

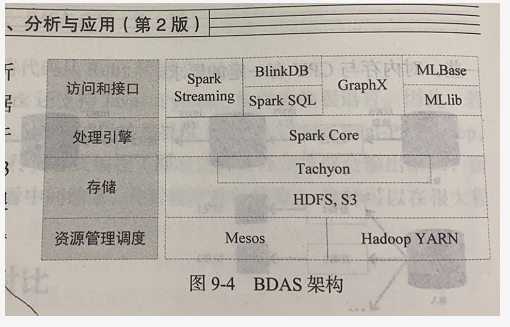
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
Spark生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLlib和GraphX 等组 件,各个组件的具体功能如下。
(1)Spark Core
Spark Core 包含 Spark的基本功能,如内存计算任务调度、部署模式、故障恢复、存储管理等,主要面向批数据处理。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景。
(2)Spark SQL
Spark SQL允许开发人员直接处理RDD,同时也可查询HiveHBase 等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员不需要自己编写Spark应用程序开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析。
(3)Spark Streaming
Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用SparkCore 进行快速处理。Spark Streaming支持多种数据输人源,如Kafka、Flume 和 TCP 套接字等。
(4)MLlib(机器学习)
MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作。
(5)GraphX(图计算)
GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,GraphX性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
需要说明的是,无论是Spark SQL、Spark Streaming、MLlib 还是GraphX,都可以使用Spark Core 的API处理问题,它们的方法几乎是通用的,处理的数据也可以共享,不同应用之间的数据可以无缝集成。
2.请详细阐述Spark的几个主要概念及相互关系:Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster Manager
Master: 常驻master守护进程,负责管理worker节点,从master节点提交应用。
Worker: 常驻worker守护进程,与master节点通信,并且管理executor进程。运行一个或多个Executor进程,相当于计算节点。
RDD: 是弹性分布式数据集(ResilientDistributed Dataset)的英文缩写,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG: 是Directed Acyclic Graph(有向无环图)的英文缩写,反映RDD 之间的依赖关系。
Application:application是Spark API 编程的应用程序,它包括实现Driver功能的代码和在程序中各个executor上要执行的代码,一个application由多个job组成。其中应用程序的入口为用户所定义的main方法。
job:action的触发会生成一个job,Job会提交给DAGScheduler,分解成Stage
stag:DAGScheduler 根据shuffle将job划分为不同的stage,同一个stage中包含多个task,这些tasks有相同的 shuffle dependencies。
task:被送到executor上的工作单元,task简单的说就是在一个数据partition上的单个数据处理流程。
driver:驱动器节点,它是一个运行Application中main函数并创建SparkContext的进程。application通过Driver 和Cluster Manager及executor进行通讯。它可以运行在application节点上,也可以由application 提交给Cluster Manager,再由Cluster Manager安排worker进行运行。Driver节点也负责提交Job,并将Job转化为Task,在各个Executor进程间协调Task的调度。
executor:executor 是真正执行计算任务的组件,它是application运行在worker上的一个进程。这个进程负责Task的运行,它能够将数据保存在内存或磁盘存储中,也能够将结果数据返回给Driver。
Claster Manager:负责集群的资源管理和调度,为运行在资源管理框架上的应用程序分配资源。
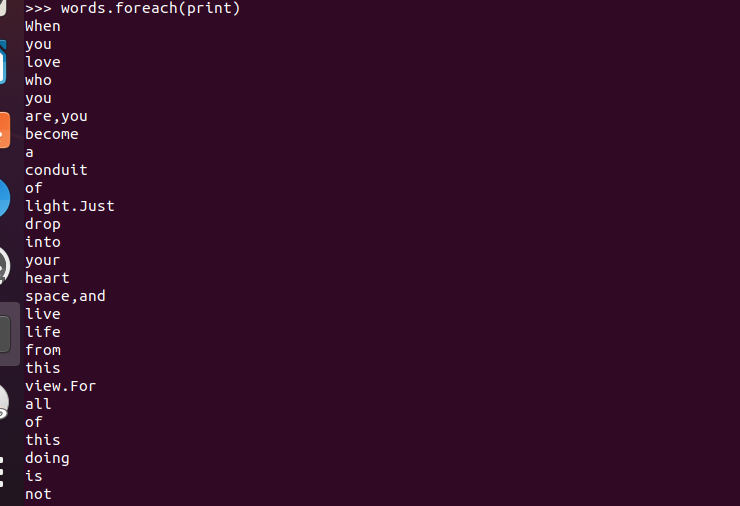
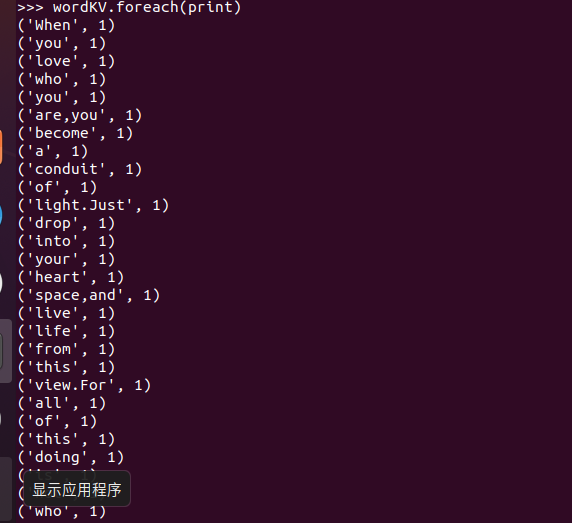
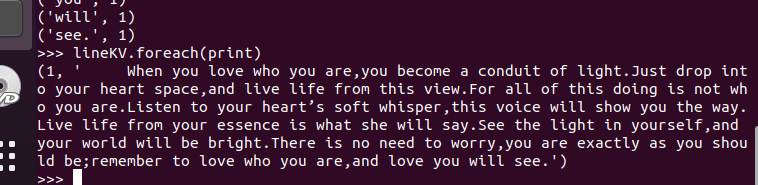
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号