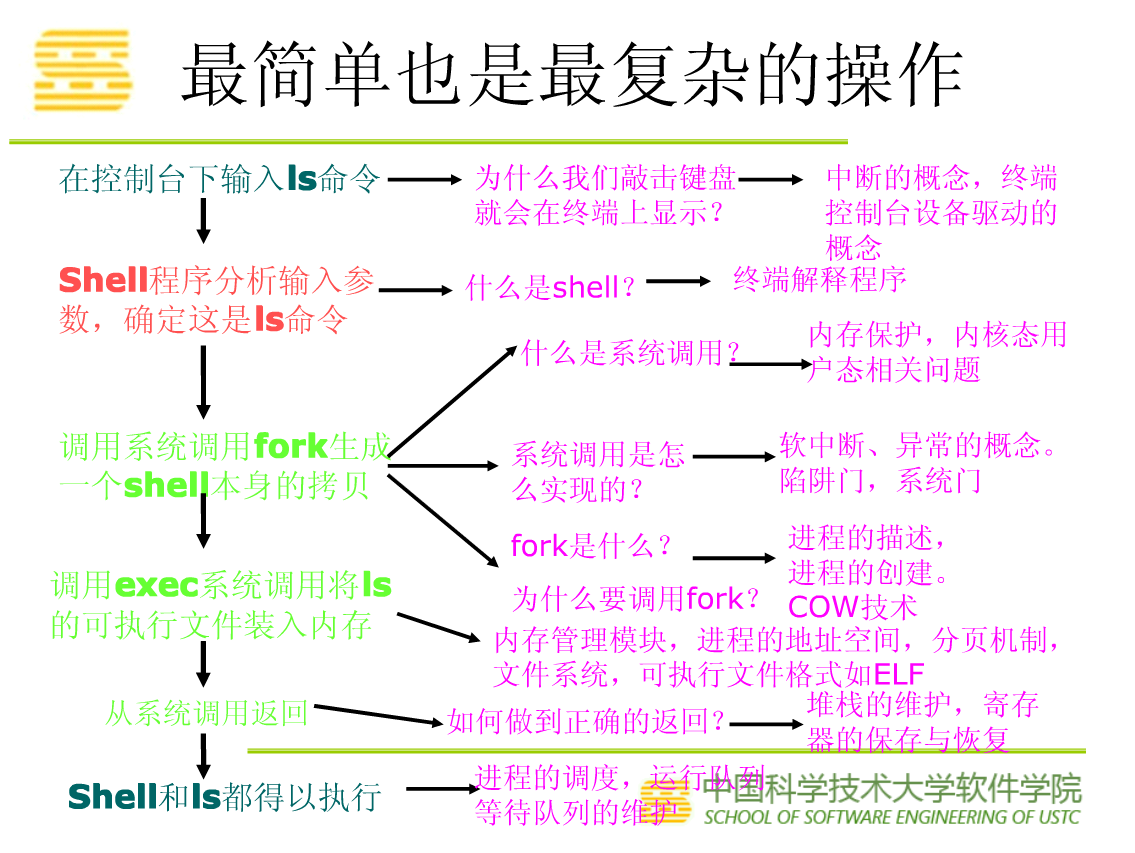
3、最简单也是最复杂的操作——ls
4、CPU和内存的角度看Linux系统的执行
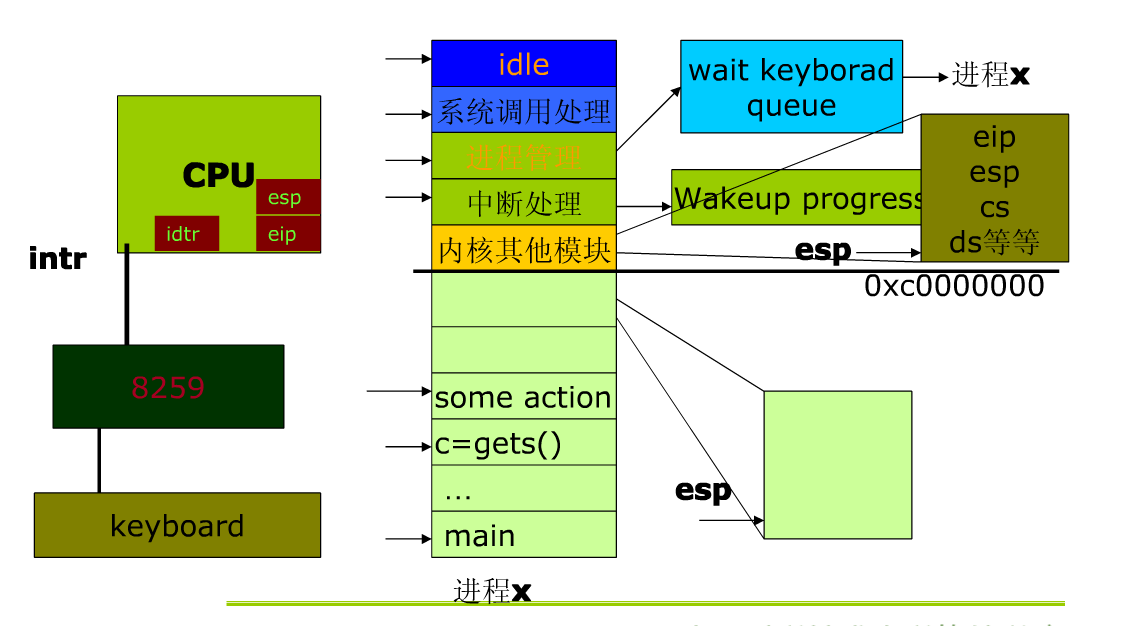
- 执行gets()函数;
- 系统调用,陷入内核态,将eip/esp/cs/ds等信息压栈。
- 进程管理:等待键盘敲入指令。等待输入,CPU会调度其他进程执行,同时wait一个I/O中断;
- 敲击ls,发I/O中断给CPU,中断处理程序进行现场保存、压栈等等;
- 中断处理程序发现X进程在等待这个I/O(此时X已经变成阻塞态),处理程序将X设置为WAKE_UP;
- 进程管理可能会把进程X设置为next进程;
- gets()的系统调用就获得了从键盘上读取的数据,返回用户态。
从内存角度看,所有的物理地址都会被映射到3G以上的地址空间:因为这部分对所有进程来说都是共享的
0xc0000000以下是3G的部分,用户态。
五、实验
使用gdb跟踪分析一个schedule()函数 ,验证对Linux系统进程调度与进程切换过程的理解

关闭QEMU窗口,在shell窗口中,cd LinuxKernel回退到LinuxKernel目录,使用下面的命令启动内核并在CPU运行代码前停下以便调试:
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
接下来,我们就可以水平分割一个新的shell窗口出来,依次使用下面的命令启动gdb调试
gdb
(gdb) file linux-3.18.6/vmlinux
(gdb) target remote:1234
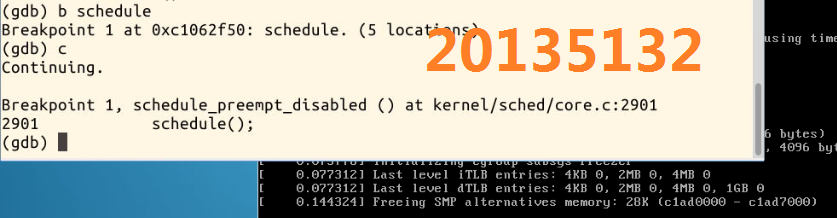
并在内核函数schedule的入口处设置断点,接下来输入c继续执行,则系统即可停在该函数处,接下来我们就可以使用命令n或者s逐步跟踪,可以详细浏览pick_next_task,switch_to等函数的执行过程
设置断点在schedule处:

六、总结
通过学习,我们了解到Linux使用了堆栈进行了进程调度。schedule()在需要的时候重新获得大内核锁、重新启用内核抢占、并检查是否一些其他的进程已经设置了当前进程的tlf_need_resched标志,如果是,整个schedule()函数重新开始执行,否则,函数结束。linux调度的核心函数为schedule,schedule函数封装了内核调度的框架。细节实现上调用具体的调度类中的函数实现。当切换进程已经选好后,就开始用户虚拟空间的处理,然后就是进程的切换switch_to()。所谓进程的切换主要就是堆栈的切换,这是由宏操作switch_to()完成的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号