YOLOv5到YOLO11:基于Ultralytics框架的目标检测训练与实战
YOLO11模型训练
前面完成了yolov5模型的训练,并且结合OpenCV进行测试,效果还不错。在yolov5源码的README.md文件中了解到yolo已经更新到Yolo11版本,于是开始尝试进行yolo11模型训练看看效果。
Yolo11源码使用了不同于Yolov5源码的新框架ultralytics,使用这个框架可以灵活地通过配置文件来切换v3 ~ 12的yolo模型,而无需重新部署源码
基础环境配置见:从零开始:基于CUDA 12.6的YOLOv5模型训练实战(RTX 2050显卡全流程)
数据集部分也直接使用的之前yolov5的数据集
- 结果展示:
50轮次:

100轮次:

从结果上来看 50轮次有点欠拟合(识别不出对应的目标),100轮次又有点过拟合了(识别的力度太狠,出现了一个地方框选多次的现象)(可能是训练集太少的原因)
GitHub源码:https://github.com/ChengYull/TestYOLO11
下面讲一下部署过程
获取源码
从YOLO11(准确说应该是ultralytics框架)仓库获取源码:https://github.com/ultralytics/ultralytics
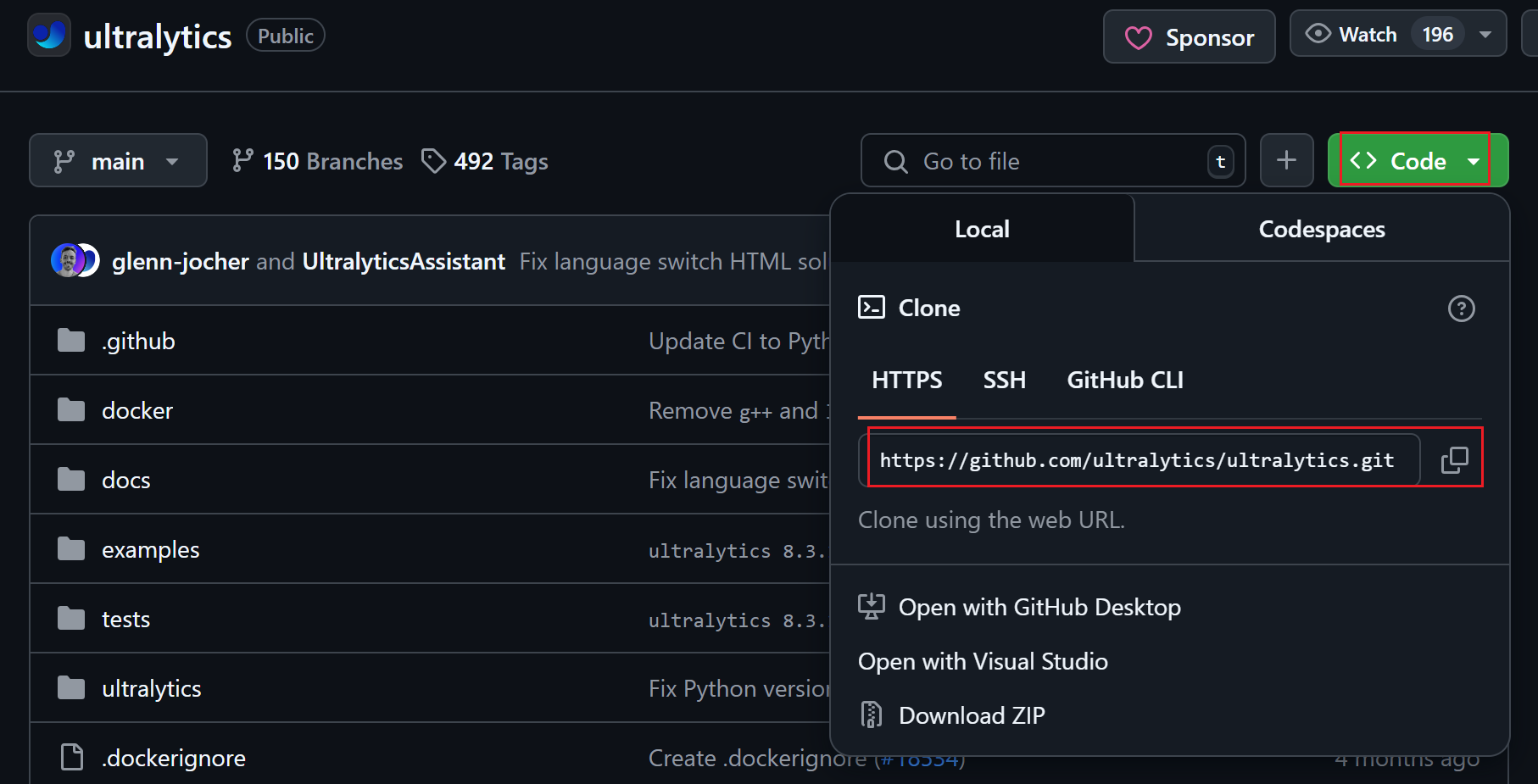
我这里使用Pycharm通过Git直接克隆的项目
输入Yolo11的git链接:https://github.com/ultralytics/ultralytics.git
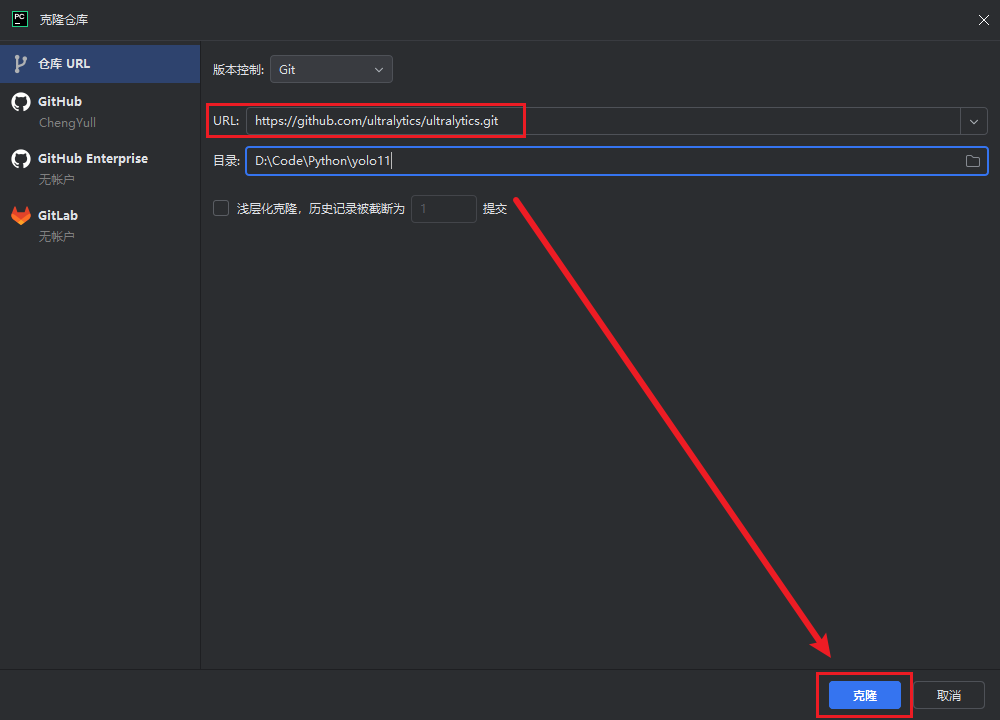
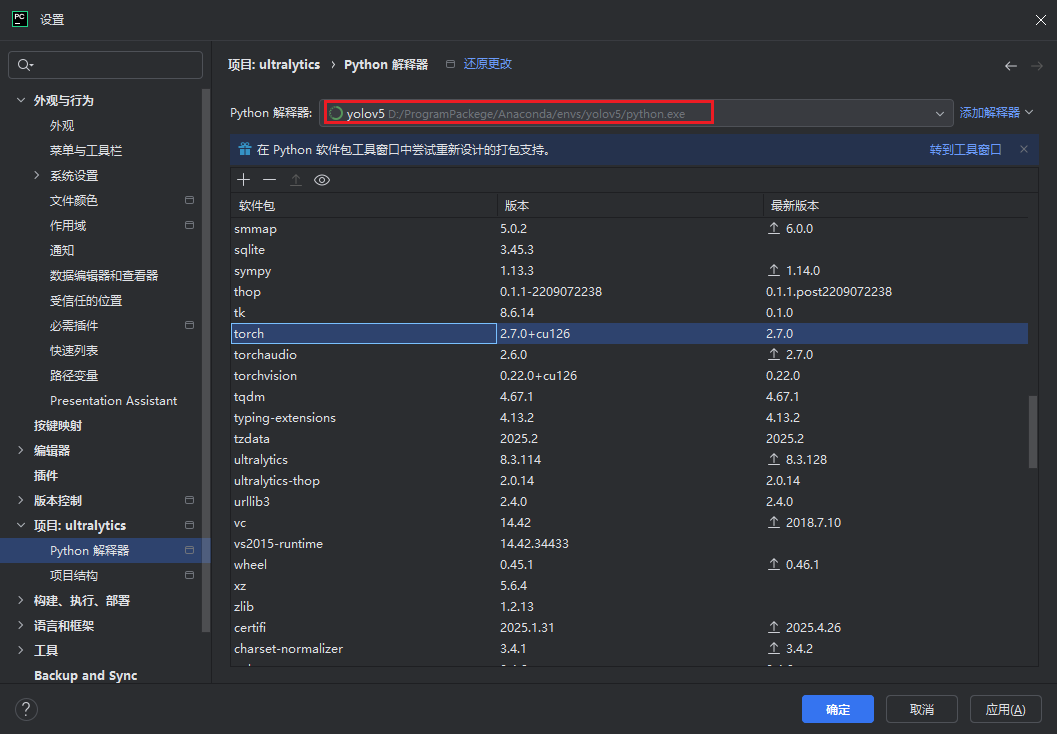
克隆完成后,还需在Pycharm中配置解释器,选择安装了Pytorch的conda环境
在根目录下创建requirements.txt文件
输入以下内容:
# Ultralytics requirements
# Example: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.3.0
numpy==1.24.4 # pinned by Snyk to avoid a vulnerability
opencv-python>=4.6.0
pillow>=7.1.2
pyyaml>=5.3.1
requests>=2.23.0
scipy>=1.4.1
tqdm>=4.64.0
# Logging -------------------------------------
# tensorboard>=2.13.0
# dvclive>=2.12.0
# clearml
# comet
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=7.0 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnxsim>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
# tflite-support
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export
# Extras --------------------------------------
psutil # system utilization
py-cpuinfo # display CPU info
thop>=0.1.1 # FLOPs computation
# ipython # interactive notebook
# albumentations>=1.0.3 # training augmentations
# pycocotools>=2.0.6 # COCO mAP
# roboflow
打开命令行激活安装了Pytorch的虚拟环境,这里因为我之前命名为yolov5,实际上只是一个虚拟环境
同时通过cd命令,将命令行目录移动到项目目录
然后安装项目依赖
pip install -r requirements.txt
也可以直接通过绝对路径(就无需移动命令行目录)
pip install -r D:\Code\Python\testYolo11\requirements.txt
准备训练集数据
这里应用的上一次标注的doro图
源码根目录下创建新文件夹train,放入图片与标注labels文件夹以及yaml文件
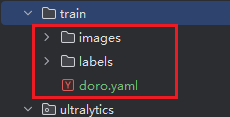
模型训练
创建src文件夹,创建训练程序train.py
# 导入警告模块并忽略警告信息
import warnings
warnings.filterwarnings('ignore')
# 导入YOLO模型
from ultralytics import YOLO
if __name__ == '__main__':
# 创建YOLO模型实例,指定模型配置文件路径
model = YOLO(model='D:/Code/Python/testYolo11/ultralytics/cfg/models/11/yolo11.yaml')
# 开始训练模型
model.train(
data=r'D:/Code/Python/testYolo11/train/doro.yaml', # 数据集配置文件路径
imgsz=640, # 输入图像大小
epochs=50, # 训练轮次数
batch=4, # 批次大小
workers=0, # 数据加载的工作进程数,0表示仅使用主进程
device='0', # 训练设备,0表示使用第一个GPU,'cpu'表示使用CPU
optimizer='SGD', # 优化器类型,使用随机梯度下降
close_mosaic=10, # 在最后10个epoch关闭马赛克数据增强
resume=False, # 是否从断点继续训练
project='runs/train', # 训练结果保存的项目目录
name='exp', # 实验名称
single_cls=False, # 是否作为单类别检测
cache=False, # 是否缓存图像到内存中以加快训练
)
通过修改model = YOLO(model='D:/Code/Python/testYolo11/ultralytics/cfg/models/11/yolo11.yaml') 可以选择不同的模型
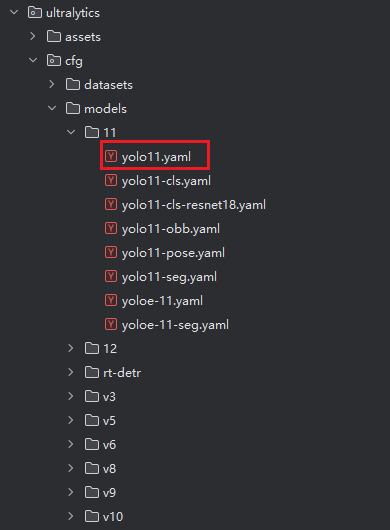
执行train.py程序,等待训练
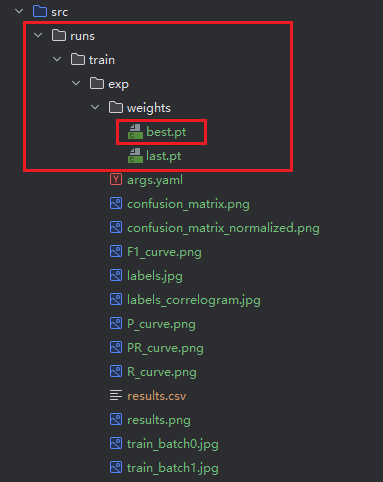
训练完成后,可以在runs文件夹下获取到训练的模型
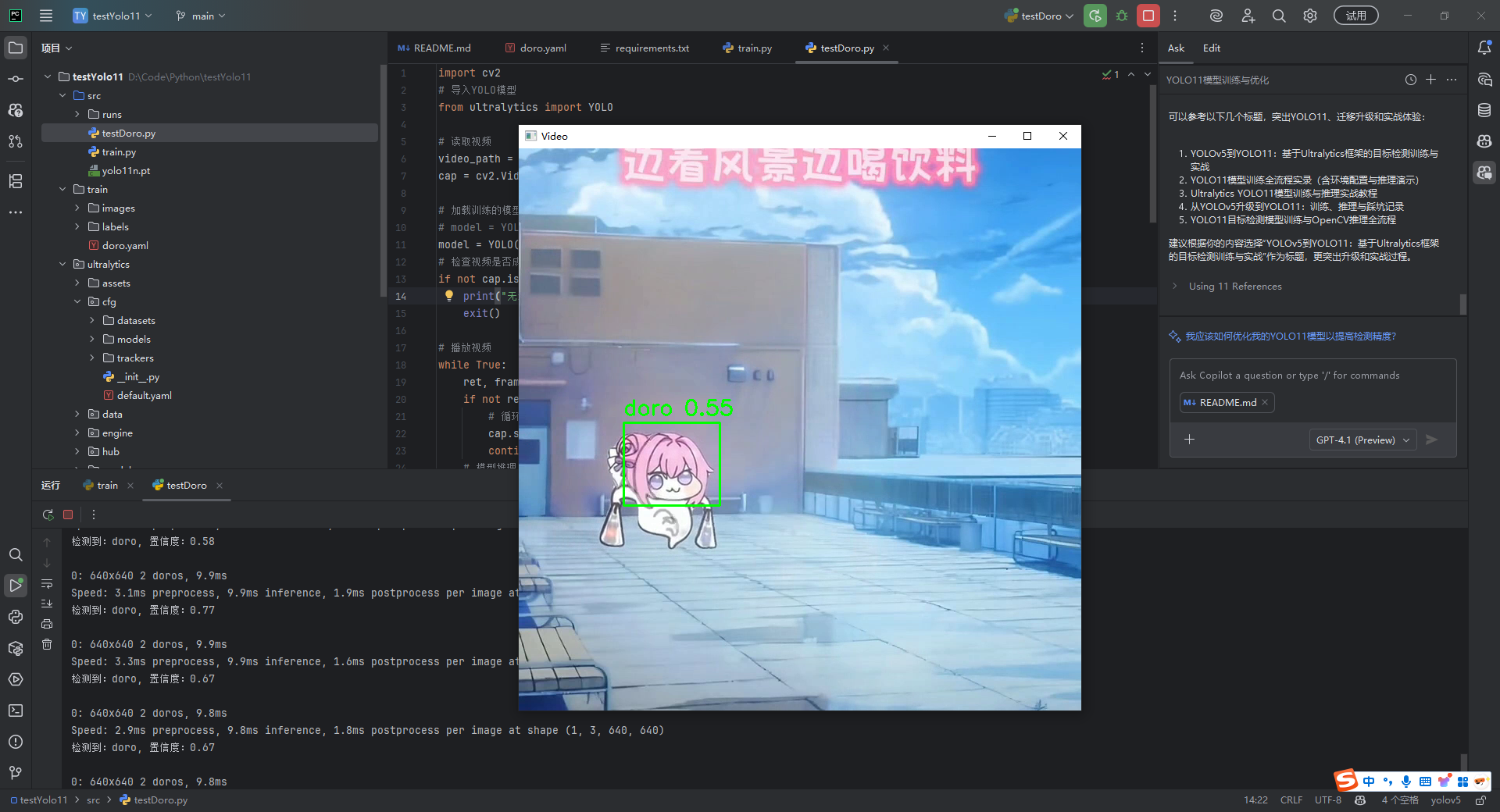
模型推理
这里结合OpenCV使用视频来推理,查看训练的效果
import cv2
# 导入YOLO模型
from ultralytics import YOLO
# 读取视频
video_path = "E:\\test\\testVideo\\doro3.mp4"
cap = cv2.VideoCapture(video_path)
# 加载训练的模型
# model = YOLO('D:/Code/Python/testYolo11/src/runs/detect/train/weights/best.pt')
model = YOLO('D:/Code/Python/testYolo11/src/runs/train/exp/weights/best.pt')
# 检查视频是否成功打开
if not cap.isOpened():
print("无法打开视频文件")
exit()
# 播放视频
while True:
ret, frame = cap.read()
if not ret:
# 循环播放视频
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
continue
# 模型推理
results = model(frame)
# 获取预测结果
# 遍历检测结果并绘制
for box in results[0].boxes:
conf = float(box.conf[0])
if conf < 0.5: # 只显示置信度大于0.5的框
continue
x1, y1, x2, y2 = map(int, box.xyxy[0])
conf = float(box.conf[0])
cls = int(box.cls[0])
class_name = model.names[int(cls)]
# 输出结果
print(f"检测到:{class_name}, 置信度:{conf:.2f}")
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(frame, f"{class_name} {conf:.2f}", (int(x1), int(y1) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示当前帧
cv2.imshow("Video", frame)
# 按下 'a' 键暂停
if cv2.waitKey(1) & 0xFF == ord('a'):
while True:
# 等待用户按下 'r' 键继续
if cv2.waitKey(1) & 0xFF == ord('d'):
break
# 显示当前帧
cv2.imshow("Video", frame)
# 按下 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放视频捕获对象和关闭所有窗口
cap.release()
cv2.destroyAllWindows()
- 注意推理代码与旧版
yolov5的区别- 加载模型直接通过
model = YOLO('D:/Code/Python/testYolo11/src/runs/train/exp/weights/best.pt')加载 - 推理结果是通过
boxes获取-for box in results[0].boxes: - 坐标获取与旧版
yolov5也有一定区别 -x1, y1, x2, y2 = map(int, box.xyxy[0])
- 加载模型直接通过

 浙公网安备 33010602011771号
浙公网安备 33010602011771号