

第八章
1.选择排序与冒泡排序的区别
选择排序(每轮计算得到每轮的最小或者最大)是进行判别,符合条件进行交换。冒泡排序则是在每次循环中依次对元素进行判断和交换位置。主要差异就在于交换位置的频繁程度上。
2.双向冒泡排序
复杂度上来说,和传统冒泡排序没有什么大的改动。但数据量非常大的时候,双向冒泡排序可以提高排列顺序的效率。从前往后确定本轮最大值,right-1,从后向前确定本轮最小值,left+1。终止条件为left > right。
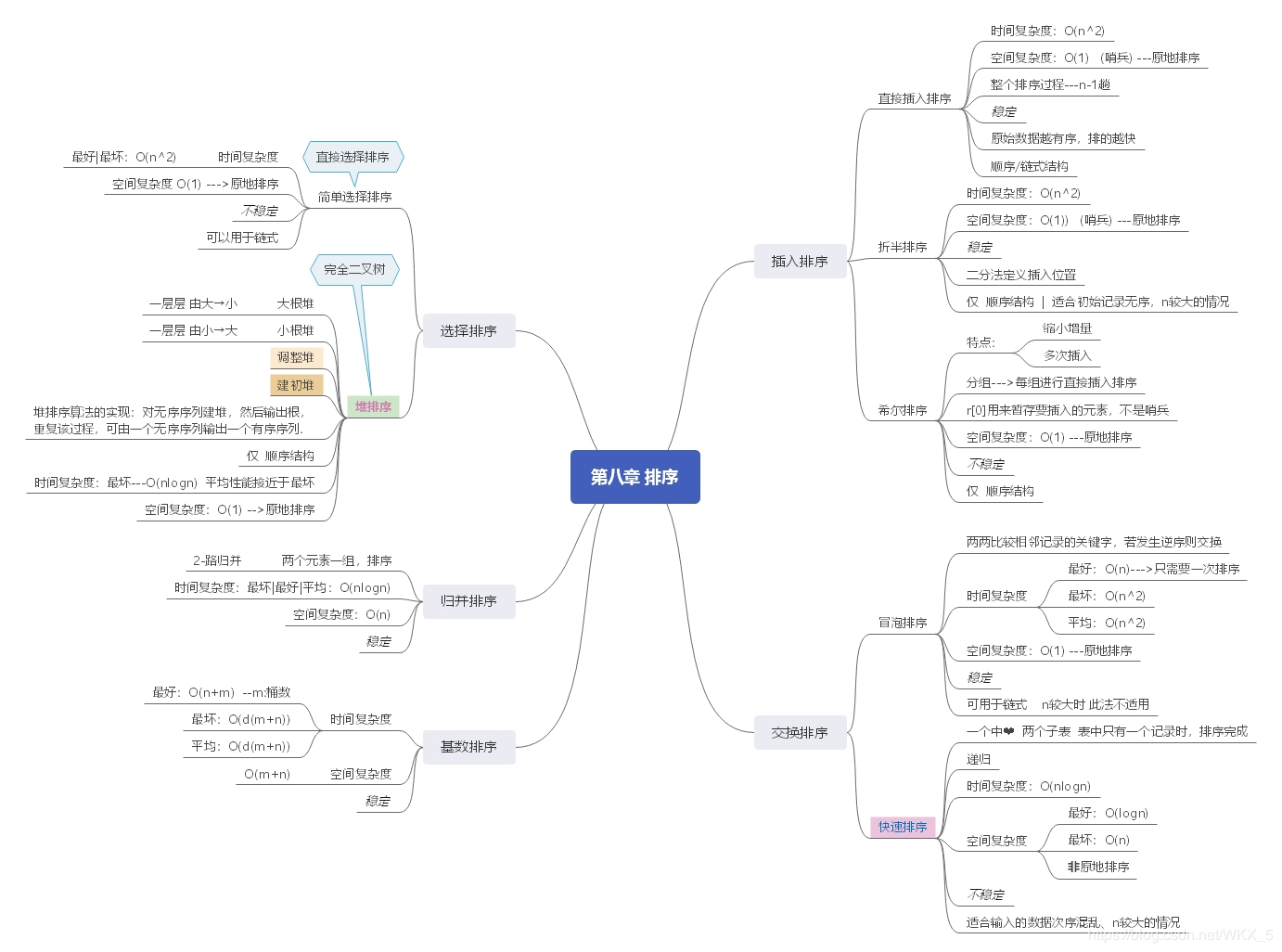
1.插入排序
假设排序列表为 ,从
开始依次和之前的数(
)比较,如果
则将
插在
之前,否则在之后。然后
依次和前面的数(
和
)比较,若
,则插在列首,否则往后继续与
比较,以此类推。
notes: 需要比较的元素成功插入以后,插入位置以后的所有排好序的元素要依次往后移。
算法的空间复杂度为o(1),在表内排序,最佳时间复杂度为o(n)(列表本身为有序),只有外循环n-1次的遍历时间。最差复杂度为o(n^2),假设内循环每次都是插入第一个元素,导致后面所有有序元素都要逐个后移。平均复杂度为o(n^2)。
2.选择排序
选择排序法的基本思想:
- 维护需要考虑的所有记录中最小的i 个记录的已排序序列。
- 每次从剩余未排序的部分挑选出最小的记录,把它放在已排序部分的后面作为第i+1个记录,已排序序列增长。
- 以空序列为排序的开始,直到未排序部分只剩一个元素时,直接将其放入已排序部分最后一个,整个排序工作就完成了。
3.堆排序算法:
堆排序算法在之前的《数据结构与算法——树与二叉树》的文章中提及过,它同样也是一种选择排序的方式,与前两种选择排序方法不同的是用的优先队列的思想选出最小值,以此类推实现表内的排序。这种方式空间复杂度同样为o(1),时间复杂度为o(nlogn),优于前两种算法。但是堆排序同样有稳定性和适应性的问题,即不能保证相同元素的相对位置,并且每次取出最小值,由堆的性质可知,会从堆尾取出元素重新堆排列。
4.交换排序
冒泡排序法是一种典型的需要清除逆序对来达到排序效果的排序算法,通过比较相邻的记录,如果存在逆序则反转,通过反复的比较和反转,最终完成顺序的排序。一次完整的扫描可以保证把最大的元素移动到列表末位,通过一遍遍扫描,表的最后将累积会越来越多排好顺序的大元素。经过n-1次扫描一定能完成所有排序。
5.快速排序法
快速排序法曾经被称为“20世纪最具影响力的算法之一”,在各种基于关键码比较的内排序算法中,快速排序是实践中平均速度最快的算法之一。
快速排序方法的基本操作过程为:
- 选择一种标准,将未排序序列中的记录按照此标准分为大小两组,此时,两组的顺序已定,较小一组的记录排在前面。
- 采用同样方式,递归的划分这两组记录,并继续递归的划分下去。
- 划分总是得到越来越小的分组,如此下去直到每个组最多包含一个记录时停止,整个序列排序完成。
6.归并排序法
归并排序即将两个或多个有序序列合并为一个有序序列,其基本方法为:
- 初始时,将待排序序列的n个记录看成n个有序子序列(只包含一个记录的序列一定是有序的),每个子序列长度为1。
- 把当时序列组的有序子序列两两归并,完成一遍后序列组里的排序序列个数减半,每个子序列的长度加倍。
- 对加长的有序子序列重复上面的操作,最终得到长度为n的有序序列。
归并排序适合处理存储在外存的大量数据,许多实际的外村数据集排序算法都是基于归并排序实现的。因为外存数据比较适合顺序处理,但不适合随机访问。此外,归并操作过程中对数据访问具有局限性,适合外存数据交换的特点。特别适合处理一组记录形成的数据块。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号