结对作业(2/2)
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 点击前往 |
| 结对学号 | 221701133,021700511 |
| 这个作业的目标 | 实现某次疫情统计可视化的功能 |
| 作业正文 | 就是这里 |
| 其他参考文献 | ... |
1.在文章开头给出Github仓库地址和代码规范链接。
2.展示你的成品,要求提供10张以上的图片,或者采用GIF或者视频嵌入的方式来展示作业要求的功能。如果部署到云服务器上,可以一并给出链接。
部署的服务器地址:点击前往
展示:
主页面

地区页

最新资讯页

3.结对讨论过程描述,即刚开始拿到题目后,和队友怎么讨论,解决问题和查找资料的过程,并提供两人结对讨论的截图。。
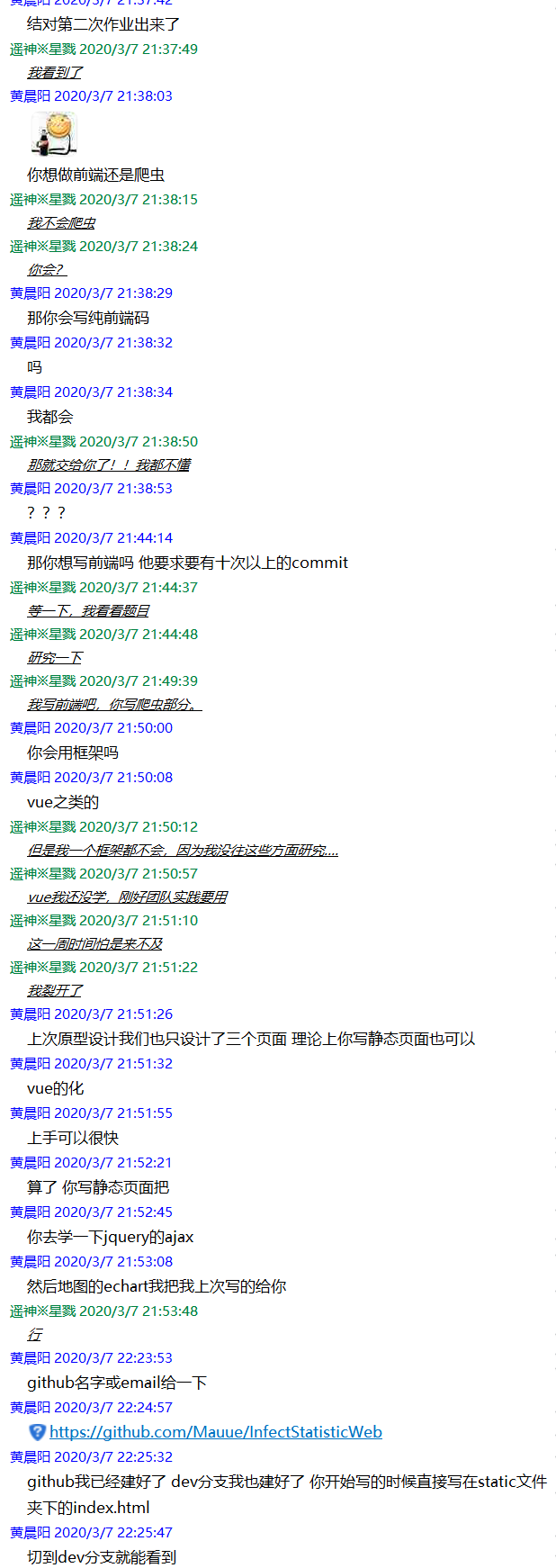
讨论过程1:
刚拿到题目时,陷入了一个困境,一个全都会,一个全不会。时间又只有一周,于是乎保险起见做了分工,都不会的写静态页面的前端,其余的例如数据爬取的编程以及服务器相关部署交给都会的。
讨论过程2:
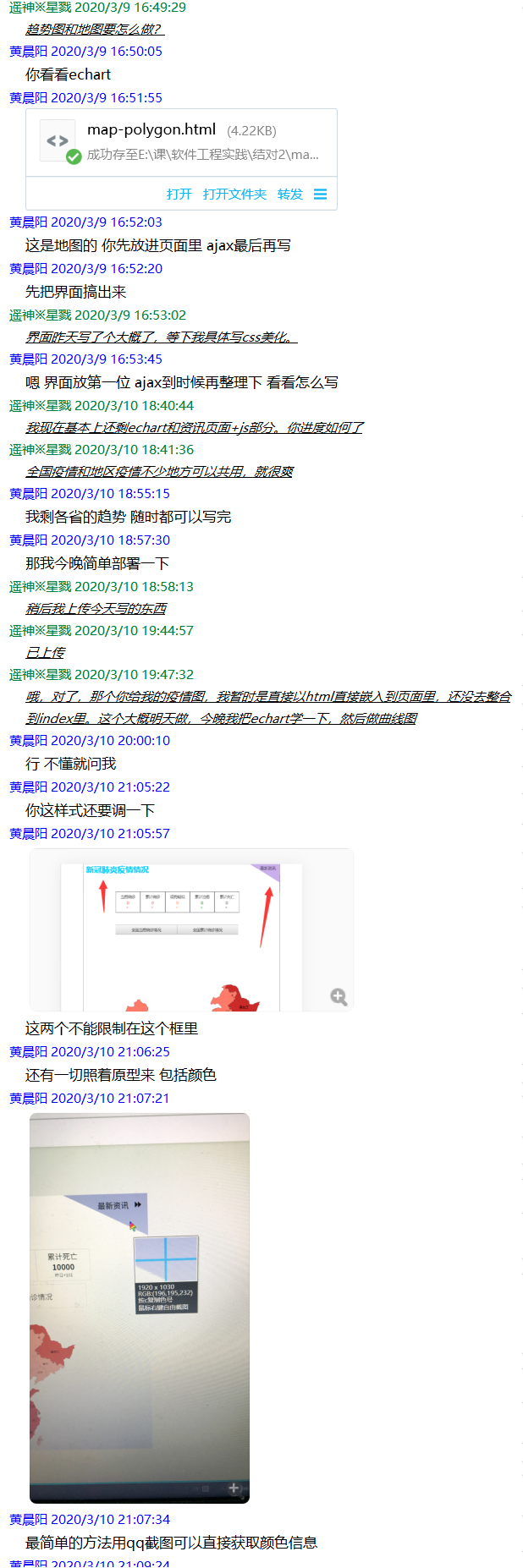
先从简单的做起,一步步到更难的地方,与此同时一边参照上次制作的原型进行修改显示样式。
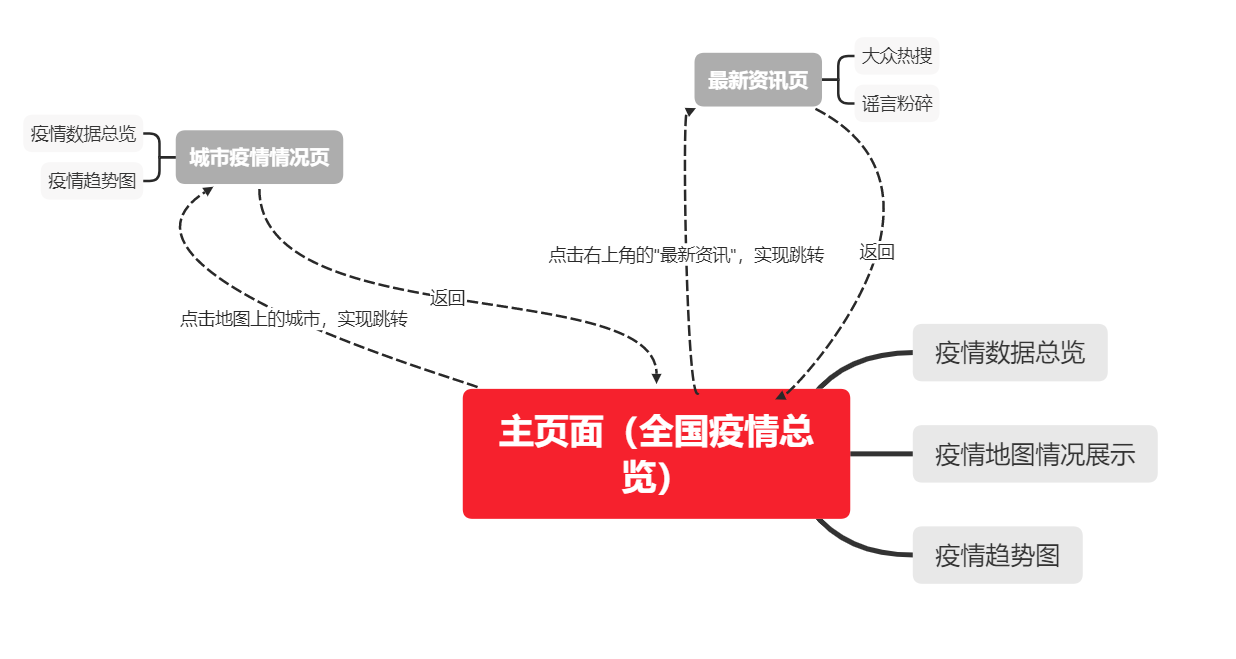
4.描述设计实现过程,给出功能结构图。
设计实现前端部分基本上是参照原型进行编程。用到了echarts来显示地图,利用ajax来将爬取的数据进行更新显示。
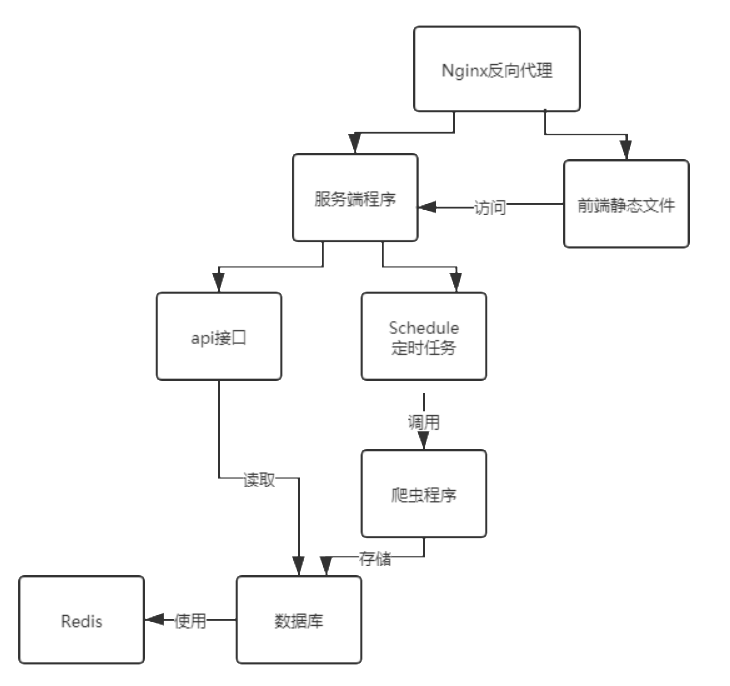
总体结构。服务器程序定时爬取疫情数据和疫情相关新闻到数据库中,然后前端的静态文件通过制定的api接口访问服务器端的数据库,然后对页面进行更新。
5.代码说明。展示出项目关键代码,300行左右,并解释思路。
(1)爬虫数据选择的是百度的疫情地图。百度这很有意思,估计是考虑到信息不是实时更新,全部数据都是静态存储在网页中,一个请求拿到几乎全部的数据:
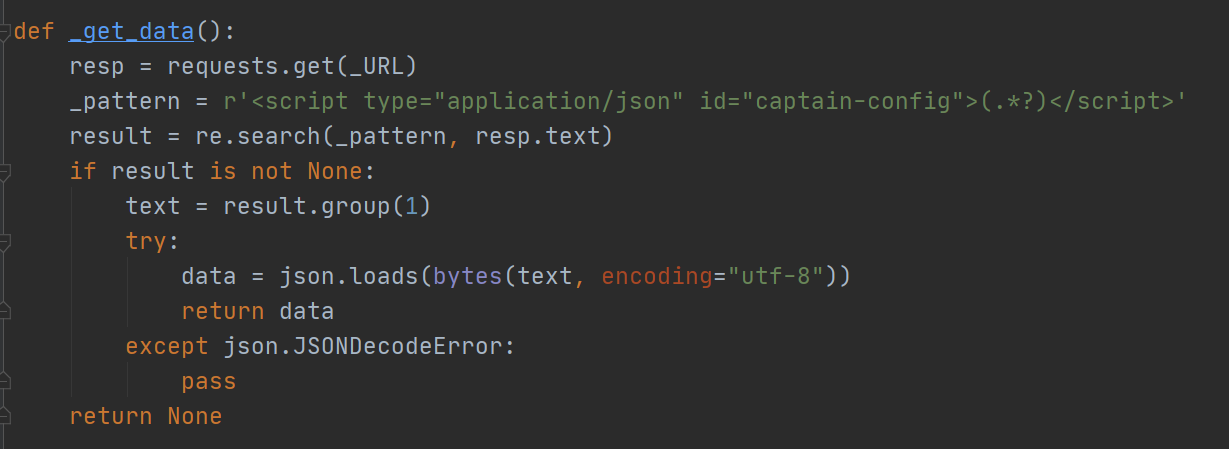
(2)接下来的任务就是从中提取所需要的信息,存储到数据库中。因为读多写少,也没有条件查询,而且数据格式可能还会发生变化(百度这数据看起来就像临时加班加点写出来的,甚至还把cure写成了crue。如果哪天百度重写了这个页面,那么这个爬虫就废了),所以这里使用Redis,将爬取到信息整理完直接以JSON格式存储。
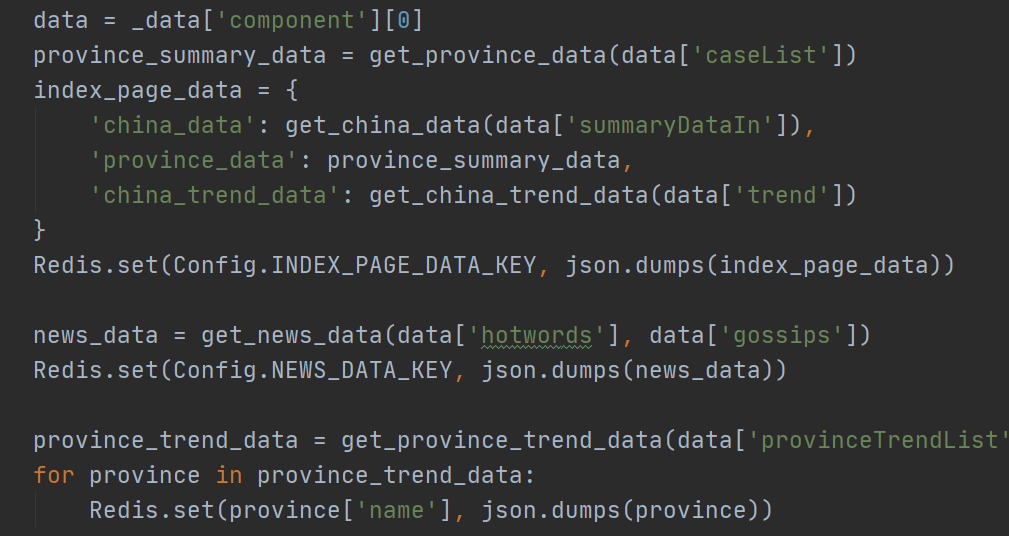
(3)之后是定时更新,因为百度说是早上7-9点会更新,但是具体时间并不确定,所以设置了定时任务,每6个小时爬取一次数据,保证数据的时效性。

(4)之后就是前端用ajax按照对应接口获取对应数据

6.阅读《构建之法》第四章至第五章的内容,结合在构建之法中学习到的相关内容,结对伙伴分别撰写结对开发项目的心路历程与收获,并评价结对队友。
221701133心路历程与收获,还有评价队友:
作为两人中的短板,自己确实有诸多不足,充当着拖后腿的角色,框架不会用,编写有问题算是近日的常态,不过在被队友次次要求修改后,倒是得到了不小的提升,同时也发现了不少独立编程时没有看到的bug,算是一次很有收获的体验吧。另外,我也发现,一份好的代码,不仅是对功能的实现以及性能的优秀,同时也需要是队友可以接受的编写形式。结对过程中,在与队友相互探讨的时候,一方面可以知晓自身的不足,并学习到新的知识,另一方面也互相成为了测试并查找代码bug或不足的审查员,相互精益求精的过程既是为了项目的顺利开展,也是在不断相互提升的过程。嗯,总的来说,队友很强,我学到了不少。
021700511心路历程与收获,还有评价队友:
这次作业并不复杂,就是时间短了点。再吐槽下百度的疫情地图,爬取到的数据非常乱,整理了一段时间才找到需要用的数据。之后爬完数据后的操作都中规中矩,没什么值得多提的了。
这个项目采用前后端分离来写,这样分工明确,不会互相干扰。由于队友并不会使用前端框架,考虑到实际页面并不多,所以就不用框架,直接写这三个页面,效率也不会比用框架差。
评价:队友会的技术虽然不多,但还是完成了不少的东西,我提出的需求都能快速地解决,很棒!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号