
Flink简单认识
流式数据的一些实际应用场景
-
电商:快速响应市场需求和变化
-
物联网:获取传感器的数据
-
物流:订单的实时变化
-
金融:资金的动态实时变化
……
流式数据的一些发展和演变
有界流与无界流
-
有界流数据是有量的,一般是以某个时间点或者指定一些范围
-
数据没有定量,可以是无穷尽,现实生活中大部分流式数据基本都是无界流数据
流处理和批处理
- 流处理简单理解:数据不做囤积,得到一条数据就进行一次数据处理
- 批处理:以事务为单位对数据进行处理
传统事务处理
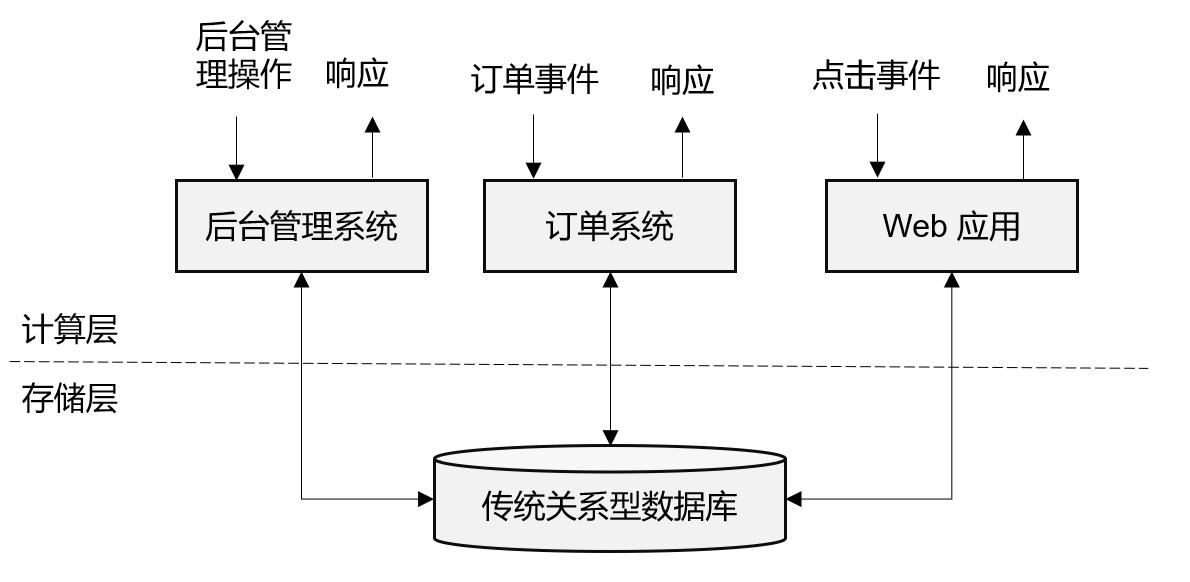
计算和存储分开,计算的结果依托于一些关系型数据库进行存储,当需要某些数据的,需要花费一定时间从数据库中读取所需数据。一个数据库可以服务多个应用程序。
有状态的流处理
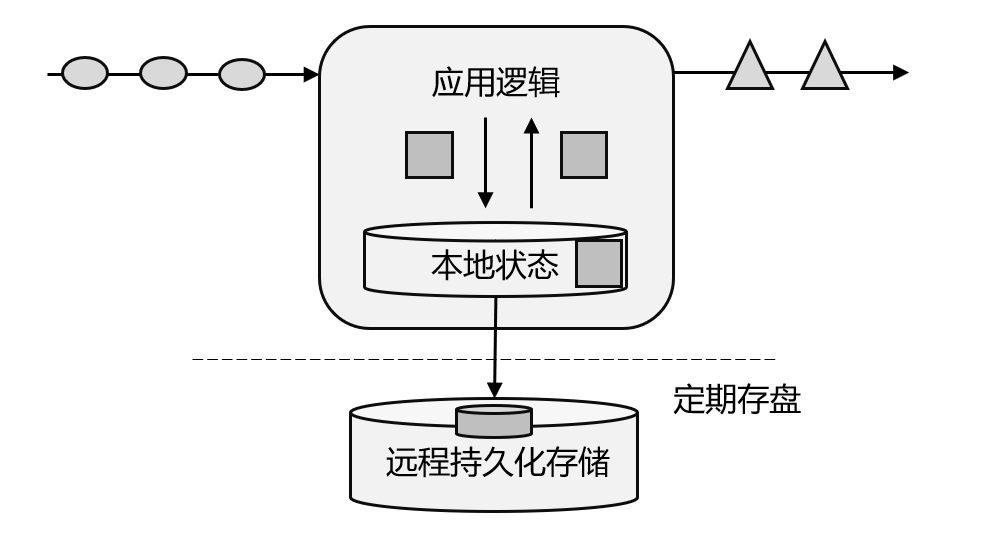
将需要进行流处理的数据额外保存至本地内存(需要借助一些存储系统),然后根据计算逻辑对数据进行处理,
应用场景
事件驱动型应用(Event-Driven)
一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。也就是最常理解的:来一个数据处理一个数据。
- 其优势在于
- 无需借助远程数据库,直接访问本地内存,具有更好的吞吐和低延迟。
- 向远程数据库进行同步数据时,可以在闲暇时、异步或者增量同步数据,因此正常处理事件的影响较小。
- 不与其他服务共同使用一个数据库,因此不需要考虑同步数据库的结构问题。
数据分析(Data Analysis)型应用
数据分析任务需要从原始数据中提取有价值的信息和指标。传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。为了得到最新数据的分析结果,必须先将它们加入分析数据集并重新执行查询或运行应用,随后将结果写入存储系统或生成报告。
- 其优势在于
- 省掉了周期性的数据导入和查询过程,因此从事件中获取指标的延迟更低。
2. 不需要考虑批量查询必须处理那些由定期导入和输入有界性导致的人工数据边界问题。
2. 简化应用抽象,使得操作、使用和故障恢复上都更加便利。
- 省掉了周期性的数据导入和查询过程,因此从事件中获取指标的延迟更低。
数据管道(Data Pipeline)型应用
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。简单说就是数据清洗。
- 其优势在于
- 和周期性ETL作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。
- 可以持续消费和发送数据,因此用途更广,支持用例更多。
Lambda架构
实时的流式数据处理无法保证数据的完整性,而批处理又无法保证数据的实时性,因此将批处理的结果补充到实时上,诞生了lambda形式的架构。
Flink的特性
核心特性
- 高吞吐和低延迟:百万事件/秒,毫秒级延迟
- 高准确性:提供了事件时间(event-time)和处理时间(processing-time)语义。对乱序事件流数据仍能提供一致且准确的结果。
- 精确一次的状态一致性保证
- 兼容常用的存储系统
- 高可用
- 能够*更新应用程序代码并将作业(jobs)迁移*到不同的Flink集群,而*不会丢失应用程序的状态*。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号