
BUAA_OO_第三单元总结
面向对象第三单元总结
一、实现规格所采取的设计策略
首先,先看public instance model non_null要创建哪些,对类的组成成员有个了解,但是不立马实现,不随意开ArrayLsit存,因为可能两个合在一起用HashMap更好。例如 Person类中用HashMap存acquaintance和value更好。
之后就是从易到难的去实现。例如contains,equals,setxxxx或getxxx等十分容易的函数。实现的时候要关注requires和ensures来理解相应的需要是什么,返回值是什么。
当实现完简单的规格后。就需要去实现那些比较长的规格。我采取的策略是先读懂规格在干什么,先整个了解各个函数在做什么,方便优化,防止TLE。当了解完之后,就会采取相应的方法去实现,顺带优化之前的一些容易的方法。例如算group的value Sum的时候,就不需要重复的循环,而是在加入人的时候就维持一个变量来存取。
二、基于JML规格来设计测试的方法和策略
本单元我对于我写的比较薄弱的地方进行了JML测试,例如采用了junit来测试sim,qci,qbs等。不过我在写的时候十分仔细,并且多次进行了形式验证,所以不会出现抛异常错误这种错误以及函数实现的大问题。
但是本单元最大的难点就是防止超时的问题,例如qbs,qgvs,qgam如果照着规格进行翻译,必超时。所以在实现的时候,还需要判断一下自己的算法的时间复杂度是不是O(n^2),如果是,那可能就需要换方法了。让复杂度降下来。
所以为了测运行时间,用到python来测cpu运行时间(大佬写的程序)。并且自动生成极端数据来测试时间。根据时间来判断方法是否会被TLE。
判断正确性上,还是用到了对拍。和同学之间比对输出结果来找一些bug,例如整数除法这种会舍弃尾数,并不是我们数学上理解上的那种运算。
三、总结分析容器选择和使用的经验
容器我选用了ArrayList,HashMap,PriorityQueue。
在找成员在不在的时候,或是找特定的成员时。HashMap的效率以及使用上会明显优于ArrayList。并且HashMap可以实现覆盖,相同的key对应的value可以修改,所以基本上我的所有数组都是由HashMap去实现的。
不过在移出容器中的数据时。还是那个问题,别采用for的方式去删除,会出错,要采取迭代器的方式。或者是
public int deleteColdEmoji(int limit) {
emojiIdHeat.entrySet().removeIf(entry -> (entry.getValue() < limit));
messages.entrySet().removeIf(entry -> ((entry.getValue() instanceof EmojiMessage)
&& !containsEmojiId(((EmojiMessage) entry.getValue()).getEmojiId())));
return emojiIdHeat.size();
}
这样的lambda表达式。
最后我再总结一下PriorityQueue这个优先队列。我是用这个容器的目的,是为了在找最短路径的时候进行一个堆优化。这个容器在一开始我理解错了用法,我以为在add的时候,会对列表中所有的元素进行排列。谁知道不是并且还不会覆盖,机制是将该插入元素按照大小插进去,并不会排余下的元素。所以在使用的时候,不得不改变一下思路,在每一次遍历的时候都加进队列,当出堆的时候,判断改成员的最短路径是否找到,如果找到了,就弹出下一个。
Person p = waiting.poll();
while (alFind.containsKey(p.getId()))
{
p = waiting.poll();
}
这个队列的用法还需要写一个compare函数。
static class MyComp implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
return ((MyPerson) o1).getDistance() - ((MyPerson) o2).getDistance(); } }
四、总结性能问题
性能上在查联通性上,算value,算ageValue的时候,以及最短路径会出现问题。原因可能就是将问题想简单了,认为翻译jml就行了。但是这样发现,复杂度往往是O(n^2)。所以在写的时候,要将整个代码了解清楚,知道这个函数在干什么,以及和另外函数的联系。
例如算value的情况,完全可以在add或delete的时候,对value进行操作,再取value的时候完全不需要遍历,直接返回value就可以了,大大提高了效率。
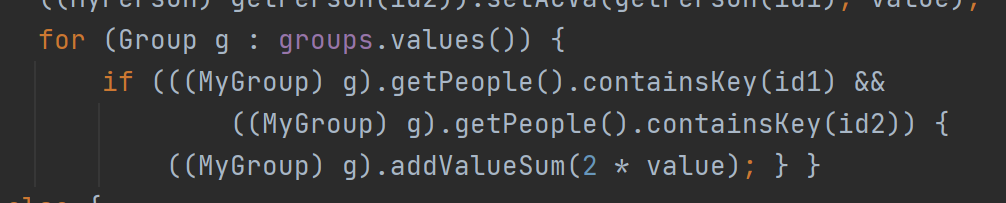
再一个在查询连通块数的时候。不能够按照isCircle去遍历,必超时。而是去用并查集,或是直接深度搜索递归,可以有效解决这个问题。
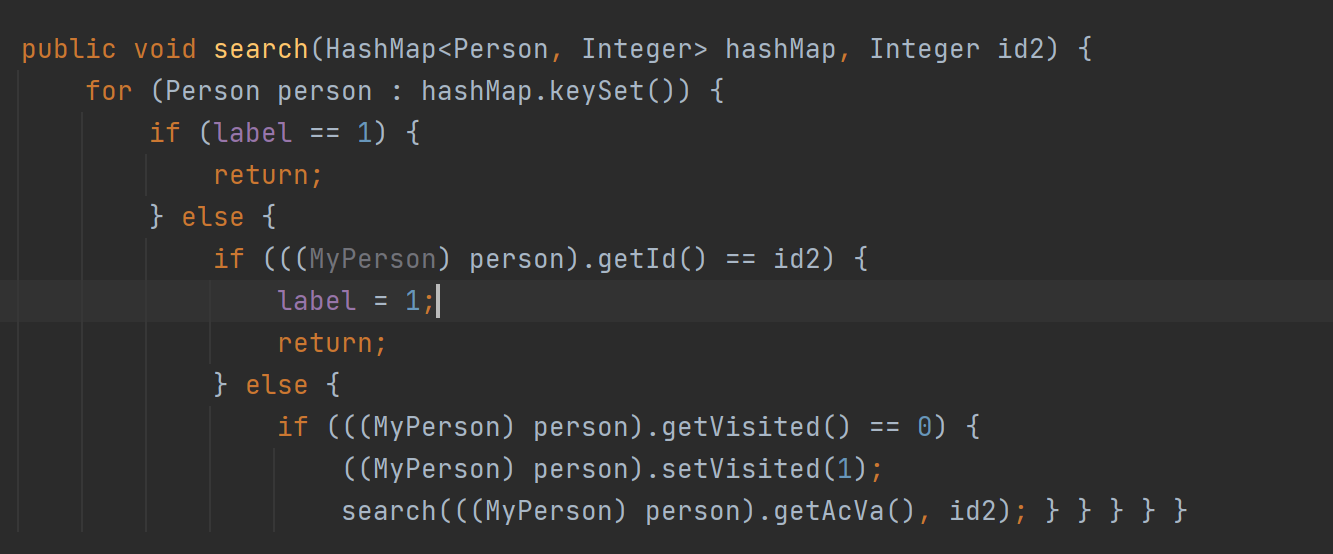
在算ageValue的时候,如果按指导书上说的,虽然一个函数里用的是一个for,但是殊不知,这个for里面调用了另一个函数,这个函数也在for,从而就复杂度O(n^2)了。所以这也是一样的解决思路,将复杂度换成O(1)。跟value的解决方法类似,在add,delete的时候操作好。
最后就是在查最短路径的时候,如果用弗洛伊德算法,直接就tle了,复杂度是O(n3)。如果用不优化的迪杰斯特拉算法的话,时间复杂度是O(n2)。但是写的时候就会发现,每次都要去遍历找最小值的复杂度很慢,很拖累性能。所以解决方法就是设计个堆,使得堆顶的元素是最小的,直接取就够了,大大增强了效率。我采取的就是用了java自带的PriorityQueue。

五、梳理作业架构设计
这次作业的架构是由规格去提供,自己没有改变很多。总体就是Person,Message们,Group,Network这几个大类,以及抛异常的类。Network中进行将人加入群聊,发各种信息,算认识人的各种操作,大体上应该就是这样。相对来说这次单元的作业并不像前两次那么难,架构上面相对来说不难,极易理解。难点在于有些函数的实现上,考虑时间复杂度上。
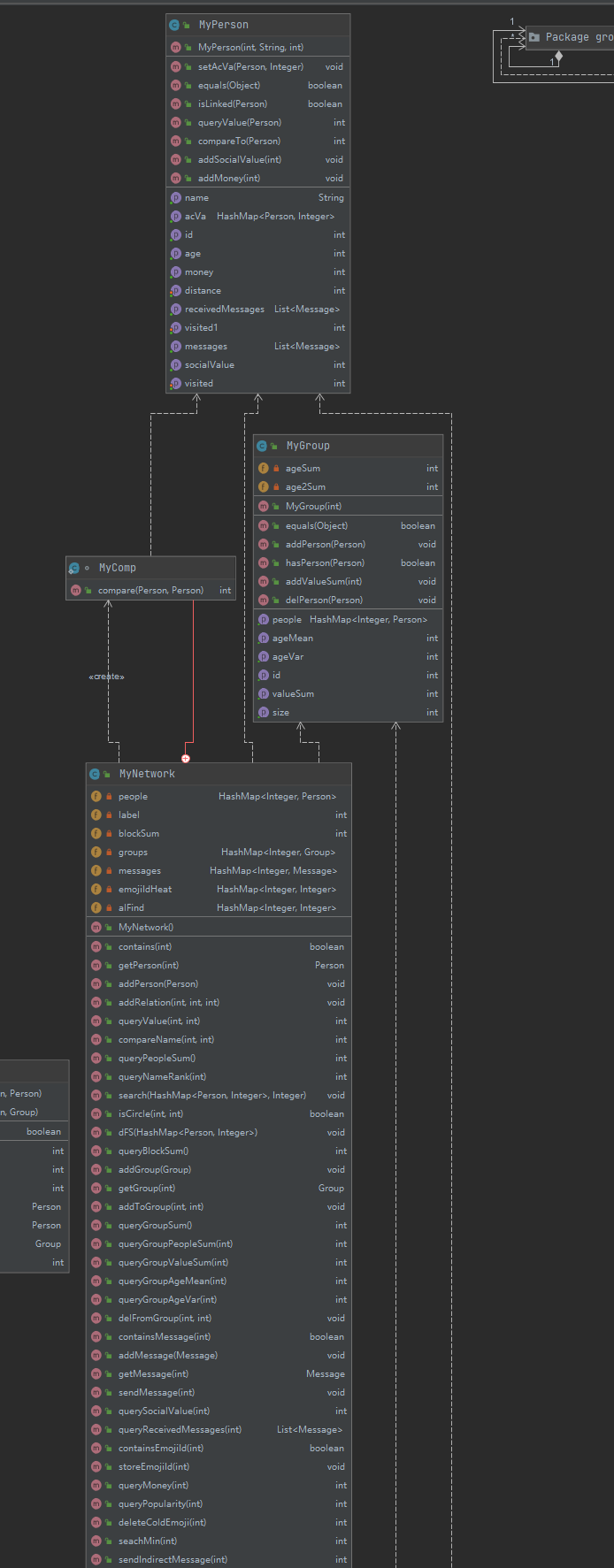
图模型构建
大体上就是每个人有一个认识人的列表,包括亲密度。这样就构成了一张关系图。

维护策略
作业架构的维护策略,大致上是看规格来写,所以大的维护不用操心。就是注意一些新加的函数,与原来的函数之间的关系。
六、心得体会
这个单元的作业相对来说,比较简单。但是细节非常多,一个函数不小心写少了,粗心了一下,可能强测就是全wa。所以这个单元虽然不需要费很多力气去构造,但是要十分仔细。
另一个就是不能被这个规格带着跑了,它只是告诉你这个函数或是这个类该干什么,但是实现还是需要你自己去实现。所以在一些复杂度高的函数中,自己要去想办法,将复杂度降下来。要说这次作业要注意的,可能就是我在性能上说的那几个操作,其他的就是细心的去完成就够了。
总的来说,这个单元的作业,还是非常有趣的,有点像填空。庆幸自己并没有被几百行的规格吓到,耐心的读完,并且细心地检查,没有出锅。希望下一个单元也可以这样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号