
第19讲、Odoo 18 导入导出功能源码详细解读
目录
导入导出功能概述
Odoo的导入导出功能是系统中非常重要的实用工具,它允许用户将数据从Odoo系统中导出到外部文件,或者从外部文件导入数据到Odoo系统。这些功能在系统初始化、数据迁移、批量更新、数据备份等场景中特别有用。
核心源码结构与位置
导入功能的核心源码位置
| 功能 | 路径 | 描述 |
|---|---|---|
| 导入主逻辑 | odoo/addons/base_import/models/base_import.py |
处理导入的控制器和模型逻辑 |
| 导入控制器 | odoo/addons/base_import/controllers/main.py |
处理前端上传导入文件 |
| 导入模板UI | odoo/addons/base_import/views/base_import_templates.xml |
导入弹窗的 HTML 和 JS 模板 |
| 字段匹配逻辑 | odoo/addons/base_import/models/base_import.py 中的 _parse_import_data |
负责字段名称与模型字段的映射 |
| 导入界面入口 | web/views/webclient_templates.xml |
在 Tree 视图中添加导入按钮 |
| 前端交互逻辑 | odoo/addons/base_import/static/src/js/import_action.js |
控制导入的字段匹配、预览等功能 |
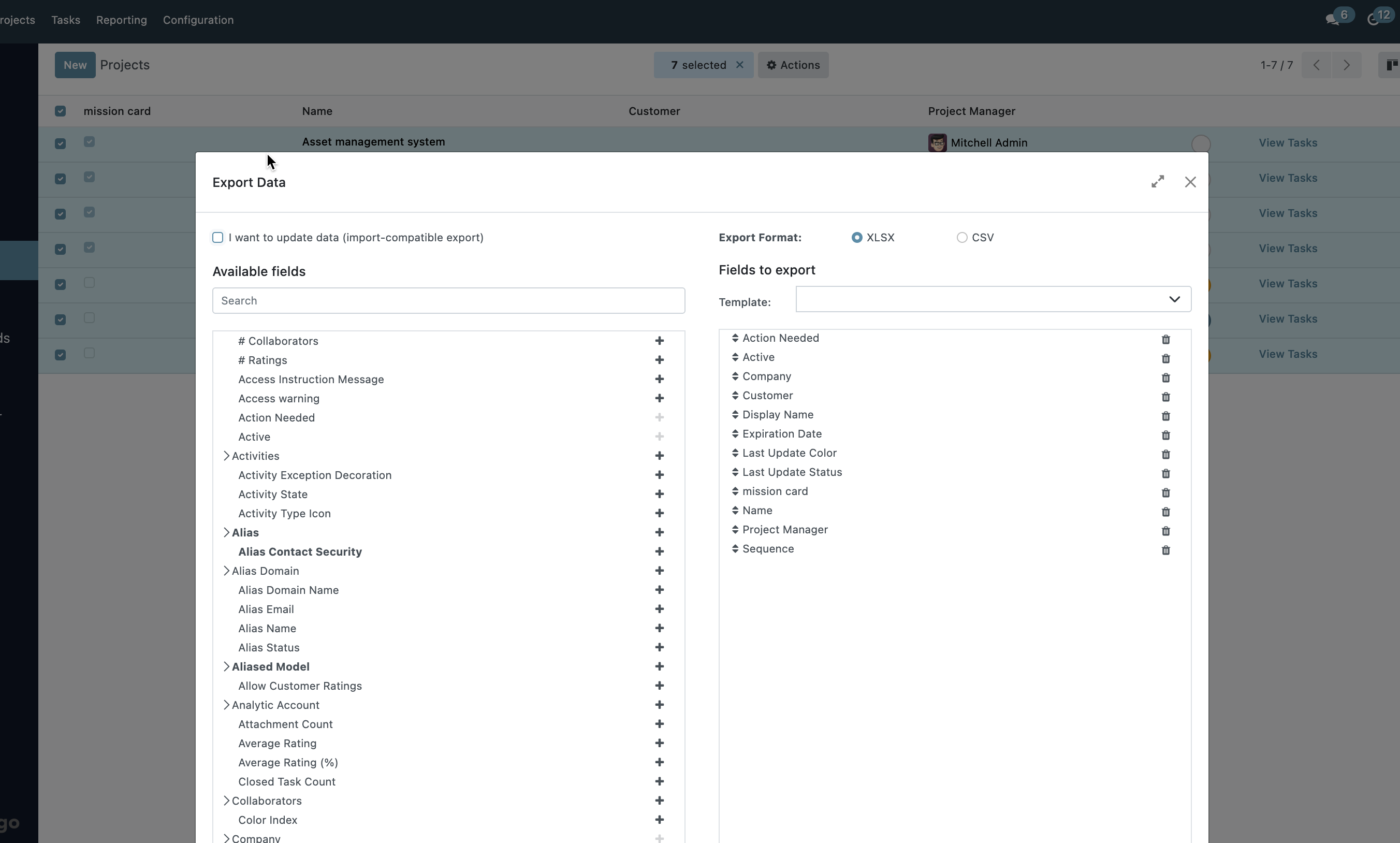
导出功能的核心源码位置
| 功能 | 路径 | 描述 |
|---|---|---|
| 导出主逻辑 | odoo/addons/base/models/ir_exports.py |
管理导出字段模板、导出执行逻辑 |
| 导出向导 | odoo/addons/base/wizard/base_export.py |
控制导出向导(选择字段、格式等) |
| 导出界面 | odoo/addons/base/views/base_export.xml |
导出弹窗的视图定义 |
| 导出控制器(下载) | odoo/addons/web/controllers/main.py 的 Binary 类 |
下载导出的文件(CSV 或 Excel) |
| 字段选择 JS | odoo/addons/web/static/src/js/views/list/list_controller.js |
控制 tree 视图中"导出"操作的按钮行为 |
导入功能核心代码详解
ImportBaseModel类详解
Import类是Odoo导入功能的核心类,定义在odoo/addons/base_import/models/base_import.py中。这个类负责处理整个导入流程,从文件上传、解析、字段映射到最终的数据导入。
class Import(models.TransientModel):
"""
This model is used to prepare the loading of data coming from a user file.
"""
_name = 'base_import.import'
_description = 'Base Import'
# allow imports to survive for 12h in case user is slow
_transient_max_hours = 12.0
# 模糊匹配距离阈值,用于字段映射建议
FUZZY_MATCH_DISTANCE = 0.2
# 字段定义
res_model = fields.Char('Model') # 目标模型名称
file = fields.Binary('File', help="File to check and/or import, raw binary (not base64)", attachment=False)
file_name = fields.Char('File Name')
file_type = fields.Char('File Type')
核心属性解析:
-
_transient_max_hours = 12.0:这个属性设置了导入向导记录在数据库中保存的最长时间。由于导入可能是一个耗时的过程,Odoo允许导入向导记录存活12小时,比标准的瞬态模型存活时间要长。 -
FUZZY_MATCH_DISTANCE = 0.2:这个常量定义了模糊匹配的阈值。在字段映射建议过程中,如果列标题和字段名称的差异度超过0.2,则认为它们不匹配。 -
主要字段:
res_model:目标模型的技术名称file:要导入的文件内容(二进制格式)file_name:文件名file_type:文件类型(MIME类型)
导入流程的核心方法解析
1. 获取可导入字段树 - get_fields_tree
@api.model
def get_fields_tree(self, model, depth=FIELDS_RECURSION_LIMIT):
""" Recursively get fields for the provided model (through
fields_get) and filter them according to importability
"""
方法解析:
- 功能:递归获取指定模型的可导入字段树
- 参数:
model:目标模型的技术名称depth:递归深度限制,默认为3(定义在FIELDS_RECURSION_LIMIT常量中)
- 返回值:包含所有可导入字段及其子字段的树状结构
- 业务意义:
- 这个方法是导入功能的基础,它确定了哪些字段可以被导入
- 它处理了复杂的关系字段(many2one, many2many, one2many),允许用户导入这些关系
- 它过滤掉了不可导入的字段(如只读字段、魔术字段等)
- 对于关系字段,它递归获取关联模型的字段,直到达到指定的深度限制
代码流程:
- 首先添加"External ID"字段,这是一个特殊字段,用于通过外部ID导入记录
- 如果达到递归深度限制,则直接返回
- 获取模型的所有字段及其属性
- 过滤掉魔术字段(如id, create_uid等)
- 处理properties类型的字段(Odoo 18的新特性)
- 对于每个字段:
- 检查是否为只读字段,如果是则跳过
- 创建字段信息字典
- 对于关系字段,递归获取关联模型的字段
- 将字段信息添加到结果列表中
- 返回可导入字段列表
2. 文件解析预览 - parse_preview
def parse_preview(self, options):
"""
Generates a preview of the uploaded file, and performs
fields-matching between the file data and the model columns.
:param options: dict of parsing options
:returns: dict with:
- fields: list of fields to import
- matches: dict of field-matching suggestions
- headers: list of file headers
- preview: list of preview data
- headers_type: list of fields type
- file_headers: list of file headers
- has_headers: boolean indicating if the file has a header row
- advanced_mode: boolean
- batch: boolean
- skip: number of records to skip
- limit: number of records to import
"""
方法解析:
- 功能:生成上传文件的预览,并执行文件数据与模型字段的匹配
- 参数:
options:解析选项字典,包含编码、分隔符等设置
- 返回值:包含预览数据、字段匹配建议等信息的字典
- 业务意义:
- 这个方法是导入向导的核心,它分析上传的文件并尝试自动匹配列与字段
- 它生成预览数据,让用户可以在导入前查看数据
- 它提供字段匹配建议,简化用户的映射工作
- 它检测文件格式、标题行等信息,为后续导入做准备
代码流程:
- 读取文件内容并根据文件类型选择适当的解析器
- 解析文件头部和预览数据
- 提取标题行类型信息
- 获取目标模型的可导入字段树
- 根据标题类型过滤字段
- 生成字段匹配建议
- 准备预览数据和其他信息
- 返回包含所有预览和匹配信息的结果字典
3. 执行导入 - execute_import
def execute_import(self, fields, columns, options, dryrun=False):
""" Imports the file stored in the import object according to the mapping of fields and columns provided
:param fields: list of fields to import
:param columns: list of matching columns
:param options: dict of options for importing
:param dryrun: whether to do a dry run (rollback) or not
:return: dict of results
"""
方法解析:
- 功能:根据提供的字段和列映射导入存储在导入对象中的文件
- 参数:
fields:要导入的字段列表columns:匹配的列列表options:导入选项字典dryrun:是否进行试运行(回滚)
- 返回值:包含导入结果的字典
- 业务意义:
- 这是实际执行导入操作的方法
- 它支持试运行模式,允许用户在不实际修改数据的情况下检查导入结果
- 它处理批量导入,将大文件分批处理以提高性能
- 它处理错误并提供详细的错误报告
- 它保存成功的字段映射,以便将来使用
代码流程:
- 准备导入环境和选项
- 获取目标模型对象
- 读取文件数据
- 转换和解析导入数据
- 处理多重映射和回退值
- 分批处理导入数据
- 对每批数据执行导入
- 如果是试运行或遇到错误,回滚事务
- 保存成功的字段映射
- 返回导入结果
文件解析与字段映射
1. 文件读取 - _read_file
def _read_file(self, options):
""" Reads file content, returns it and file format
:param options: dict of options for reading
:returns: (file_content, file_format)
"""
方法解析:
- 功能:读取文件内容,返回内容和文件格式
- 参数:
options:读取选项字典
- 返回值:文件内容和文件格式的元组
- 业务意义:
- 这个方法处理不同格式的文件读取
- 它支持CSV、XLS、XLSX和ODS格式
- 它处理字符编码和BOM(字节顺序标记)
- 它检测文件类型并选择适当的解析器
代码流程:
- 获取文件内容和类型
- 根据文件类型选择解析器
- 如果是CSV文件,处理编码和BOM
- 如果是Excel文件,使用适当的库(xlrd或openpyxl)打开
- 返回文件内容和格式
2. 字段映射建议 - _get_mapping_suggestion
def _get_mapping_suggestion(self, field_names, header_name, header_type, previous_mapping=None):
""" Attempts to find a field in the mapping that matches the header name
:param field_names: list of field names
:param header_name: name of the header
:param header_type: type of the header
:param previous_mapping: previous mapping
:returns: field name or None
"""
方法解析:
- 功能:尝试找到与标题名称匹配的字段
- 参数:
field_names:字段名称列表header_name:标题名称header_type:标题类型previous_mapping:之前的映射
- 返回值:匹配的字段名称或None
- 业务意义:
- 这个方法是自动字段映射的核心
- 它首先检查之前保存的映射
- 然后尝试精确匹配(技术名称、标签、翻译标签)
- 如果没有精确匹配,尝试模糊匹配
- 它使用编辑距离算法计算字符串相似度
代码流程:
- 检查之前的映射
- 尝试精确匹配
- 如果没有精确匹配,尝试模糊匹配
- 计算每个字段与标题的相似度
- 选择相似度最高且超过阈值的字段
- 返回匹配的字段名称或None
数据验证与转换
1. 数据解析 - _parse_import_data
def _parse_import_data(self, data, import_fields, options):
""" Parses import data, handles date/float/binary fields
:param data: list of lists of values to import
:param import_fields: list of fields to import
:param options: dict of import options
:returns: (data, import_fields)
"""
方法解析:
- 功能:解析导入数据,处理日期/浮点数/二进制字段
- 参数:
data:要导入的值列表的列表import_fields:要导入的字段列表options:导入选项字典
- 返回值:处理后的数据和导入字段的元组
- 业务意义:
- 这个方法处理数据类型转换
- 它验证数据格式
- 它处理特殊字段类型(日期、浮点数、二进制等)
- 它处理空值和默认值
代码流程:
- 获取目标模型和字段信息
- 对每个字段和值:
- 确定字段类型
- 根据类型进行适当的转换
- 处理特殊类型(日期、浮点数、二进制等)
- 验证数据格式
- 返回处理后的数据和字段列表
2. 多重映射处理 - _handle_multi_mapping
def _handle_multi_mapping(self, data, import_fields, options):
""" Handles multiple mapping for the same field
:param data: list of lists of values to import
:param import_fields: list of fields to import
:param options: dict of import options
:returns: (data, import_fields)
"""
方法解析:
- 功能:处理同一字段的多重映射
- 参数:
data:要导入的值列表的列表import_fields:要导入的字段列表options:导入选项字典
- 返回值:处理后的数据和导入字段的元组
- 业务意义:
- 这个方法处理多个列映射到同一个字段的情况
- 它合并文本字段的值
- 它处理多对多字段的多个值
- 它允许用户从多个列导入数据到同一个字段
代码流程:
- 识别多重映射的字段
- 对每个多重映射的字段:
- 获取所有映射到该字段的列索引
- 根据字段类型选择合适的合并策略
- 合并值并更新数据
- 返回处理后的数据和更新后的字段列表
记录创建与更新
1. 导入数据转换 - _convert_import_data
def _convert_import_data(self, fields, columns, options):
""" Converts import data to format suitable for loading
:param fields: list of fields to import
:param columns: list of matching columns
:param options: dict of import options
:returns: (data, import_fields)
"""
方法解析:
- 功能:将导入数据转换为适合加载的格式
- 参数:
fields:要导入的字段列表columns:匹配的列列表options:导入选项字典
- 返回值:处理后的数据和导入字段的元组
- 业务意义:
- 这个方法是数据准备的最后一步
- 它将用户映射转换为ORM可以处理的格式
- 它处理字段路径和子字段
- 它准备最终的导入数据结构
代码流程:
- 准备导入字段列表
- 读取文件数据
- 根据用户映射提取相关列
- 处理标题行和空行
- 转换数据格式
- 返回处理后的数据和字段列表
2. 保存字段映射 - _save_mapping
def _save_mapping(self, fields, columns, options):
""" Saves mapping of fields to columns
:param fields: list of fields to import
:param columns: list of matching columns
:param options: dict of import options
"""
方法解析:
- 功能:保存字段到列的映射
- 参数:
fields:要导入的字段列表columns:匹配的列列表options:导入选项字典
- 业务意义:
- 这个方法保存用户的映射选择
- 它允许系统在将来的导入中提供更好的映射建议
- 它提高了重复导入的用户体验
- 它为不同模型维护单独的映射
代码流程:
- 获取文件标题
- 对每个字段和列的映射:
- 检查是否有有效的映射
- 创建或更新映射记录
- 提交事务以保存映射
导出功能核心代码详解
导出模板管理
Odoo的导出功能通过ir.exports模型管理导出模板,这个模型定义在odoo/addons/base/models/ir_exports.py中:
class IrExport(models.Model):
_name = "ir.exports"
_description = "Export Templates"
name = fields.Char('Template Name')
resource = fields.Char('Model Technical Name')
export_fields = fields.One2many('ir.exports.line', 'export_id', 'Fields')
模型解析:
- 功能:管理导出模板
- 字段:
name:模板名称resource:模型技术名称export_fields:导出字段列表(一对多关系)
- 业务意义:
- 这个模型允许用户保存常用的导出字段集合
- 它简化了重复导出操作
- 它允许在不同用户之间共享导出模板
- 它为不同模型维护单独的导出模板
导出字段行由ir.exports.line模型管理:
class IrExportsLine(models.Model):
_name = 'ir.exports.line'
_description = 'Export Field'
_order = 'id'
name = fields.Char('Field Name')
export_id = fields.Many2one('ir.exports', 'Export', required=True, ondelete='cascade')
模型解析:
- 功能:管理导出模板中的字段
- 字段:
name:字段名称export_id:关联的导出模板
- 业务意义:
- 这个模型存储导出模板中的每个字段
- 它维护字段的顺序
- 它支持复杂的字段路径(如关系字段的子字段)
导出数据处理流程
导出功能的核心方法是export_data,它定义在odoo/addons/base/models/ir_model.py中的BaseModel类中:
def export_data(self, fields_to_export):
""" Export fields for selected objects
:param fields_to_export: list of fields
:returns: dictionary with a *datas* matrix and a *fields* list
:rtype: dict
"""
方法解析:
- 功能:导出选定对象的字段
- 参数:
fields_to_export:要导出的字段列表
- 返回值:包含数据矩阵和字段列表的字典
- 业务意义:
- 这个方法是导出功能的核心
- 它处理字段路径和关系字段
- 它格式化数据以便于导出
- 它支持多种导出格式(CSV、Excel)
代码流程:
- 解析字段路径
- 获取字段信息
- 查询记录数据
- 格式化数据
- 返回结果字典
导出控制器处理文件下载,它定义在odoo/addons/web/controllers/main.py中的Binary类中:
@http.route('/web/export/csv', type='http', auth="user")
def export_csv(self, data, token):
""" Export data as a CSV file
:param data: JSON object containing export data
:param token: security token
:returns: CSV file
"""
方法解析:
- 功能:将数据导出为CSV文件
- 参数:
data:包含导出数据的JSON对象token:安全令牌
- 返回值:CSV文件
- 业务意义:
- 这个方法处理CSV文件的生成和下载
- 它设置适当的HTTP头
- 它处理字符编码
- 它格式化数据为CSV格式
Excel导出由类似的方法处理:
@http.route('/web/export/xlsx', type='http', auth="user")
def export_xlsx(self, data, token):
""" Export data as an XLSX file
:param data: JSON object containing export data
:param token: security token
:returns: XLSX file
"""
方法解析:
- 功能:将数据导出为XLSX文件
- 参数:
data:包含导出数据的JSON对象token:安全令牌
- 返回值:XLSX文件
- 业务意义:
- 这个方法处理Excel文件的生成和下载
- 它使用xlsxwriter库创建Excel文件
- 它支持基本的格式化(如标题行、列宽等)
- 它处理特殊字符和Unicode
自定义Excel导入解析器实现
为了处理复杂的Excel导入需求,我们可以创建自定义的Excel解析器。以下是一个完整的自定义Excel解析器实现:
class ExcelParser:
"""自定义Excel解析器"""
def __init__(self, file_content, options=None):
"""初始化解析器
Args:
file_content: Excel文件内容(二进制)
options: 解析选项字典
"""
self.options = options or {}
self.workbook = None
self.sheets = []
self.current_sheet = None
self.headers = []
self.data = []
# 解析Excel文件
try:
self.workbook = xlrd.open_workbook(file_contents=file_content)
self.sheets = self.workbook.sheet_names()
except Exception as e:
raise UserError(_("无法解析Excel文件: %s") % str(e))
def select_sheet(self, sheet_index=0):
"""选择要处理的工作表
Args:
sheet_index: 工作表索引或名称
"""
if isinstance(sheet_index, str):
if sheet_index not in self.sheets:
raise UserError(_("工作表 '%s' 不存在") % sheet_index)
self.current_sheet = self.workbook.sheet_by_name(sheet_index)
else:
if sheet_index >= len(self.sheets):
raise UserError(_("工作表索引 %d 超出范围") % sheet_index)
self.current_sheet = self.workbook.sheet_by_index(sheet_index)
return self
def parse_headers(self, header_row=0, start_col=0, end_col=None):
"""解析表头行
Args:
header_row: 表头所在行索引
start_col: 起始列索引
end_col: 结束列索引(如果为None,则处理到最后一列)
"""
if not self.current_sheet:
raise UserError(_("请先选择工作表"))
if end_col is None:
end_col = self.current_sheet.ncols
self.headers = []
for col in range(start_col, end_col):
header = self.current_sheet.cell_value(header_row, col)
self.headers.append(str(header).strip())
return self
def parse_data(self, start_row=1, end_row=None, start_col=0, end_col=None):
"""解析数据行
Args:
start_row: 数据起始行索引
end_row: 数据结束行索引(如果为None,则处理到最后一行)
start_col: 起始列索引
end_col: 结束列索引(如果为None,则处理到最后一列)
"""
if not self.current_sheet:
raise UserError(_("请先选择工作表"))
if not self.headers:
raise UserError(_("请先解析表头"))
if end_row is None:
end_row = self.current_sheet.nrows
if end_col is None:
end_col = self.current_sheet.ncols
self.data = []
for row in range(start_row, end_row):
row_data = {}
for col, header in zip(range(start_col, end_col), self.headers):
if col < self.current_sheet.ncols: # 确保列索引有效
cell = self.current_sheet.cell(row, col)
value = self._parse_cell_value(cell)
row_data[header] = value
# 跳过空行
if any(row_data.values()):
self.data.append(row_data)
return self
def _parse_cell_value(self, cell):
"""解析单元格值,处理不同的数据类型
Args:
cell: xlrd单元格对象
Returns:
处理后的单元格值
"""
if cell.ctype == xlrd.XL_CELL_EMPTY:
return ''
elif cell.ctype == xlrd.XL_CELL_BOOLEAN:
return bool(cell.value)
elif cell.ctype == xlrd.XL_CELL_ERROR:
return ''
elif cell.ctype == xlrd.XL_CELL_NUMBER:
# 检查是否为整数
if cell.value == int(cell.value):
return int(cell.value)
return cell.value
elif cell.ctype == xlrd.XL_CELL_DATE:
# 转换Excel日期为Python日期
try:
date_tuple = xlrd.xldate_as_tuple(cell.value, self.workbook.datemode)
if date_tuple[3:] == (0, 0, 0): # 只有日期,没有时间
return "%04d-%02d-%02d" % date_tuple[:3]
return "%04d-%02d-%02d %02d:%02d:%02d" % date_tuple
except Exception:
return str(cell.value)
else: # xlrd.XL_CELL_TEXT 或其他
return str(cell.value).strip()
def get_data(self):
"""获取解析后的数据
Returns:
解析后的数据列表,每项为一个字典
"""
return self.data
def get_headers(self):
"""获取解析后的表头
Returns:
表头列表
"""
return self.headers
代码解析:
-
初始化方法:
- 接收文件内容和选项
- 初始化工作簿、工作表和数据结构
- 使用xlrd库打开Excel文件
-
选择工作表:
- 支持通过索引或名称选择工作表
- 验证工作表是否存在
- 设置当前工作表
-
解析表头:
- 从指定行读取表头
- 支持指定列范围
- 清理表头文本(去除空格等)
-
解析数据:
- 从指定行开始读取数据
- 支持指定行列范围
- 将数据组织为字典列表,键为表头
- 跳过空行
-
解析单元格值:
- 处理不同类型的单元格(空、布尔、错误、数字、日期、文本)
- 转换Excel日期为标准格式
- 处理整数和浮点数
-
获取数据和表头:
- 提供方法获取解析后的数据和表头
- 数据以字典列表形式返回,便于后续处理
自定义导入向导实现
结合自定义Excel解析器,我们可以创建一个完整的导入向导:
class CustomExcelImport(models.TransientModel):
_name = 'custom.excel.import'
_description = '自定义Excel导入'
model_id = fields.Many2one('ir.model', string='目标模型', required=True,
domain=[('transient', '=', False)])
file = fields.Binary('Excel文件', required=True)
file_name = fields.Char('文件名')
sheet_index = fields.Integer('工作表索引', default=0)
header_row = fields.Integer('表头行', default=0)
data_start_row = fields.Integer('数据起始行', default=1)
field_mappings = fields.One2many('custom.excel.field.mapping', 'import_id',
string='字段映射')
@api.onchange('file', 'model_id', 'sheet_index', 'header_row')
def _onchange_file(self):
"""文件变更时,自动解析表头并生成字段映射"""
if not self.file or not self.model_id:
return
# 解析Excel表头
try:
file_content = base64.b64decode(self.file)
parser = ExcelParser(file_content)
parser.select_sheet(self.sheet_index)
parser.parse_headers(header_row=self.header_row)
headers = parser.get_headers()
# 获取模型字段
model_fields = self.env[self.model_id.model].fields_get()
# 创建字段映射
mappings = []
for header in headers:
# 尝试找到匹配的字段
field_match = None
for field_name, field_info in model_fields.items():
if field_info['string'].lower() == header.lower():
field_match = field_name
break
mappings.append((0, 0, {
'excel_header': header,
'field_name': field_match,
}))
# 更新字段映射
self.field_mappings = [(5, 0, 0)] # 清除现有映射
self.field_mappings = mappings
except Exception as e:
raise UserError(_("解析Excel文件失败: %s") % str(e))
def action_import(self):
"""执行导入操作"""
self.ensure_one()
if not self.file or not self.model_id:
raise UserError(_("请提供Excel文件和目标模型"))
# 创建字段映射字典
field_map = {}
for mapping in self.field_mappings:
if mapping.field_name:
field_map[mapping.excel_header] = mapping.field_name
if not field_map:
raise UserError(_("请至少映射一个字段"))
try:
# 解析Excel数据
file_content = base64.b64decode(self.file)
parser = ExcelParser(file_content)
parser.select_sheet(self.sheet_index)
parser.parse_headers(header_row=self.header_row)
parser.parse_data(start_row=self.data_start_row)
excel_data = parser.get_data()
# 转换为Odoo记录
records_to_create = []
for row_data in excel_data:
record_values = {}
for excel_header, value in row_data.items():
if excel_header in field_map:
field_name = field_map[excel_header]
record_values[field_name] = self._convert_value(value, field_name)
if record_values: # 跳过空记录
records_to_create.append(record_values)
# 创建记录
if records_to_create:
target_model = self.env[self.model_id.model]
records = target_model.create(records_to_create)
return {
'type': 'ir.actions.client',
'tag': 'display_notification',
'params': {
'title': _('导入成功'),
'message': _('成功导入 %d 条记录') % len(records),
'sticky': False,
'type': 'success',
}
}
else:
raise UserError(_("没有找到有效数据"))
except Exception as e:
raise UserError(_("导入失败: %s") % str(e))
def _convert_value(self, value, field_name):
"""转换值为适合字段的格式
Args:
value: Excel中的值
field_name: 目标字段名
Returns:
转换后的值
"""
if value == '' or value is None:
return False
target_model = self.env[self.model_id.model]
field_info = target_model.fields_get([field_name])[field_name]
field_type = field_info['type']
# 根据字段类型转换值
if field_type == 'boolean':
if isinstance(value, bool):
return value
if isinstance(value, (int, float)):
return bool(value)
if isinstance(value, str):
return value.lower() in ('true', 'yes', 'y', '1')
return False
elif field_type == 'integer':
try:
return int(value)
except (ValueError, TypeError):
return 0
elif field_type == 'float':
try:
return float(value)
except (ValueError, TypeError):
return 0.0
elif field_type == 'date':
# 假设值已经是YYYY-MM-DD格式
return value
elif field_type == 'datetime':
# 假设值已经是YYYY-MM-DD HH:MM:SS格式
return value
elif field_type == 'many2one':
# 尝试通过名称查找记录
if not value:
return False
relation = field_info['relation']
RelatedModel = self.env[relation]
# 首先尝试精确匹配名称
record = RelatedModel.search([('name', '=', value)], limit=1)
if record:
return record.id
# 如果没有找到,尝试模糊匹配
record = RelatedModel.search([('name', 'ilike', value)], limit=1)
if record:
return record.id
# 如果是"名称/编码"格式,尝试分离并查找
if '/' in value:
name, code = value.split('/', 1)
record = RelatedModel.search([
'|',
('name', '=', name.strip()),
('code', '=', code.strip())
], limit=1)
if record:
return record.id
return False
# 对于其他类型,直接返回值
return value
class CustomExcelFieldMapping(models.TransientModel):
_name = 'custom.excel.field.mapping'
_description = 'Excel字段映射'
import_id = fields.Many2one('custom.excel.import', string='导入向导')
excel_header = fields.Char('Excel表头', required=True)
field_name = fields.Char('Odoo字段名')
field_string = fields.Char('字段标签', compute='_compute_field_string')
@api.depends('field_name', 'import_id.model_id')
def _compute_field_string(self):
"""计算字段的显示名称"""
for mapping in self:
if mapping.field_name and mapping.import_id.model_id:
model = self.env[mapping.import_id.model_id.model]
fields_info = model.fields_get([mapping.field_name])
if mapping.field_name in fields_info:
mapping.field_string = fields_info[mapping.field_name]['string']
else:
mapping.field_string = mapping.field_name
else:
mapping.field_string = ''
代码解析:
-
导入向导模型:
- 定义导入向导的基本字段(目标模型、文件、工作表设置等)
- 使用一对多关系管理字段映射
-
文件变更处理:
- 监听文件、模型等字段的变化
- 自动解析Excel表头
- 尝试自动匹配字段
- 生成初始字段映射
-
导入操作:
- 验证输入
- 解析Excel数据
- 根据字段映射转换数据
- 创建记录
- 返回导入结果
-
值转换:
- 根据目标字段类型转换值
- 处理布尔值、整数、浮点数、日期等
- 处理关系字段(通过名称、编码等查找记录)
-
字段映射模型:
- 存储Excel表头与Odoo字段的映射
- 计算字段显示名称
- 支持手动调整映射
数据导出到指定Excel模板实现
要实现将数据导出到预设的Excel模板,我们可以使用openpyxl库。以下是一个完整的实现:
class SaleOrderExport(models.TransientModel):
_name = 'sale.order.export.wizard'
_description = '销售订单导出向导'
order_ids = fields.Many2many('sale.order', string='销售订单')
template_id = fields.Many2one('ir.attachment', string='Excel模板',
domain=[('mimetype', 'in', ['application/vnd.ms-excel',
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'])])
def get_template_path(self):
"""获取模板文件的路径"""
self.ensure_one()
if not self.template_id:
# 使用默认模板
module_path = os.path.dirname(os.path.dirname(__file__))
template_path = os.path.join(module_path, 'static', 'templates', 'sale_order_template.xlsx')
if not os.path.exists(template_path):
raise UserError(_('默认模板文件未找到: %s') % template_path)
return template_path
else:
# 使用用户选择的模板
attachment = self.template_id
if not attachment.store_fname:
raise UserError(_('模板文件不存在'))
full_path = attachment._full_path(attachment.store_fname)
if not os.path.exists(full_path):
raise UserError(_('模板文件路径不存在: %s') % full_path)
return full_path
def load_workbook_from_template(self):
"""从模板加载工作簿"""
template_path = self.get_template_path()
try:
workbook = openpyxl.load_workbook(template_path)
return workbook
except Exception as e:
raise UserError(_('加载模板文件失败: %s') % str(e))
def get_export_data(self):
"""获取要导出的销售订单数据"""
self.ensure_one()
if not self.order_ids:
raise UserError(_('请先选择要导出的销售订单'))
export_data = []
for order in self.order_ids:
order_data = {
'name': order.name,
'partner_id': order.partner_id.name,
'date_order': order.date_order.strftime('%Y-%m-%d') if order.date_order else '',
'user_id': order.user_id.name,
'amount_total': order.amount_total,
'lines': []
}
for line in order.order_line:
order_data['lines'].append({
'product_id': line.product_id.display_name,
'name': line.name,
'product_uom_qty': line.product_uom_qty,
'price_unit': line.price_unit,
'price_subtotal': line.price_subtotal,
})
export_data.append(order_data)
return export_data
def fill_workbook_with_data(self, workbook, order_data):
"""将单个订单数据填充到工作簿中"""
# 假设我们为每个订单创建一个新的工作表,或者填充模板的第一个工作表
sheet = workbook.active # 或者 workbook['Order Details']
# 填充订单头信息
# 方法1:使用命名单元格(如果模板中已定义)
try:
# 尝试通过命名单元格填充
order_ref = workbook.defined_names['order_ref']
# 获取命名单元格的目标
dests = list(order_ref.destinations)
for title, coord in dests:
if title == sheet.title:
sheet[coord] = order_data['name']
# 同样方式填充其他命名单元格
customer_name = workbook.defined_names['customer_name']
dests = list(customer_name.destinations)
for title, coord in dests:
if title == sheet.title:
sheet[coord] = order_data['partner_id']
order_date = workbook.defined_names['order_date']
dests = list(order_date.destinations)
for title, coord in dests:
if title == sheet.title:
sheet[coord] = order_data['date_order']
salesperson = workbook.defined_names['salesperson']
dests = list(salesperson.destinations)
for title, coord in dests:
if title == sheet.title:
sheet[coord] = order_data['user_id']
except KeyError:
# 如果命名单元格不存在,则使用固定单元格地址
sheet['B2'] = order_data['name']
sheet['B3'] = order_data['partner_id']
sheet['E2'] = order_data['date_order']
sheet['E3'] = order_data['user_id']
# 填充订单行数据
# 确定起始行
start_row = 7 # 假设从第7行开始填充订单行
# 填充订单行
for i, line in enumerate(order_data['lines']):
row = start_row + i
sheet.cell(row=row, column=1).value = line['product_id']
sheet.cell(row=row, column=2).value = line['name']
sheet.cell(row=row, column=3).value = line['product_uom_qty']
sheet.cell(row=row, column=4).value = line['price_unit']
# 小计可以由Excel公式计算,也可以直接填入
sheet.cell(row=row, column=5).value = line['price_subtotal']
# 更新总计行
total_row = start_row + len(order_data['lines']) + 1
sheet.cell(row=total_row, column=4).value = "总计"
sheet.cell(row=total_row, column=5).value = order_data['amount_total']
return workbook
def action_export_to_template(self):
"""导出到Excel模板的主方法"""
self.ensure_one()
# 获取导出数据
export_data = self.get_export_data()
if not export_data:
raise UserError(_('没有找到要导出的数据'))
# 为每个订单创建一个Excel文件
result_files = []
for order_data in export_data:
# 加载模板
workbook = self.load_workbook_from_template()
# 填充数据
self.fill_workbook_with_data(workbook, order_data)
# 保存为临时文件
file_data = io.BytesIO()
workbook.save(file_data)
file_data.seek(0)
# 准备下载信息
filename = f"销售订单_{order_data['name']}.xlsx"
result_files.append({
'name': filename,
'data': base64.b64encode(file_data.read()).decode('utf-8'),
'mimetype': 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',
})
# 如果只有一个文件,直接返回下载
if len(result_files) == 1:
attachment = self.env['ir.attachment'].create({
'name': result_files[0]['name'],
'datas': result_files[0]['data'],
'mimetype': result_files[0]['mimetype'],
'res_model': self._name,
'res_id': self.id,
})
return {
'type': 'ir.actions.act_url',
'url': f"/web/content/{attachment.id}?download=true",
'target': 'self',
}
# 如果有多个文件,创建一个ZIP文件
if len(result_files) > 1:
zip_buffer = io.BytesIO()
with zipfile.ZipFile(zip_buffer, 'w') as zip_file:
for file_info in result_files:
zip_file.writestr(file_info['name'],
base64.b64decode(file_info['data']))
zip_buffer.seek(0)
zip_data = base64.b64encode(zip_buffer.read()).decode('utf-8')
attachment = self.env['ir.attachment'].create({
'name': f"销售订单导出_{fields.Date.today()}.zip",
'datas': zip_data,
'mimetype': 'application/zip',
'res_model': self._name,
'res_id': self.id,
})
return {
'type': 'ir.actions.act_url',
'url': f"/web/content/{attachment.id}?download=true",
'target': 'self',
}
代码解析:
-
导出向导模型:
- 定义导出向导的基本字段(订单、模板等)
- 支持选择自定义模板或使用默认模板
-
模板处理:
- 获取模板文件路径
- 加载Excel模板
- 处理模板不存在的情况
-
数据获取:
- 从选定的销售订单中提取数据
- 组织数据为便于填充的结构
- 包含订单头信息和订单行
-
数据填充:
- 支持通过命名单元格填充数据
- 支持通过固定单元格地址填充数据
- 处理订单行数据
- 更新总计信息
-
导出操作:
- 为每个订单创建一个Excel文件
- 支持多个订单导出为ZIP文件
- 创建附件并提供下载链接
常见问题与解决方案
导入时的常见错误
-
必填字段缺失:
# 在导入前验证必填字段 def _validate_required_fields(self, data, fields): required_fields = [f for f in fields if self.env[self.res_model]._fields[f].required] for row_index, row in enumerate(data): for field in required_fields: field_index = fields.index(field) if not row[field_index]: return { 'error': _("Missing required value for field '%s' at row %d") % (field, row_index + 1), 'row': row_index, 'field': field, } return None -
字段格式不正确:
# 在导入前验证字段格式 def _validate_field_format(self, value, field_type): if field_type == 'integer': try: int(value) except (ValueError, TypeError): return False elif field_type == 'float': try: float(value) except (ValueError, TypeError): return False elif field_type == 'date': try: datetime.datetime.strptime(value, '%Y-%m-%d') except (ValueError, TypeError): return False return True -
关联记录不存在:
# 在导入前验证关联记录 def _validate_relation_field(self, value, field_name): field = self.env[self.res_model]._fields[field_name] if field.type not in ('many2one', 'many2many'): return True relation = field.comodel_name RelatedModel = self.env[relation] # 尝试通过名称查找记录 record = RelatedModel.search([('name', '=', value)], limit=1) if not record: # 尝试通过外部ID查找 if '.' in value: record = self.env.ref(value, False) if not record or record._name != relation: return False return True
大数据量导入问题
-
分批处理:
def _batch_import(self, model, fields, data, batch_size=1000): """分批导入数据""" result = { 'ids': [], 'messages': [], } for i in range(0, len(data), batch_size): batch = data[i:i+batch_size] try: with self.env.cr.savepoint(): batch_result = model.load(fields, batch) result['ids'].extend(batch_result['ids']) result['messages'].extend(batch_result.get('messages', [])) except Exception as e: result['messages'].append({ 'type': 'error', 'message': str(e), 'records': len(batch), }) return result -
性能优化:
def _optimize_import(self, model, context=None): """优化导入性能""" context = context or {} # 禁用不必要的功能 context.update({ 'tracking_disable': True, # 禁用变更跟踪 'mail_notrack': True, # 禁用邮件跟踪 'defer_parent_store_computation': True, # 延迟父存储计算 'import_flush': False, # 延迟刷新 }) return model.with_context(**context)
最佳实践与技巧
导入最佳实践
-
使用事务和保存点:
def safe_import(self, model, fields, data): """安全导入数据""" try: with self.env.cr.savepoint(): result = model.load(fields, data) if any(msg['type'] == 'error' for msg in result.get('messages', [])): return False, result return True, result except Exception as e: return False, {'messages': [{'type': 'error', 'message': str(e)}]} -
预处理数据:
def preprocess_data(self, data, fields): """预处理导入数据""" processed_data = [] for row in data: processed_row = [] for i, field in enumerate(fields): value = row[i] # 处理空值 if value == '': processed_row.append(False) continue # 处理特殊字段 field_obj = self.env[self.res_model]._fields.get(field) if field_obj and field_obj.type == 'date' and value: # 标准化日期格式 try: date_obj = datetime.datetime.strptime(value, '%d/%m/%Y') value = date_obj.strftime('%Y-%m-%d') except ValueError: pass processed_row.append(value) processed_data.append(processed_row) return processed_data
导出最佳实践
-
使用命名单元格:
def create_template_with_named_cells(self): """创建带有命名单元格的模板""" wb = openpyxl.Workbook() ws = wb.active ws.title = "Order Details" # 添加标题和表头 ws['A1'] = "销售订单导出" ws['A2'] = "订单号:" ws['A3'] = "客户:" ws['D2'] = "日期:" ws['D3'] = "销售员:" # 定义命名单元格 wb.defined_names.add('order_ref', 'Order Details!B2') wb.defined_names.add('customer_name', 'Order Details!B3') wb.defined_names.add('order_date', 'Order Details!E2') wb.defined_names.add('salesperson', 'Order Details!E3') # 添加表头 headers = ["产品", "描述", "数量", "单价", "小计"] for i, header in enumerate(headers, 1): ws.cell(row=6, column=i).value = header # 保存模板 template_path = os.path.join(os.path.dirname(__file__), 'static', 'templates', 'sale_order_template.xlsx') wb.save(template_path) return template_path -
处理大数据量导出:
def export_large_dataset(self, model, domain, fields, filename): """导出大数据集""" # 创建工作簿 wb = openpyxl.Workbook() ws = wb.active # 添加表头 for i, field in enumerate(fields, 1): field_obj = model._fields[field] ws.cell(row=1, column=i).value = field_obj.string # 分批查询和导出数据 batch_size = 1000 offset = 0 row = 2 while True: records = model.search(domain, limit=batch_size, offset=offset) if not records: break for record in records: for i, field in enumerate(fields, 1): value = record[field] # 处理特殊类型 if isinstance(value, models.BaseModel): value = value.display_name ws.cell(row=row, column=i).value = value row += 1 offset += batch_size # 保存文件 file_data = io.BytesIO() wb.save(file_data) file_data.seek(0) # 创建附件 attachment = self.env['ir.attachment'].create({ 'name': filename, 'datas': base64.b64encode(file_data.read()), 'mimetype': 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet', }) return attachment


 浙公网安备 33010602011771号
浙公网安备 33010602011771号