Hadoop综合大作业 要求:
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。

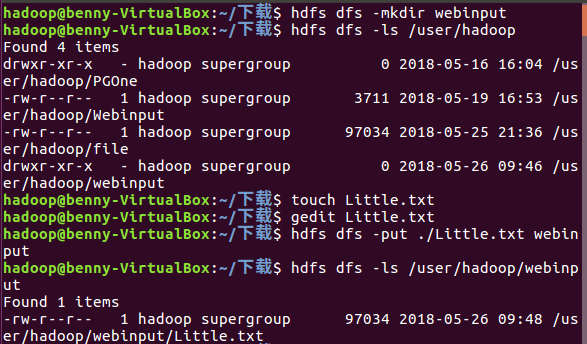
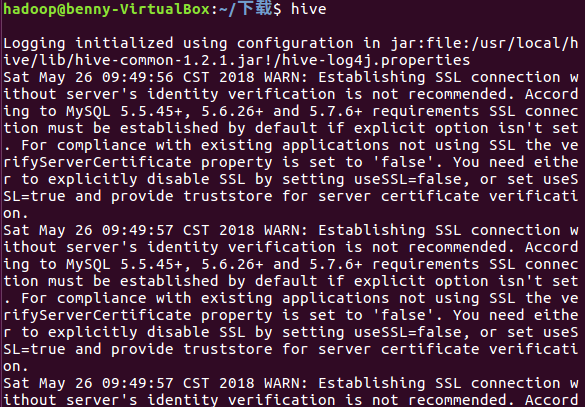

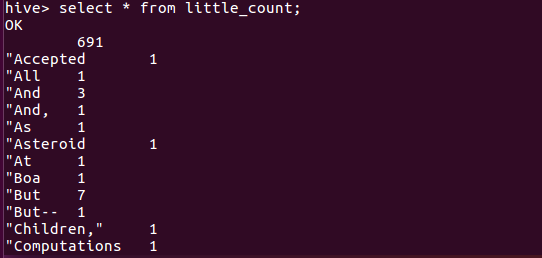
问题:因为我是用空格作为分隔所以有些词连标点符号也一起分析统计。
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas import openpyxl url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/' res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') def getClick(newsUrl): newId = re.search('\_(.*).html', newsUrl).group(1).split('/')[1] click = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newId)) return click.text.split('.html')[-1].lstrip("('").rstrip("');") def getNews(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') newsDict = {} info = soupd.select('.show-info')[0].text newsDict['title'] = soupd.select('.show-title')[0].text dt = datetime.strptime(info.lstrip('发布时间:')[0:19], '%Y-%m-%d %H:%M:%S') if (info.find('作者:') > 0): newsDict['author'] = re.search('作者:((.{2,4}\s|.{2,4}、){1,3})', info).group(1) if (info.find('审核:') > 0): newsDict['check'] = re.search('审核:((.{2,4}\s){1,3})', info).group(1) if (info.find('来源:') > 0): newsDict['sources'] = re.search('来源:((.{2,50}\s|.{2,50}、|.{2,50},){1,5})', info).group(1) content = soupd.select('.show-content')[0].text.strip() click = getClick(newsUrl) # print(click,title,newsUrl,author,check,sources,dt) newsDict['click'] = getClick(newsUrl) # 调用getnewsclick()获取点击次数 newsDict['content'] = content return newsDict def getListPage(listPageUrl): res=requests.get(listPageUrl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') pagelist = [] for news in soup.select('li'): if len(news.select('.news-list-title')) > 0: a = news.select('a')[0]['href'] pagedict = getNews(a) # 调用getnewsdetail()获取新闻详情 pagelist.append(pagedict) return pagelist # listPageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/' resn = requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/') resn.encoding = 'utf-8' soupn = BeautifulSoup(resn.text,'html.parser') n = int(soupn.select('.a1')[0].text.rstrip('条'))//10+1 total = [] listPageUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/' pagelist = getListPage(listPageUrl) total.extend(pagelist) pan = pandas.DataFrame(total) pan.to_excel('result.xlsx') # 导出为Excel表格 pan.to_csv('result.csv') # 导出为csv文件 for i in range(2,4): listPageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) getListPage(listPageUrl)

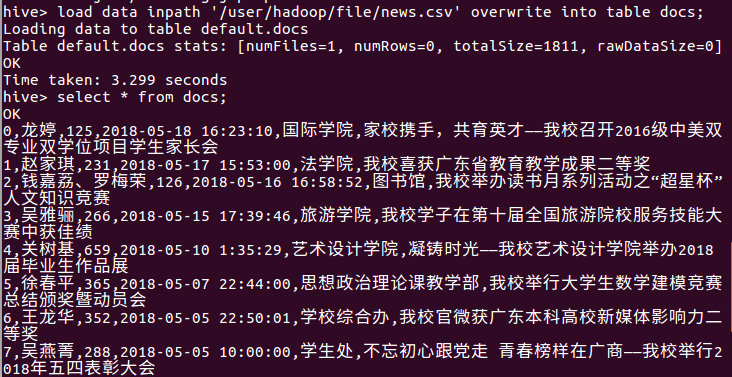
爬的是校园新闻网,截取部分图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号