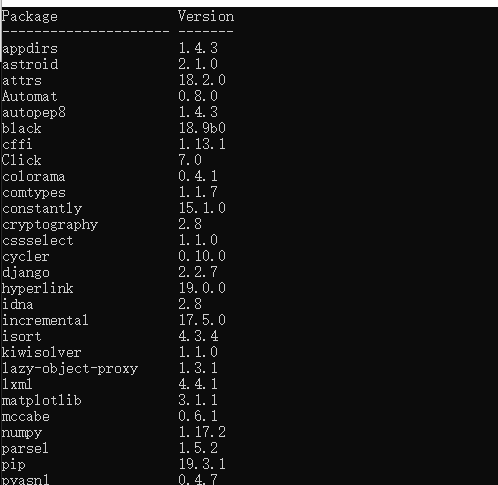
1贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。
2贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
机器学习是人工智能的一个分支
机器学习可以分为监督学习和无监督学习,半监督学习
机器学习可以解决数据清洗/特征选择,确定算法模型/参数优化和结果预测,但是机器学习解决不了大数据存储/并行计算和不能创造一个机器人
建模首先需要数据标签等然后在初步建立模型,通过未知的数据代入模型来预测
机器学习的一般流程:数据收集——数据清洗——特征工程——数据建模
机器学习的学习方法:线性回归,贝叶斯算法,最近邻算法,高斯函数算法,决策树算法
积分的应用
导数的介绍,导数就是曲线的斜率,是曲线变化快慢的反应,二阶导数是斜率变化快慢的反应,表征曲线的凹凸性
常用的函数导数 C’ =0.(sinx)’=cos x,(lnx)’=1/x
Taylor公式
方向导数
梯度的方向是函数在该点变化最快的方向
F函数 F(x)=(x-1).F(x-1)
凸函数 指数函数f(x)=e ax 幂函数f(x)=x a 负对数函数f(x)=-ln x
一阶可微,二阶可微
数据的生成 a = np.arange(0,60,10).reshape((-1,1))+np.arange(6)
类,继承类
重心插值
本福特定律
数组的大小可以通过shape属性获得
Reshape可以创建
数组的元素类型可以勇敢dtype属性获得,如果要更改元素类型,可以使用astype安全的拼接
Linspace函数通过指定起始值,终止值和元素个数来创建数组
可以通过endpoint关键字指定示符包含终止值
Logspace函数可以创建等比数列
切片,左开右闭
如果要生成一定规则的函数,可以使用numpy函数,random是随机取数
3什么是机器学习,有哪些分类?结合案例,写出你的理解。
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能
机器学习按照学习形式进行分类,可分为监督学习、无监督学习、半监督学习、强化学习等。区别在于,监督学习需要提供标注的样本集,无监督学习不需要提供标注的样本集,半监督学习需要提供少量标注的样本,而强化学习需要反馈机制。
监督学习:
监督学习是利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,实现对新数据/实例的标记(分类)/映射。监督学习要求训练样本的分类标签已知,分类标签的精确度越高,样本越具有代表性,学习模型的准确度越高。监督学习在自然语言处理、信息检索、文本挖掘、手写体辨识、垃圾邮件侦测等领域获得了广泛应用。
无监督学习:
无监督学习是利用无标记的有限数据描述隐藏在未标记数据中的结构/规律。无监督学习不需要训练样本和人工标注数据,便于压缩数据存储、减少计算量、提升算法速度,还可以避免正负样本偏移引起的分类错误问题,主要用于经济预测、异常检测、数据挖掘、图像处理、模式识别等领域,例如组织大型计算机集群、社交网络分析、市场分割、天文数据分析等。
半监督学习:
半监督学习介于监督学习与无监督学习之间,其主要解决的问题是利用少量的标注样本和大量的未标注样本进行训练和分类,从而达到减少标注代价、提高学习能力的目的。
强化学习:
强化学习是智能系统从环境到行为映射的学习,以使强化信号函数值最大。由于外部环境提供的信息很少,强化学习系统必须靠自身的经历进行学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号