Amazon新一代云端关系数据库Aurora(下)
本文由 网易云 发布。
作者:郭忆
本篇文章仅限内部分享,如需转载,请联系网易获取授权。
故障恢复
MySQL基于Check point的机制,周期性的建立redo log与数据页的一致点。一旦数据库重启,从记录的Check point开始,根据redo log,对相应的数据页进行更新,对于已经提交的事务则确保事务更新持久化到硬盘的数据页中,对于未提交事务,利用数据页对应的roll pointer指针找到对应的undo log,进行回滚。MySQL 一般5分钟一个check point,在故障恢复过程中,由一个线程负责redo log的回放,整个过程数据库实例完全是停服的。
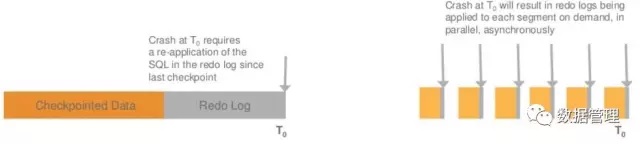
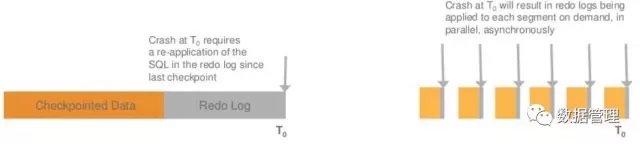
与MySQL 相同的是Aurora 在故障恢复过程时,首先也必须要找到一个一致性点,但是与MySQL不同的时,这个一致不要求所有的数据页是一致的,Aurora只要求找到VDL,确保日志的一致性。
基于read quorum机制,Aurora可以确保对于每一个PG,读到满足writer quorum的redo log record,从而建立VDL。对于每个存储节点,大于VDL的redo log记录将被删除。另外,虽然论文中并没有提,但是由于Aurora的Cache是独立于数据库进程的,所以当仅是数据库实例重启时,Cache内Page LSN大于VDL的数据页同样也需要被清理掉,因为这部分数据页对应的redo log并没有持久化到存储系统中。
建立VDL后,数据库即可以开始进行正常的读写访问。对于没有被提交的事务,由于undo写入的同时也会写redo,并且存在在同一个MTR中,所以undo也是完整的,根据undo可以完成对事务的回滚。但是与MySQL不同的是未提交事务的回滚是后台异步在存储节点完成的。同时,Aurora的redo log的更新是根据page待修改记录的多少来按需进行合并的,并且由于底层存储系统redo log和数据页分散在多个存储节点的segment上,所以可以并行进行数据页的合并。
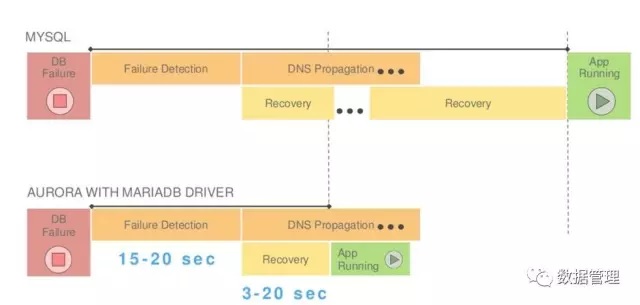
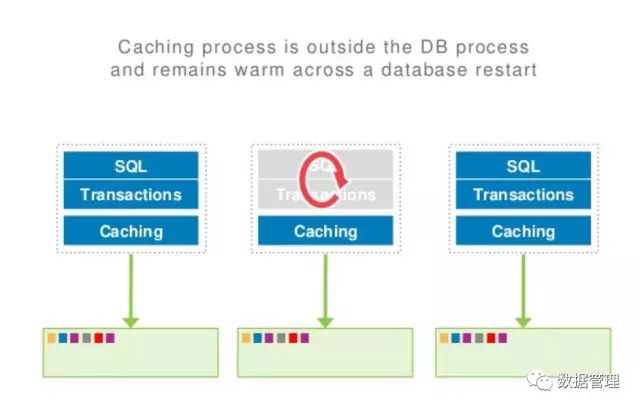
经过AWS 官方的测试,Aurora在10W 写QPS的压力下,故障恢复只需要10秒。另外值得一提的是,与MySQL Buffer Cache是进程内分配的内存空间不同,Aurora的Buffer Cache是独立于数据库进程的,这样做的一个好处就是数据库宕机以后,不会丢失热点,当然这也仅限于数据库实例宕机,如果是系统宕机,就没用了。
性 能
测试对象为Aurora,MySQL 5.6,MySQL5.7,分别在5种规格下(最大规格为32 vcpus,244G内存,最小的规格为2 vcpu,15G 内存,每种规格为前一个规格的一半vcpu和内存)的sysbench 纯读和纯写的压测。测试数据量为1G,所以是全内存的测试。
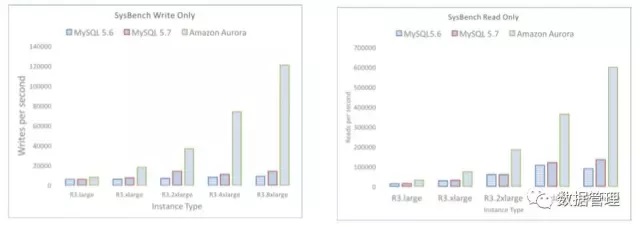
性能对比还是很明显的,得益于大幅减少的跨网络IO以及基于log-structured storage的数据结构,Aurora在r3.8xlarge规格下写可以达到每秒12W。由于Aurora可以创建多个只读实例,所以Aurora在r3.8xlarge规格下读可以达到60W(文章中并没有提及是否 使用了Aurora,但是在全内存场景下,笔者猜测,应该是基于多个replica达到的)
更多高级特性
在线修改表结构
Aurora的Online DDL相较于MySQL在实现上也非常有特色,Aurora目前仅支持在线加列(列允许为空),MySQL 5.6开始,加列操作也支持在线,但是体验较差,我们首先来看一下MySQL 5.6的在线加列过程:
MySQL 5.6 的在线加列分为3个过程:
Prepare: 持有MDL(MetaDataLock)排它锁,创建新的frm文件,更新内存数据字典,生成临时idb文件(记录增量),释放排它锁;
Execute:逐行遍历每一条记录,按照新的表结构构造记录,所有的更新操作都被记录在idb文件中;
Commit: 重新持有排它锁,将临时idb文件中的更新回放到表中,如果更新频率非常高,这个时间可能会比较长,最后临时文件被删除,rename新表。
这样一个流程实际让我们想到了利用Percona的Xtrabackup对数据库在线备份和恢复的过程,允许拷贝期间数据的短暂不一致,然后利用拷贝数据期间的row_log日志最终确保所有数据的一致性。
这样的设计满足了在线修改表结构的需求,但是由于存在全表拷贝,耗时往往非常长,同时最后阶段的加锁时间也不确定,在DBA 使用过程中,往往提心吊胆。
Aurora的设计则显得更为巧妙,很容易让人联想到LVM的Copy-on-write在线snapshot设计,修改过程仅仅只是修改原数据,并不涉及具体的数据拷贝,数据的拷贝是在该数据被修改时才完成的。

在Aurora中执行一条在线加列的DDL操作非常快,这是因为处理该请求系统只是在一个Schema Version Table的系统表中增加一行记录。接下来的DML,Aurora采用了modify-on-write的策略,以Page为单位,如果一个page的LSN大于加列DDL的LSN,则说明,该page已经被修改了schema,所以在DML发生前,就需要将该数据页按照新的schema格式进行存储。对于读操作,如果这个数据页还没被修改过,则直接在内存里面加一个空列进行返回给客户端。
由于Aurora的Online DDL只是增加一条数据库记录,所以速度相比MySQL快了很多个数量级。
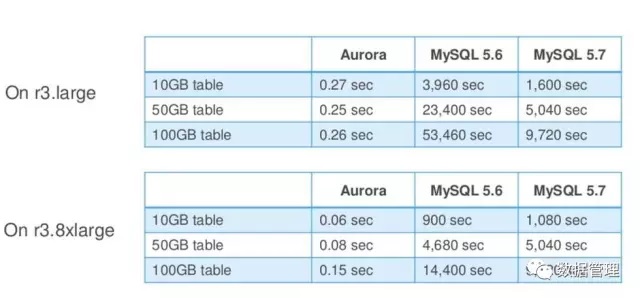
地理位置空间索引
Aurora 与MySQL 5.6一致,支持空间数据类型(Point、POLYGON...)和空间关系函数(ST_Contains、ST_Distance...), MySQL 5.7 InnoDB也开始支持空间地理索引,对大数据集下的查询性能有很大的提升。Aurora 也支持空间地理索引,但是与MySQL 5.7 R Tree的实现方式不同,他是通过空间填充曲线对多维数据进行降维,基于B Tree实现的,这个与MongoDB更为类似。
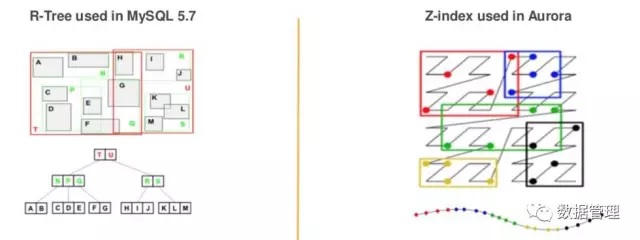
MySQL 5.7的Spatial Index实际是根据最小边界矩形来构建的R Tree。树顶端的两个节点代表的分别是最外层的两个矩形,每一个子树就是该矩形内的所有的节点。然后再根据最小边界矩形规则,构建子节点。当我们要查询某个范围内的所有节点时,可以通过这个范围跟各个矩形是否有重叠来确认查询范围,从最顶端的两个节点代表的矩形开始查找。如果有重叠,就需要查询该子树内的节点。基于R-tree实现的空间地理索引的缺点在于构建成本比较高昂。
Aurora的实现则是将多维数据首先利用一定的算法(时间空间曲线Z-index)进行降维,转换成字符串,然后利用B-Tree方式进行存储。
在线Point-in-time Restore
MySQL 企业版有一个对DBA很有用的功能就是Flash back,可以实现将数据库在线回滚到指定的时间点,对于误操作或者新上线BUG导致的数据修复非常有用,原理上他是基于Row格式的Binlog(会保存修改的前项和后项)进行逆向执行到指定位置实现的。
Aurora提供了两种针对上述场景的修复功能,在线PITR(Point-in-time restore)和离线PITR,前者是在原实例的基础上直接进行数据回滚,恢复期间数据库是可用的,后者是通过备份恢复出一个新的实例,恢复期间新的实例是不可用的。
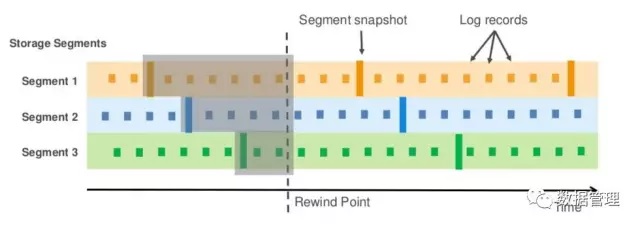
与MySQL 基于binlog的逆向执行不同,Aurora是基于redo log record来实现的。Aurora底层每个存储节点都会定期对存储节点上所有segment进行快照,与LVM类似,只备份元数据,如果某个segment中的某个block数据被重新写,则需要首先将数据拷贝到指定的区域(purchased rewind storage),然后更新该block。
当我们要进行数据恢复时,首先我们找到要恢复的时间点以前最近的所有存储节点上segement快照,然后根据该快照对应的lsn之后的redo log record就可以完成数据的修复。(rewind window 内的redo log record是不会被清理的)
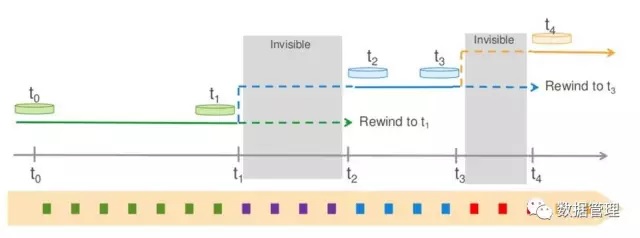
在很多场景下,我们一次是无法精确定位到我们需要的时间点的,这时候,Aurora会根据redo log recod的可见性来快速实现时间点的前进和后退。如图所示,当我们从t2时间点恢复到t1时间点时,我们只需要将t1-t2之间的redo log record不可见即可。当我们希望从t4回滚到t3时,我们只需要将t3-t4和t1-t2之间的redo log record设置不可见即可,当然这必须满足MTR的原子性要求。
总 结
做架构设计的人有一个共识,没有最完美的架构设计,只有最适合的架构设计。Aurora 应该说就是这种理念最完美的诠释。在计算与存储分离的云基础设施之上,通过仅传输redo log,大幅减少跨网络的IO数据传输,将产生大量IO的数据页合并和持久化交由本地存储来解决,大幅减缓了网络延迟对数据库性能的影响。
另外,基于log-structured storage的数据页合并,相比Check point,可以更加高效的合并针对同一个数据页的更新,这些无疑提高了数据库的写入性能。多个replica共享同一个storage volume,多副本并发读取,大幅提高了数据库的读性能。总体来说,
Aurora 对于云端数据库的架构设计具有划时代的意义,充分利用了云基础设施的架构特性,将数据库性能做到极致。
参考文档
1. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases SIGMOD’17, May 14 – 19, 2017, Chicago, IL, USA.
2. AWS 2016 re:Invent Amazon Aurora Deep Dive
3. AWS Aurora blog: https://aws.amazon.com/tw/blogs/database/category/aurora/?nc1=h_ls
4. Percona live 2016 Amazon Aurora Deep Dive
5. https://dev.mysql.com/
网易有数:企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。可点击这里免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号