



第八周作业
1.1 redis 哨兵介绍
哨兵,英文名 Sentinel,是一个分布式系统,用于对主从结构中的每一台服务器进行监控,当主节点出现故障后通过投票机制来挑选新的主节点,并且将所有的从节点连接到新的主节点上。
哨兵的三个作用:
监控:监控谁?支持主从结构的工作一个是主节点一个是从节点,那肯定就是监控这俩个了。监控主节点和从节点是否正常运行;检测主节点是否存活,主节点和从节点运行情况。
通知:哨兵检测的服务器出现问题时,会向其他的哨兵发送通知,哨兵之间就相当于一个微信群,每个哨兵发现的问题都会发在这个群里。
自动转移故障:当检测到主节点宕机后,断开与宕机主节点连接的所有从节点,在从节点中选取一个作为主节点,然后将其他的从节点连接到这个最新主节点的上。并且告知客户端最新的服务器地址。这里有一个注意点,哨兵也是一台 Redis 服务器,只是不对外提供任何服务。配置哨兵时配置为单数。
1.2 哨兵架构实现
1.2.1 哨兵需要先实现主从复制
三台设备,主10.0.0.139,从10.0.0.136/137
redis主节点无需配置,redis部署好后都认为自己是主节点
slave1从节点配置,下面此项配置重启后将会丢失主从,所以需要进入主配置文件修改


slave2从节点配置同上


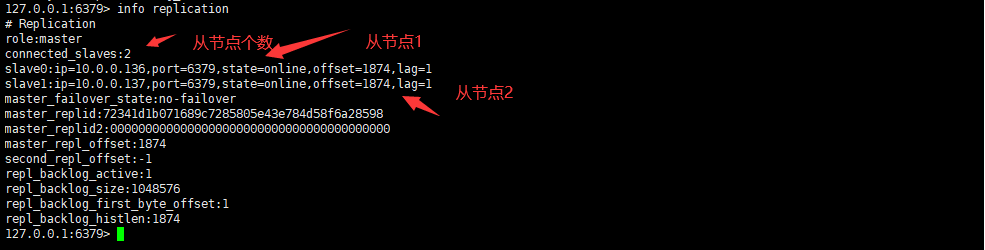
从主节点查看状态
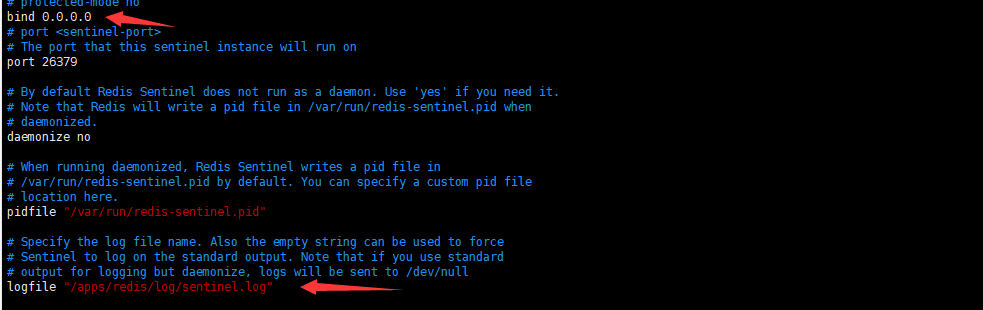
1.2.2哨兵配置
#如果是编译安装,在源码目录有sentinel.conf,复制到安装目录即可,主节点,slave1、2节点同样配置

修改属性,主节点,slave1、2同样配置

vim /apps/redis/etc/sentinel.conf编辑修改,主节点,slave1、2节点同样配置
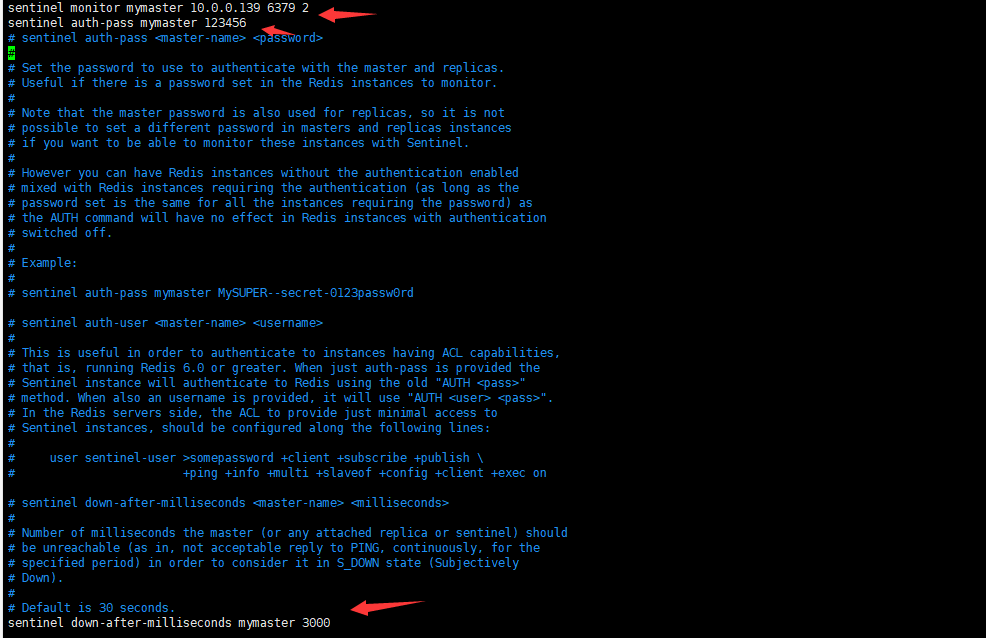
/apps/redis/bin/redis-sentinel /apps/redis/etc/sentinel.conf启动哨兵,主节点,slave1、2节点生成不同myid
主节点

slave1

slave2

#如果是编译安装,可以在所有节点生成新的service文件
vim /lib/systemd/system/redis-sentinel.service编辑,主节点,slave1、2节点同样配置
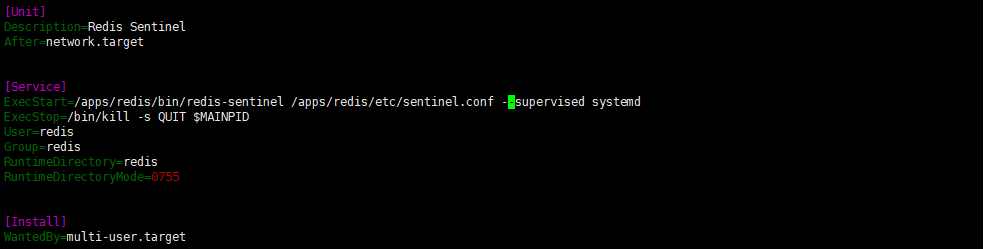
#注意所有节点的目录权限,否则无法启动服务
chown -R redis.redis /apps/redis/
哨兵服务器端口状态

当前sentinel状态

1.2.3 停止Master 实现故障转移

故障转移时sentinel的信息

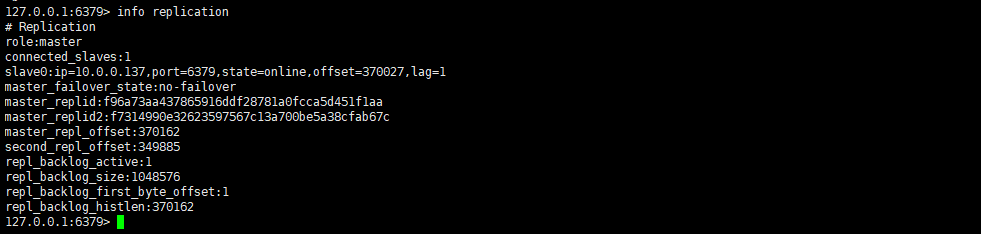
在10.0.0.137从节点上看,主已经变为10.0.0.136
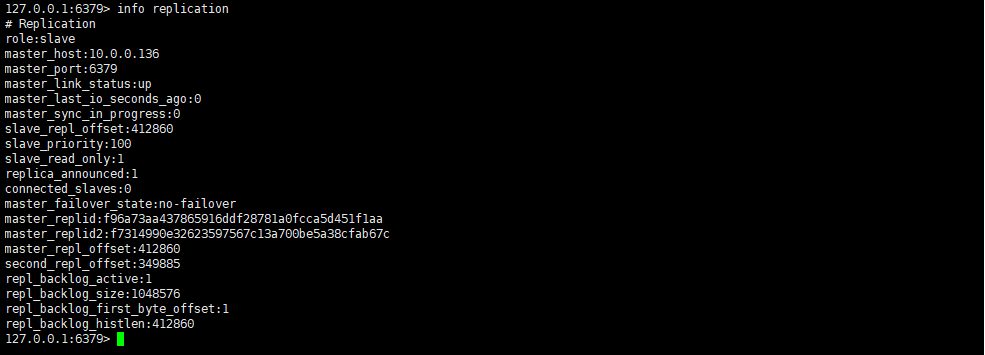
在新主上写一条数据,并在从上看是否同步成功



原来的主启动后变为从
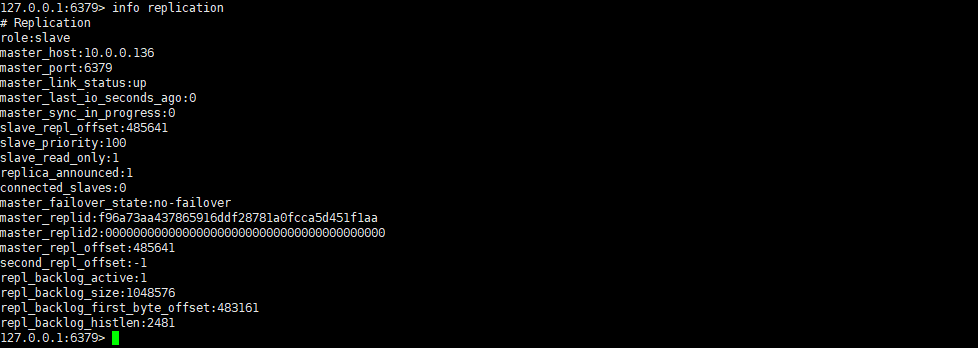
新主
1.3 集群
1.3.1 Redis Cluster 介绍
使用哨兵sentinel 只能解决Redis高可用问题,实现Redis的自动故障转移,但仍然无法解决Redis Master 单节点的性能瓶颈问题 为了解决单机性能的瓶颈,提高Redis 服务整体性能,可以使用分布式集群的解决方案 早期 Redis 分布式集群部署方案: 客户端分区:由客户端程序自己实现写入分配、高可用管理和故障转移等,对客户端的开发实现较为 复杂 代理服务:客户端不直接连接Redis,而先连接到代理服务,由代理服务实现相应读写分配,当前代 理服务都是第三方实现.此方案中客户端实现无需特殊开发,实现容易,但是代理服务节点仍存有单点 故障和性能瓶颈问题。比如:豌豆荚开发的 codis Redis 3.0 版本之后推出无中心架构的 Redis Cluster ,支持多个master节点并行写入和故障的自动转移 动能
1.3.2 Redis cluster 架构
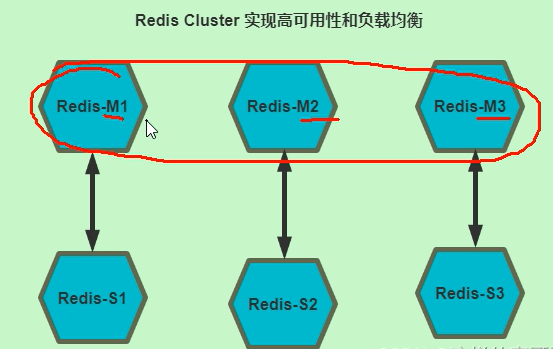
Redis cluster 需要至少 3个master节点才能实现,slave节点数量不限,当然一般每个master都至少对应的 有一个slave节点 如果有三个主节点采用哈希槽 hash slot 的方式来分配16384个槽位 slot 此三个节点分别承担的slot 区间可以是如以下方式分配 节点M1 0-5460 节点M2 5461-10922 节点M3 10923-16383
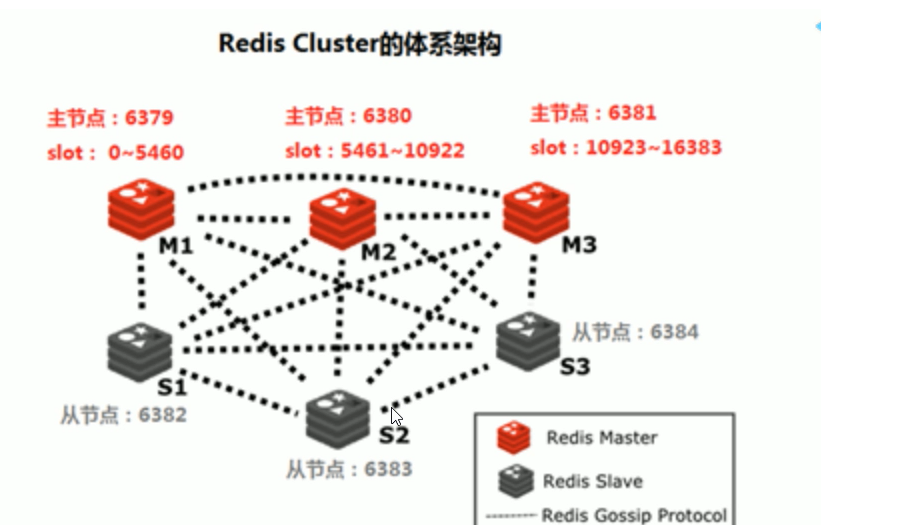
1.3.3 集群扩容
当有新的节点准备好加入集群时,这个新的节点还是孤立节点,加入有两种方式。一个是通过集群节点 执行命令来和孤立节点握手,另一个则是使用脚本来添加节点。
cluster_node_ip:port: cluster meet ip port new_node_ip:port redis-trib.rb add-node new_node_ip:port cluster_node_ip:port 通常这个新的节点有两种身份,要么作为主节点,要么作为从节点: 主节点:分摊槽和数据 从节点:作故障转移备份
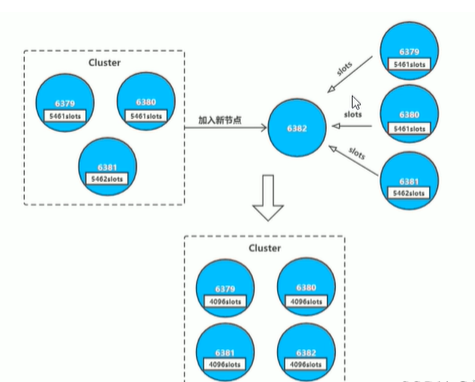
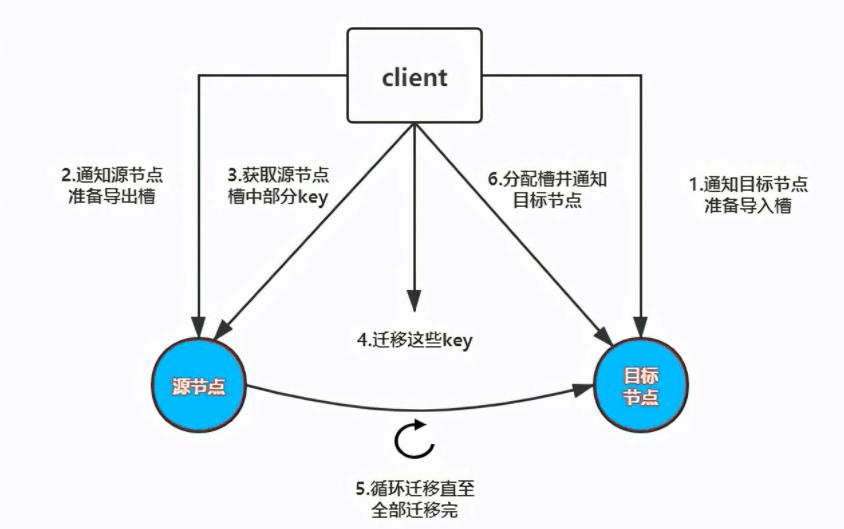
其中槽的迁移有以下步骤
1.3.4 集群缩容
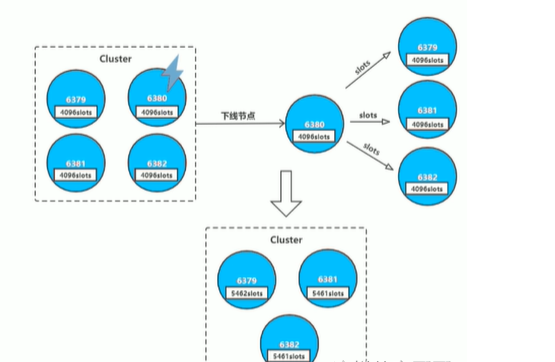
下线节点的流程如下:
-
判断该节点是否持有槽,如果未持有槽就跳转到下一步,持有槽则先迁移槽到其他节点
-
通知其他节点(cluster forget)忘记该下线节点
-
关闭下线节点的服务 需要注意的是如果先下线主节点,再下线从节点,会进行故障转移,所以要先下线从节点。
1.3.5 集群配置
六台设备
10.0.0.128
10.0.0.131
10.0.0.139
10.0.0.135
10.0.0.136
10.0.0.137
#使用编译安装,可以用如下一条sed命令修改下列6项redis配置文件以实现cluster功能
sed -i.bak -e '/masterauth/a masterauth 123456' -e '/# cluster-enabled yes/a cluster-enabled yes' -e '/# cluster-config-filenodes-6379.conf/a cluster-config-file nodes-6379.conf' -e '/cluster-require-full-coverage yes/c cluster-require-full-coverage no' /apps/redis/etc/redis.conf
每台设备都是同样的状态
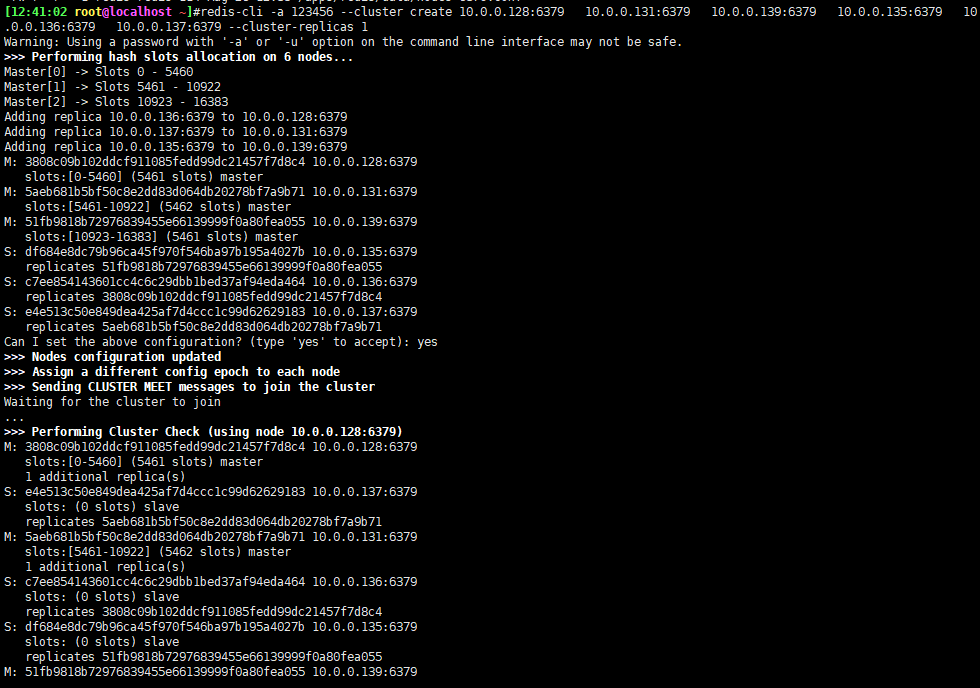
#使用编译安装,可以使用如下一条命令来确定主从redis-cli -a 123456 --cluster create 192.168.72.142:6379 192.168.72.151:6379 192.168.72.155:6379 192.168.72.152:6379 192.168.72.153:6379 192.168.72.150:6379 --cluster-replicas 1
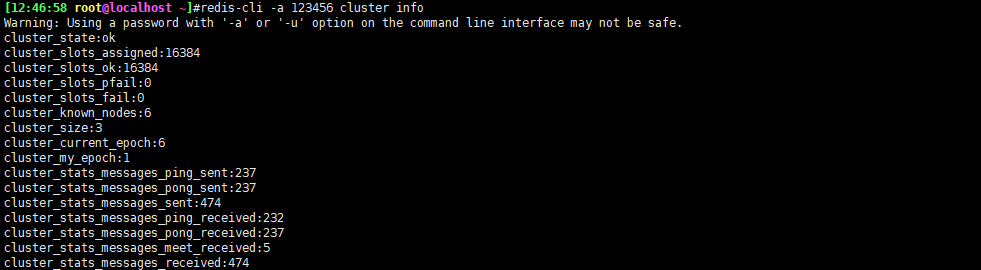
查看cluster集群主从节点关系的命令

1.4 集群扩容
新加两台主机
10.0.0.141
10.0.0.132
两台主机都使用编译安装
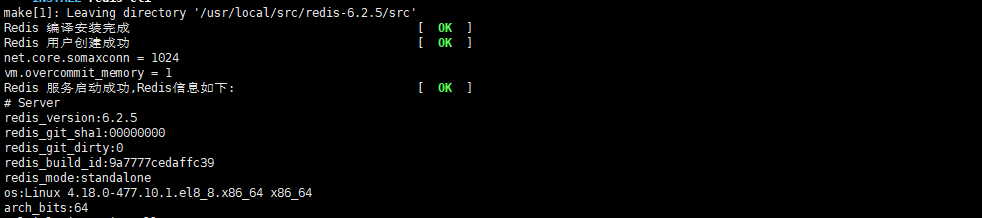

由于是编译安装,使用如下命令快速添加集群
sed -i.bak -e '/masterauth/a masterauth 123456' -e'/# cluster-enabled yes/a cluster-enabled yes' -e '/# cluster-config-file nodes-6379.conf/a cluster-config-file nodes-6379.conf' -e '/cluster-requirefull-coverage yes/c cluster-require-full-coverage no' /apps/redis/etc/redis.conf
重启主机
systemctl restart redis
添加新的master节点到集群
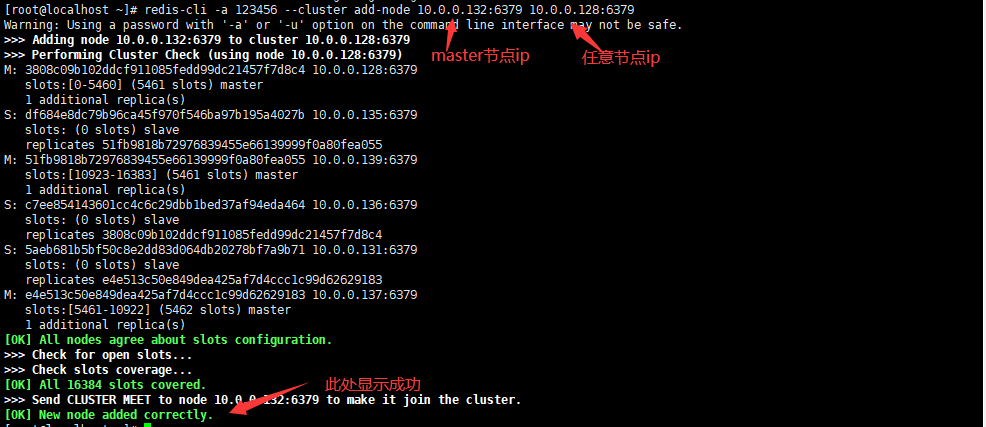
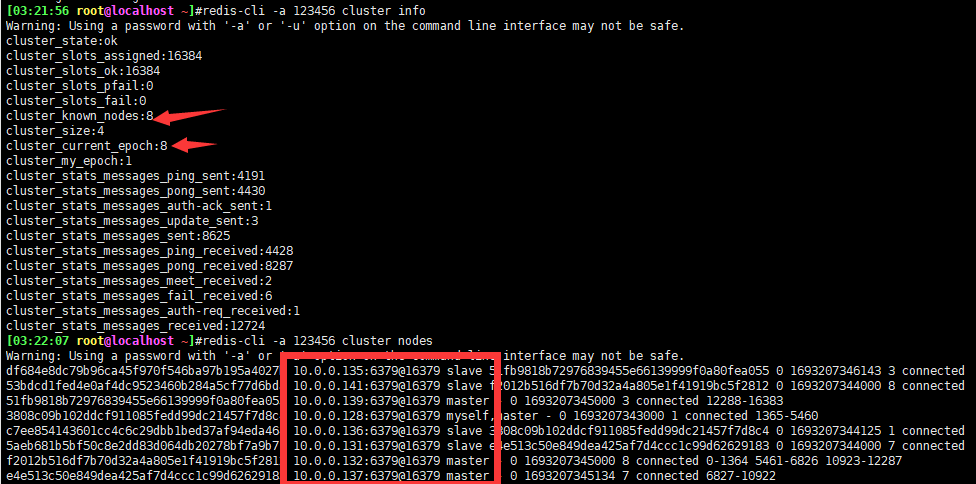
在新的master节点上重新分配槽位
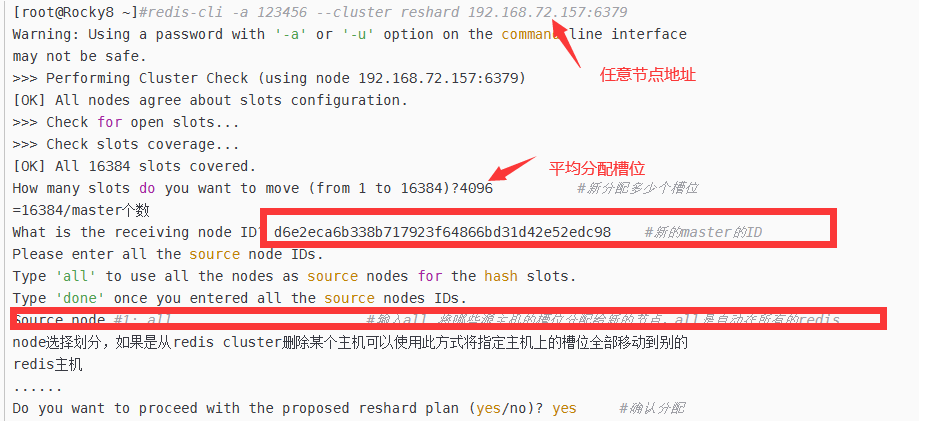

槽位信息

为新的master指定新的lave节点
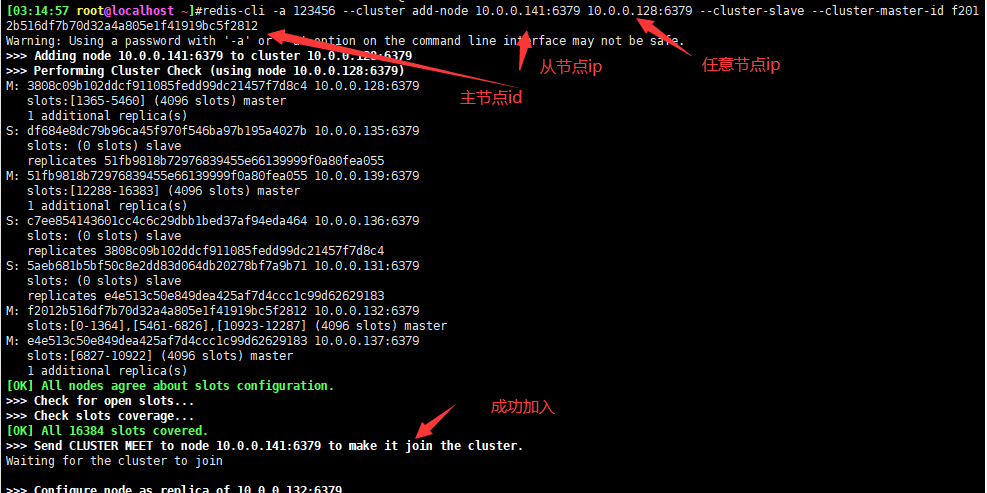
1.5集群缩容
缩容主机
10.0.0.141
10.0.0.132
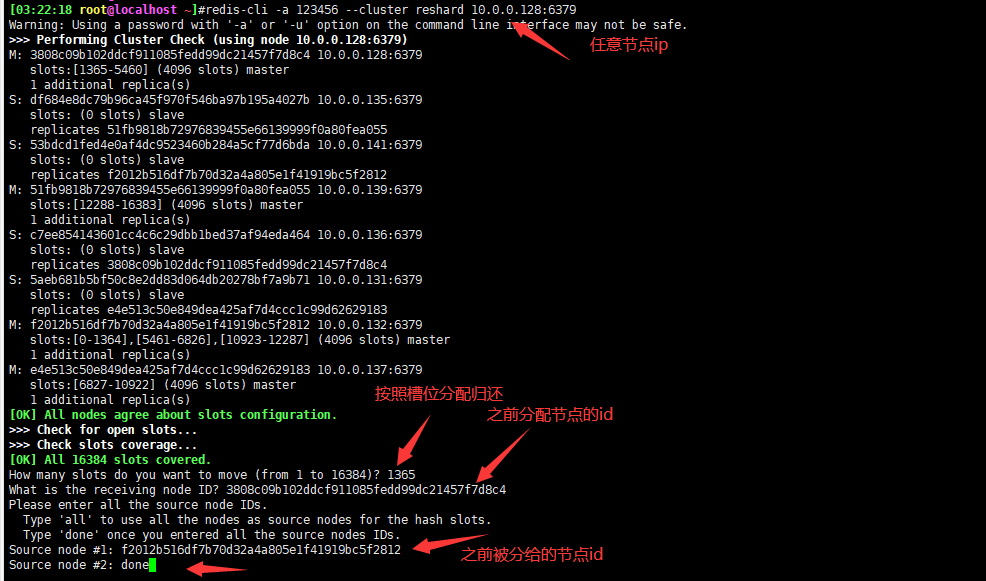
对比之前,已经一走了一部分槽位,按照如上情况,再移两次

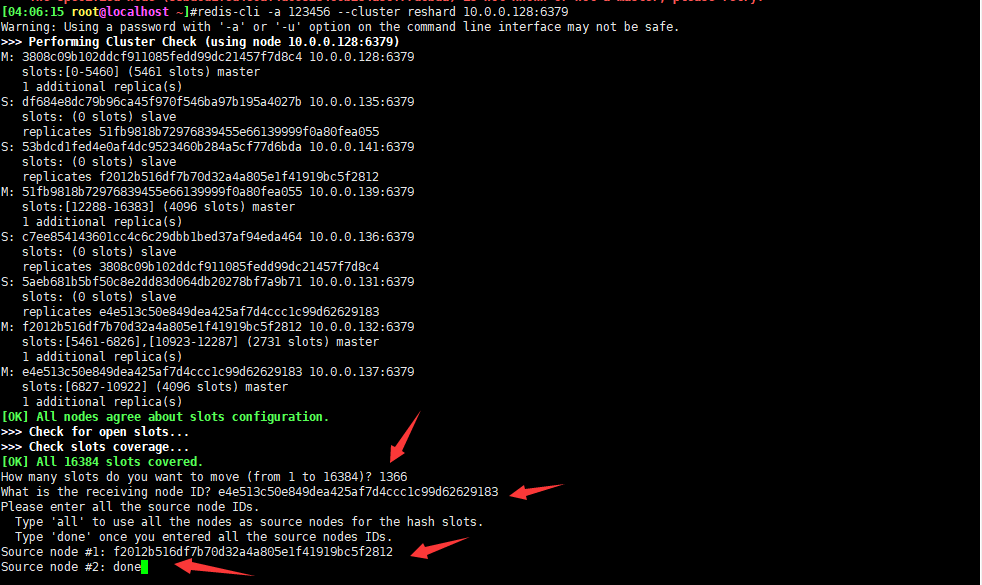
还剩最后一部分
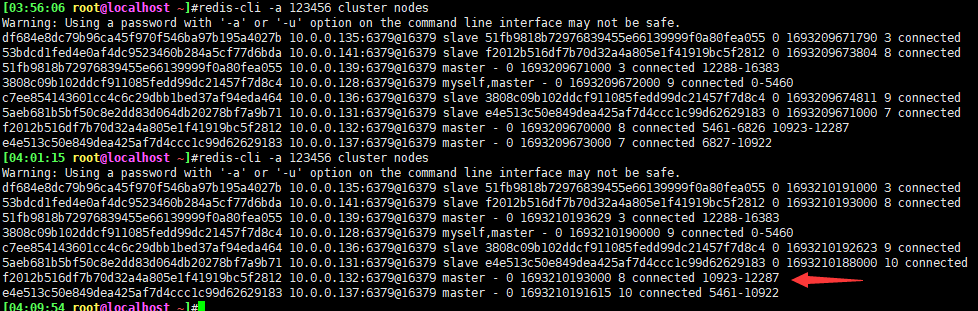
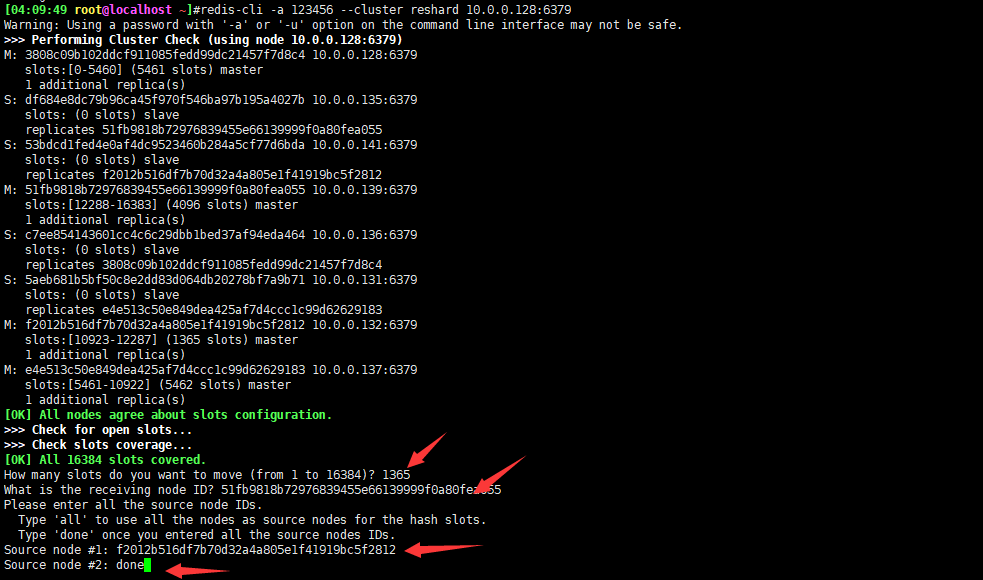
此时槽位已全部移除归还

从集群中删除主机

之前八个节点,删除两个后,只剩六个节点

二、LVS常用模型工作原理,及实现
2.1 LVS工作原理
LVS根据请求报文的目标IP和目标协议及端口将其调度转发至某RS,根据调度算法来挑选RS。LVS是内核 级功能,工作在INPUT链的位置,将发往INPUT的流量进行“处理”
2.2 LVS集群类型中的术语
VS:Virtual Server,Director Server(DS), Dispatcher(调度器),Load Balancer RS:Real Server(lvs), upstream server(nginx), backend server(haproxy) CIP:Client IP VIP:Virtual serve IP VS外网的IP DIP:Director IP VS内网的IP RIP:Real server IP 访问流程:CIP <–> VIP == DIP <–> RIP
2.3 LVS集群的工作模式
2.3.1 LVS的NAT模式
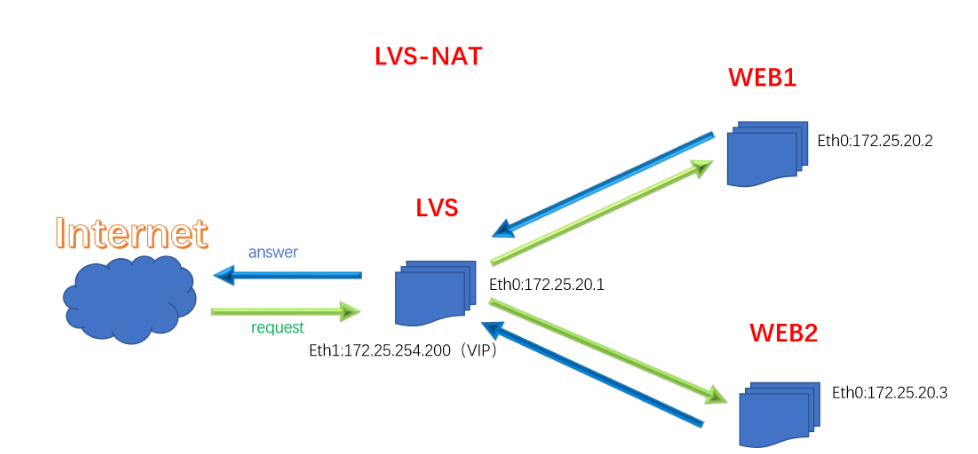
原理:把客户端发来的数据包在负载均衡器上将目的地址封装成其中一台RS的IP地址,并发至该RS来处理,RS处理完成后把数据包发给负载均衡器,负载均衡器再把数据包的原IP地址封装成为自己的IP,将目的地址封装成客户端IP地址,然后发给客户端。无论是进来的流量,还是出去的流量,都必须经过负载均衡器。
-
优点:集群中的物理服务器可以使用任何支持 TCP/IP 的操作系统,只有负载均衡器需要一个合法的IP地址。
-
缺点:扩展性有限。当服务器节点(普通PC服务器)增长过多时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包的流向都经过负载均衡器。当服务器节点过多时,大量的数据包都交汇在负载均衡器那,速度就会变慢!
2.3.2 LVS的DR模式
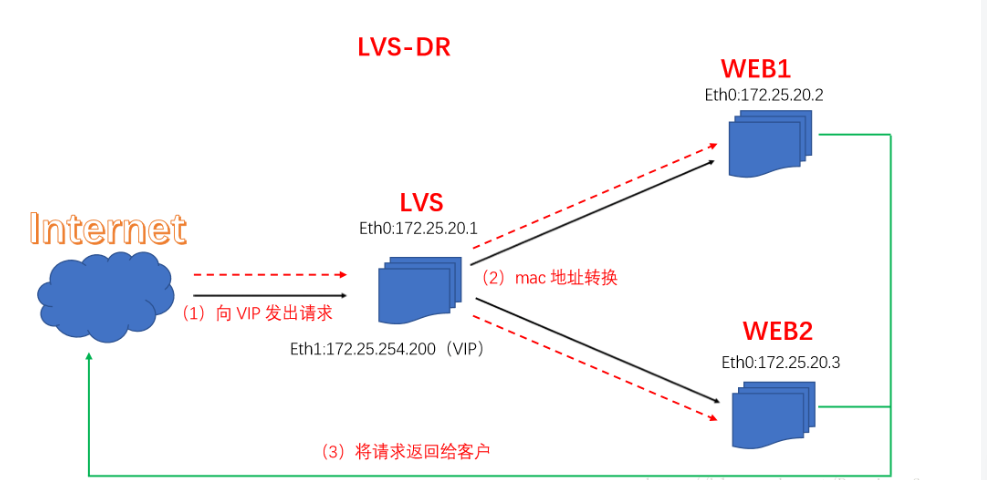
原理:负载均衡器和RS都使用同一个IP对外服务。但只有DR对ARP请求进行响应,所有RS对本身这个IP的ARP请求保持静默。也就是说,网关会把对这个服务IP的请求全部定向给DR,而DR收到数据包后根据调度算法,找出对应的RS,把目的MAC地址改为RS的MAC(因为IP一致)并将请求分发给这台RS。这时RS收到这个数据包,处理完成之后,由于IP一致,可以直接将数据返给客户,则等于直接从客户端收到这个数据包无异,处理后直接返回给客户端。由于负载均衡器要对二层包头进行改换,所以负载均衡器和RS之间必须在一个广播域,也可以简单的理解为在同一台交换机上。
-
优点:和TUN(隧道模式)一样,负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端。与VS-TUN相比,VS-DR这种实现方式不需要隧道结构,因此可以使用大多数操作系统做为物理服务器。
-
不足:要求负载均衡器的网卡必须与物理网卡在一个物理段上
2.3.3 LVS的TUN模式
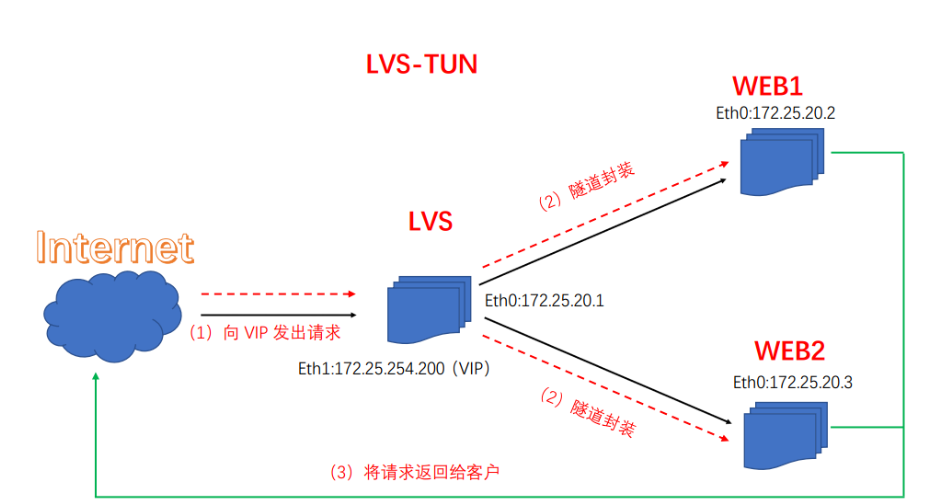
原理:由于互联网上的大多Internet服务的请求包很短小,而应答包通常很庞大,使用nat模式庞大的应答数据包也必须经过负载均衡器,这就加重了负载均衡器的负担,隧道模式就是优化这个问题的。所以隧道模式就是,把客户端发来的数据包,封装一个新的IP头标记(仅目的IP)发给RS,RS收到后,先把数据包的头解开,还原数据包,处理后,直接返回给客户端,不需要再经过负载均衡器。注意,由于RS需要对负载均衡器发过来的数据包进行还原,所以说必须支持IPTUNNEL协议。所以,在RS的内核中,必须编译支持IPTUNNEL这个选项
优点:负载均衡器只负责将请求包分发给后端节点服务器,而RS将应答包直接发给用户。所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,就能处理很巨大的请求量,这种方式,一台负载均衡器能够为很多RS进行分发。而且跑在公网上就能进行不同地域的分发。
缺点:隧道模式的RS节点需要合法IP,这种方式需要所有的服务器支持”IP Tunneling”(IP Encapsulation)协议,服务器可能只局限在部分Linux系统上。
2.3.4 LVS的FULLNAT模式
原理:FULL NAT 在client请求VIP 时,不仅替换了package 的dst ip,还替换了package的 src ip;但VIP 返回给client时也替换了src ip,具体分析如下: 首先client 发送请求[package] 给VIP;VIP 收到package后,会根据LVS设置的LB算法选择一个合适的realserver,然后把package 的DST IP 修改为realserver;把sorce ip 改成 lvs 集群的LB IP ;realserver 收到这个package后判断dst ip 是自己,就处理这个package ,处理完后把这个包发送给LVS VIP;LVS 收到这个package 后把sorce ip改成VIP的IP,dst ip改成 client ip然后发送给client。 FULL NAT 模式也不需要 LBIP 和realserver ip 在同一个网段;
-
full nat 跟nat 相比的优点是:保证RS回包一定能够回到LVS;因为源地址就是LVS–> 不确定
-
full nat 因为要更新sorce ip 所以性能正常比nat 模式下降 10%
三、LVS的负载策略有哪些,各应用在什么场景,通过LVS DR任意实现1-2种场景
3.1 LVS调度算法
ipvs scheduler:根据其调度时是否考虑各RS当前的负载状态 分为两种:静态方法和动态方法
3.1.1 静态方法
仅根据算法本身进行调度 1、RR:roundrobin,轮询,较常用,雨露均沾,大锅饭 2、WRR:Weighted RR,加权轮询,较常用 3、SH:Source Hashing,实现session sticky,源IP地址hash;将来自于同一个IP地址的请求始终发往第一次挑中的RS,从而实现会话绑定(局域网SAT公网地址,收到报文都是一个地址都往一个地方调度) 4、DH:Destination Hashing;目标地址哈希,第一次轮询调度至RS,后续将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡,如: Web缓存
3.1.2 动态方法
主要根据每RS当前的负载状态及调度算法进行调度Overhead=value 较小的RS将被调度 1、LC:least connections 适用于长连接应用 Overhead=activeconns256+inactiveconns 2、WLC:Weighted LC,默认调度方法,较常用 Overhead=(activeconns256+inactiveconns)/weight 3、SED:Shortest Expection Delay,初始连接高权重优先,只检查活动连接,而不考虑非活动连接 Overhead=(activeconns+1)*256/weight 4、NQ:Never Queue,第一轮均匀分配,后续SED 5、LBLC:Locality-Based LC,动态的DH算法,使用场景:根据负载状态实现正向代理,实现Web Cache等 6、LBLCR:LBLC with Replication,带复制功能的LBLC,解决LBLC负载不均衡问题,从负载重的复制 到负载轻的RS,实现Web Cache等
3.1.3 内核版本 4.15 版本后新增调度算法:FO和OVF
FO(Weighted Fail Over)调度算法,在此FO算法中,遍历虚拟服务所关联的真实服务器链表,找到还未 过载(未设置IP_VS_DEST_F_OVERLOAD标志)的且权重最高的真实服务器,进行调度,属于静态算法 OVF(Overflow-connection)调度算法,基于真实服务器的活动连接数量和权重值实现。将新连接调度到权重值最高的真实服务器,直到其活动连接数量超过权重值,之后调度到下一个权重值最高的真实服 务器,在此OVF算法中,遍历虚拟服务相关联的真实服务器链表,找到权重值最高的可用真实服务器。,属于动态算法 一个可用的真实服务器需要同时满足以下条件:
未过载(未设置IP_VS_DEST_F_OVERLOAD标志) 真实服务器当前的活动连接数量小于其权重值 其权重值不为零
3.2 LVS-DR模式单网段案例
环境:五台主机
一台:客户端
仅主机:192.168.10.6/24
一台:router
nat:10.0.0.10/24
仅主机:192.168.10.200/24
一台:lvs
nat:10.0.0.135
两台rs
rs1:nat:10.0.0.136/24
rs2:nat:10.0.0.139/24
修改rs1、2网关,改为router ip地址


重启网卡生效


lvs网关也指像router


router配置仅主机网卡地址
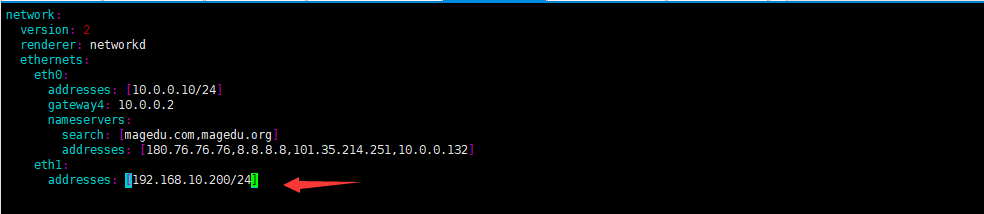
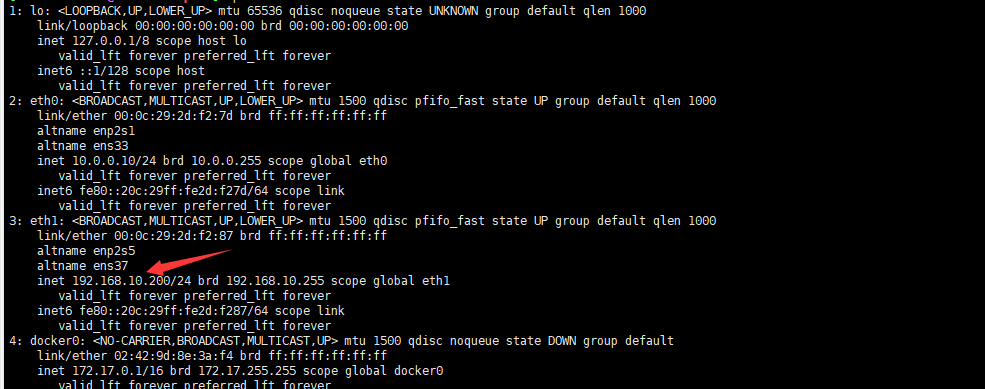
测试rs1、2网页访问


router开启ip_forward功能

修改互联网主机地址

rs1、2的ipvs配置


vip(虚拟ip)绑定回环网卡,rs1、2、lvs需三个绑定

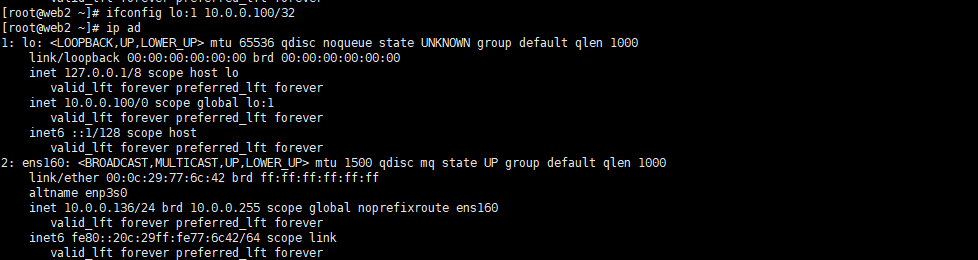

在lvs主机上加规则

测试

四、web http协议通信过程,相关技术术语总结
4.1 web http协议通信过程
1 DNS 2 CDN 3 TCP 4 Web服务器处理 1)建立连接 2)接收清求 3)处理请求 GET、POST等方法 4)获取资源 5)构建响应报文 6)发送响应 7)记录日志 5 浏览器接收响应报文,进行页面渲染
4.2 cookie和session比较
cookie和session的相同和不同: cookie通常是在服务器生成,但也可以在客户端生成,session是在服务器端生成的 session 将数据信息保存在服务器端,可以是内存,文件,数据库等多种形式,cookie 将数据保存在客户端的内存或文件中 单个cookie保存的数据不能超过4K,每个站点cookie个数有限制,比如IE8为50个、Firefox为50个、Opera为30个;session存储在服务器,没有容量限制 cookie存放在用户本地,可以被轻松访问和修改,安全性不高;session存储于服务器,比较安全cookie有会话cookie和持久cookie,生命周期为浏览器会话期的会话cookie保存在缓存,关闭浏览器窗口就消失,持久cookie被保存在硬盘,知道超过设定的过期时间;随着服务端session存储压力增大,会根据需要定期清理session数据 session中有众多数据,只将sessionID这一项可以通过cookie发送至客户端进行保留,客户端下次访问时,在请求报文中的cookie会自动携带sessionID,从而和服务器上的的session进行关联 cookie缺点: 1、使用cookie来传递信息,随着cookie个数的增多和访问量的增加,它占用的网络带宽也很大,试想假如cookie占用200字节,如果一天的PV有几个亿,那么它要占用多少带宽? 2、cookie并不安全,因为cookie是存放在客户端的,所以这些cookie可以被访问到,设置可以通过插件添加、修改cookie。所以从这个角度来说,我们要使用sesssion,session是将数据保存在服务端的,只是通过cookie传递一个sessionId而已,所以session更适合存储用户隐私和重要的数据 session 缺点: 1、不容易在多台服务器之间共享,可以使用session绑定,session复制,session共享解决 2、session存放在服务器中,所以session如果太多会非常消耗服务器的性能 cookie和session各有优缺点,在大型互联网系统中,单独使用cookie和session都是不可行的
4.3 HTTP1.0和HTTP1.1的区别
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-NoneMatch等更多可供选择的缓存头来控制缓存策略 带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如:客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),方便了开发者自由的选择以便于充分利用带宽和连接 错误通知的管理,在HTTP1.1中新增24个状态响应码,如409(Conflict)表示请求的资源与资源当前状态冲突;410(Gone)表示服务器上的某个资源被永久性的删除 Host 头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应 消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request) 长连接,HTTP 1.1支持持久连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,弥补了HTTP1.0每次请求都要创建连接的缺点
HTTP1.0和1.1的问题
HTTP1.x在传输数据时,每次都需要重新建立连接,无疑增加了大量的延迟时间,特别是在移动端更为突出
HTTP1.x在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,无法保证数据的安全性
HTTP1.x在使用时,header里携带的内容过大,增加了传输的成本,并且每次请求header基本不怎么变化,尤其在移动端增加用户流量
虽然HTTP1.x支持了keep-alive,来弥补多次创建连接产生的延迟,但是keep-alive使用多了同样会给服务端带来大量的性能压力,并且对于单个文件被不断请求的服务(例如图片存放网站),keepalive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间
HTTPS协议:
五、总结网络IO模型和nginx架构
5.1 网络IO模型
5.1.1 模型相关概念
同步/异步:关注的是消息通信机制,即调用者在等待一件事情的处理结果时,被调用者是否提供完成状态的通知。
同步:synchronous,被调用者并不提供事件的处理结果相关的通知消息,需要调用者主动询问事情是否处理完成 (经理给员工安排活案例,老式洗衣机案例)
异步:asynchronous,被调用者通过状态、通知或回调机制主动通知调用者被调用者的运行状态阻塞/非阻塞:关注调用者在等待结果返回之前所处的状态 (新式洗衣机会提醒)
阻塞:blocking,指IO操作需要彻底完成后才返回到用户空间,调用结果返回之前,调用者被挂起,干不了别的事情。(坐着等洗衣机洗好衣服)
非阻塞:nonblocking,指IO操作被调用后立即返回给用户一个状态值,而无需等到IO操作彻底完成,在最终的调用结果返回之前,调用者不会被挂起,可以去做别的事情。(洗衣服的时候可以干别的事情) 最好的组合就是异步加非阻塞(洗衣机洗衣服的同时还能干别的事情,洗好了还会通知我)
5.1.2 网络 I/O 模型
阻塞型、非阻塞型、复用型、信号驱动型、异步
5.1.2.1 阻塞型 I/O 模型(blocking IO)
阻塞IO模型是最简单的I/O模型,用户线程在内核进行IO操作时被阻塞 用户线程通过系统调用read发起I/O读操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接收的数据拷贝到用户空间,完成read操作 用户需要等待read将数据读取到buffer后,才继续处理接收的数据。整个I/O请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够 优点:程序简单,在阻塞等待数据期间进程/线程挂起,基本不会占用 CPU 资源 缺点:每个连接需要独立的进程/线程单独处理,当并发请求量大时为了维护程序,内存、线程切换开销较大,apache 的prefork使用的是这种模式。
5.1.2.2 非阻塞型 I/O 模型 (nonblocking IO)
用户线程发起IO请求时立即返回。但并未读取到任何数据,用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。即 “轮询”机制存在两个问题:如果有大量文件描述符都要等,那么就得一个一个的read。这会带来大量的Context Switch(read是系统调用,每调用一次就得在用户态和核心态切换一次)。轮询的时间不好把握。这里是要猜多久之后数据才能到。等待时间设的太长,程序响应延迟就过大;设的太短,就会造成过于频繁的重试,干耗CPU而已,是比较浪费CPU的方式,一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
5.1.2.3 多路复用型 (I/O multiplexing)
多路复用IO指一个线程可以同时(实际是交替实现,即并发完成)监控和处理多个文件描述符对应各自的IO,即复用同一个线程 一个线程之所以能实现同时处理多个IO,是因为这个线程调用了内核中的SELECT,POLL或EPOLL等系统调用,从而实现多路复用IO
1、select(轮训–IO数量越多速度越慢) 2、epoll(IO完成内核立刻主动发生主动地通报) I/O multiplexing 主要包括:select,poll,epoll三种系统调用,select/poll/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。 它的基本原理就是select/poll/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。 当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。 Apache prefork是此模式的select,worker是poll模式。
5.1.2.4 信号驱动式 I/O 模型 (signal-driven IO)
信号驱动I/O的意思就是进程现在不用傻等着,也不用去轮询。而是让内核在数据就绪时,发送信号通知进程。 调用的步骤是,通过系统调用 sigaction ,并注册一个信号处理的回调函数,该调用会立即返回,然后主程序可以继续向下执行,当有I/O操作准备就绪,即内核数据就绪时,内核会为该进程产生一个 SIGIO信号,并回调注册的信号回调函数,这样就可以在信号回调函数中系统调用 recvfrom 获取数据,将用户进程所需要的数据从内核空间拷贝到用户空间 此模型的优势在于等待数据报到达期间进程不被阻塞。用户主程序可以继续执行,只要等待来自信号处理函数的通知。 在信号驱动式 I/O 模型中,应用程序使用套接口进行信号驱动 I/O,并安装一个信号处理函数,进程继续运行并不阻塞 当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 I/O 操作函数处理数据。优点:线程并没有在等待数据时被阻塞,内核直接返回调用接收信号,不影响进程继续处理其他请求因此可以提高资源的利用率 缺点:信号 I/O 在大量 IO 操作时可能会因为信号队列溢出导致没法通知
5.1.2.5 异步 I/O 模型 (asynchronous IO)
Linux提供了AIO库函数实现异步,但是用的很少。目前有很多开源的异步IO库,例如libevent、libev、libuv。
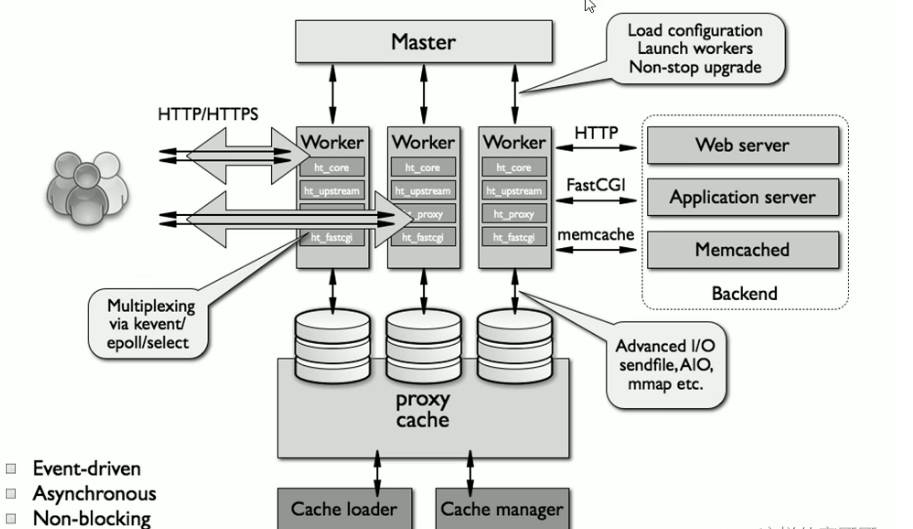
5.2 nginx架构
5.2.1 Nginx 进程结构
web请求处理机制 多进程方式:服务器每接收到一个客户端请求就有服务器的主进程生成一个子进程响应客户端,直到用户关闭连接,这样的优势是处理速度快,子进程之间相互独立,但是如果访问过大会导致服务器资源耗尽而无法提供请求。 多线程方式:与多进程方式类似,但是每收到一个客户端请求会有服务进程派生出一个线程和此客户端进行交互,一个线程的开销远远小于一个进程,因此多线程方式在很大程度减轻了web服务器对系统资源的要求,但是多线程也有自己的缺点,即当多个线程位于同一个进程内工作的时候,可以相互访问同样的内存地址空间,所以他们相互影响,一旦主进程挂掉则所有子线程都不能工作了,IIS服务器使用了多线程的方式,需要间隔一段时间就重启一次才能稳定。Nginx是多进程组织模型,而且是一个由Master主进程和Worker工作进程组成。
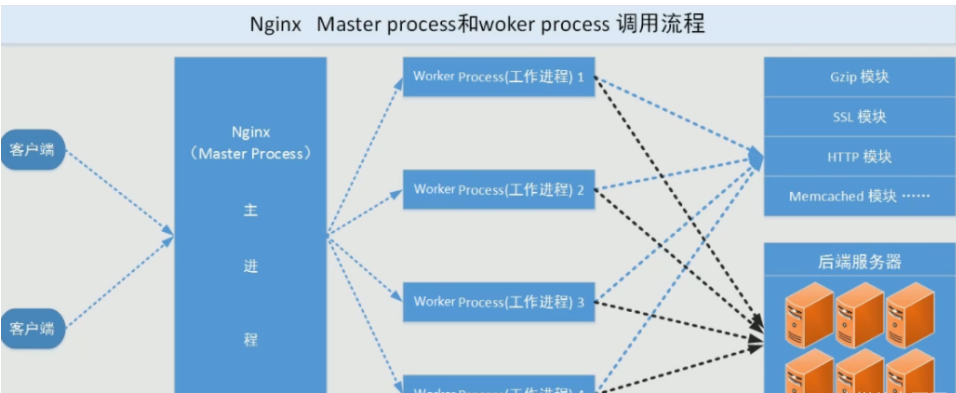
主进程(master process)的功能
对外接口:接收外部的操作(信号) 对内转发:根据外部的操作的不同,通过信号管理 Worker 监控:监控 worker 进程的运行状态,worker 进程异常终止后,自动重启 worker 进程 读取Nginx 配置文件并验证其有效性和正确性 建立、绑定和关闭socket连接 按照配置生成、管理和结束工作进程 接受外界指令,比如重启、升级及退出服务器等指令 不中断服务,实现平滑升级,重启服务并应用新的配置 开启日志文件,获取文件描述符 不中断服务,实现平滑升级,升级失败进行回滚处理 编译和处理perl脚本
工作进程(worker process)的功能:
所有 Worker 进程都是平等的 实际处理:网络请求,由 Worker 进程处理 Worker进程数量:一般设置为核心数,充分利用CPU资源,同时避免进程数量过多,导致进程竞争CPU资源, 增加上下文切换的损耗 接受处理客户的请求 将请求依次送入各个功能模块进行处理 I/O调用,获取响应数据 与后端服务器通信,接收后端服务器的处理结果 缓存数据,访问缓存索引,查询和调用缓存数据 发送请求结果,响应客户的请求 接收主程序指令,比如重启、升级和退出等
六、nginx总结核心配置和优化
6.1 配置文件说明
Nginx的配置文件的组成部分:
主配置文件:nginx.conf
子配置文件: include conf.d/*.conf
fastcgi, uwsgi,scgi 等协议相关的配置文件
mime.types:支持的mime类型,MIME(Multipurpose Internet Mail Extensions)多用途互联网邮 件扩展类型,MIME消息能包含文本、图像、音频、视频以及其他应用程序专用的数据,是设定某 种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动 使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。 MIME参考文档:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_Types
nginx 配置文件格式说明
配置文件由指令与指令块构成 每条指令以;分号结尾,指令与值之间以空格符号分隔 可以将多条指令放在同一行,用分号分隔即可,但可读性差,不推荐 指令块以{ }大括号将多条指令组织在一起,且可以嵌套指令块 include语句允许组合多个配置文件以提升可维护性 使用#符号添加注释,提高可读性 使用$符号使用变量 部分指令的参数支持正则表达式
Nginx是一个高性能的开源Web服务器和反向代理服务器。下面是Nginx的核心配置总结:
-
worker_processes:指定Nginx使用的worker进程数,一般设置为CPU核心数。
-
error_log:指定错误日志文件的路径,用于记录Nginx运行时的错误信息。
-
events:配置Nginx的事件模型。可以设置连接数、文件句柄等参数。
-
http:配置HTTP服务器相关的设置。
-
server:定义一个虚拟主机,并配置相关的参数,如监听的端口、域名等。
-
location:用于匹配请求的URL,并指定相应的处理逻辑,如静态文件访问、代理转发等。
-
access_log:指定访问日志文件的路径,用于记录客户端访问服务器的信息。
-
proxy_pass:用于反向代理配置,将请求转发到指定的后端服务器。
-
root:指定网站的根目录,用于定义静态文件的存放位置。
-
index:指定默认访问的文件名称,默认为index.html。
这些是Nginx常用的核心配置选项,通过灵活设置这些参数,可以实现不同的功能和需求。
6.2 优化
fs.file-max = 1000000 #表示单个进程较大可以打开的句柄数 net.ipv4.tcp_tw_reuse = 1 #参数设置为 1 ,表示允许将TIME_WAIT状态的socket重新用于新的TCP链接,这对于服务器来说意义重 大,因为总有大量TIME_WAIT状态的链接存在 net.ipv4.tcp_keepalive_time = 600 #当keepalive启动时,TCP发送keepalive消息的频度;默认是2小时,将其设置为10分钟,可更快的清理无 效链接 net.ipv4.tcp_fin_timeout = 30 #当服务器主动关闭链接时,socket保持在FIN_WAIT_2状态的较大时间 net.ipv4.tcp_max_tw_buckets = 5000 #表示操作系统允许TIME_WAIT套接字数量的较大值,如超过此值,TIME_WAIT套接字将立刻被清除并打印警 告信息,默认为8000,过多的TIME_WAIT套接字会使Web服务器变慢 net.ipv4.ip_local_port_range = 1024 65000 #定义UDP和TCP链接的本地端口的取值范围 net.ipv4.tcp_rmem = 10240 87380 12582912 #定义了TCP接受缓存的最小值、默认值、较大值 net.ipv4.tcp_wmem = 10240 87380 12582912 #定义TCP发送缓存的最小值、默认值、较大值 net.core.netdev_max_backlog = 8096 #当网卡接收数据包的速度大于内核处理速度时,会有一个列队保存这些数据包。这个参数表示该列队的较大值 net.core.rmem_default = 6291456 #表示内核套接字接受缓存区默认大小 net.core.wmem_default = 6291456 #表示内核套接字发送缓存区默认大小 net.core.rmem_max = 12582912 #表示内核套接字接受缓存区较大大小 net.core.wmem_max = 12582912 #表示内核套接字发送缓存区较大大小 注意:以上的四个参数,需要根据业务逻辑和实际的硬件成本来综合考虑 net.ipv4.tcp_syncookies = 1 #与性能无关。用于解决TCP的SYN攻击 net.ipv4.tcp_max_syn_backlog = 8192 #这个参数表示TCP三次握手建立阶段接受SYN请求列队的较大长度,默认1024,将其设置的大一些可使出现 Nginx繁忙来不及accept新连接时,Linux不至于丢失客户端发起的链接请求 net.ipv4.tcp_tw_recycle = 1 #这个参数用于设置启用timewait快速回收 net.core.somaxconn=262114 #选项默认值是128,这个参数用于调节系统同时发起的TCP连接数,在高并发的请求中,默认的值可能会导致 链接超时或者重传,因此需要结合高并发请求数来调节此值。 net.ipv4.tcp_max_orphans=262114 #选项用于设定系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤立 链接将立即被复位并输出警告信息。这个限制指示为了防止简单的DOS攻击,不用过分依靠这个限制甚至认为 的减小这个值,更多的情况是增加这个值
6.2.2 PAM 资源限制优化
在/etc/security/limits.conf 最后增加
-
soft nofile 65535
-
hard nofile 65535
-
soft nproc 65535
-
hard nproc 65535
七、使用脚本完成一键编译安装nginx任意版本
SRC_DIR=/usr/local/src NGINX_URL=http://nginx.org/download/ NGINX_FILE=nginx-1.20.2 #NGINX_FILE=nginx-1.18.0 TAR=.tar.gz NGINX_INSTALL_DIR=/apps/nginx CPUS=lscpu |awk '/^CPU\(s\)/{print $2}' . /etc/os-release
color () { RES_COL=60 MOVE_TO_COL="echo -en \033[${RES_COL}G" SETCOLOR_SUCCESS="echo -en \033[1;32m" SETCOLOR_FAILURE="echo -en \033[1;31m" SETCOLOR_WARNING="echo -en \033[1;33m" SETCOLOR_NORMAL="echo -en \E[0m" echo -n "$1" && $MOVE_TO_COL echo -n "[" if [ $2 = "success" -o $2 = "0" ] ;then ${SETCOLOR_SUCCESS} echo -n $" OK " elif [ $2 = "failure" -o $2 = "1" ] ;then ${SETCOLOR_FAILURE} echo -n $"FAILED" else ${SETCOLOR_WARNING} echo -n $"WARNING" fi ${SETCOLOR_NORMAL} echo -n "]" echo }
os_type () { awk -F'[ "]' '/^NAME/{print $2}' /etc/os-release }
os_version () { awk -F'"' '/^VERSION_ID/{print $2}' /etc/os-release }
check () { [ -e ${NGINX_INSTALL_DIR} ] && { color "nginx 已安装,请卸载后再安装" 1; exit; } cd ${SRC_DIR} if [ -e ${NGINX_FILE}${TAR} ];then color "相关文件已准备好" 0 else color '开始下载 nginx 源码包' 0 wget ${NGINX_URL}${NGINX_FILE}${TAR} [ $? -ne 0 ] && { color "下载 ${NGINX_FILE}${TAR}文件失败" 1; exit; } fi }
install () { color "开始安装 nginx" 0 if id nginx &> /dev/null;then color "nginx 用户已存在" 1 else useradd -s /sbin/nologin -r nginx color "创建 nginx 用户" 0 fi color "开始安装 nginx 依赖包" 0 if [ $ID == "centos" ] ;then if [[ $VERSION_ID =~ ^7 ]];then yum -y -q install make gcc pcre-devel openssl-devel zlib-devel perl-ExtUtils-Embed elif [[ $VERSION_ID =~ ^8 ]];then yum -y -q install make gcc-c++ libtool pcre pcre-devel zlib zlib-devel openssl openssl-devel perl-ExtUtils-Embed else color '不支持此系统!' 1 exit fi elif [ $ID == "rocky" ];then yum -y -q install make gcc-c++ libtool pcre pcre-devel zlib zlib-devel openssl openssl-devel perl-ExtUtils-Embed else apt update &> /dev/null apt -y install make gcc libpcre3 libpcre3-dev openssl libssl-dev zlib1g-dev &> /dev/null fi cd $SRC_DIR tar xf ${NGINX_FILE}${TAR} NGINX_DIR=echo ${NGINX_FILE}${TAR}| sed -nr 's/^(.*[0-9]).*/\1/p' cd ${NGINX_DIR} ./configure --prefix=${NGINX_INSTALL_DIR} --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module make -j $CPUS && make install [ $? -eq 0 ] && color "nginx 编译安装成功" 0 || { color "nginx 编译安装失败,退出!" 1 ;exit; } echo "PATH=${NGINX_INSTALL_DIR}/sbin:${PATH}" > /etc/profile.d/nginx.sh cat > /lib/systemd/system/nginx.service <<EOF [Unit] Description=The nginx HTTP and reverse proxy server After=network.target remote-fs.target nss-lookup.target
[Service] Type=forking PIDFile=${NGINX_INSTALL_DIR}/logs/nginx.pid ExecStartPre=/bin/rm -f ${NGINX_INSTALL_DIR}/logs/nginx.pid ExecStartPre=${NGINX_INSTALL_DIR}/sbin/nginx -t ExecStart=${NGINX_INSTALL_DIR}/sbin/nginx ExecReload=/bin/kill -s HUP $MAINPID KillSignal=SIGQUIT TimeoutStopSec=5 KillMode=process PrivateTmp=true LimitNOFILE=100000
[Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable --now nginx &> /dev/null systemctl is-active nginx &> /dev/null || { color "nginx 启动失败,退出!" 1 ; exit; } color "nginx 安装完成" 0 }
check install
八、任意编译一个第3方nginx模块,并使用
第三模块是对nginx 的功能扩展,第三方模块需要在编译安装Nginx 的时候使用参数–add- module=PATH指定路径添加,有的模块是由公司的开发人员针对业务需求定制开发的,有的模块是开 源爱好者开发好之后上传到github进行开源的模块,nginx的第三方模块需要从源码重新编译进行支持
8.1 nginx-module-vts 模块实现流量监控
下载地址:https://github.com/vozlt/nginx-module-vts
下载并解压3
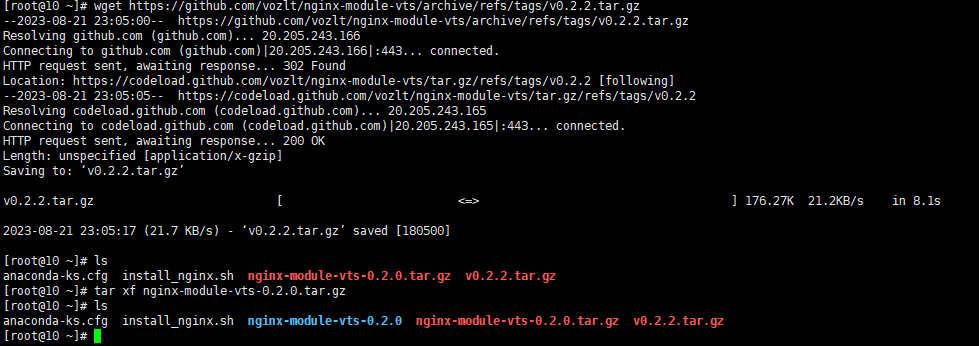
make && make install

vim /apps/nginx/conf.d/pc.conf

编译完成后需要重启nginx服务
systemctl restart nginx
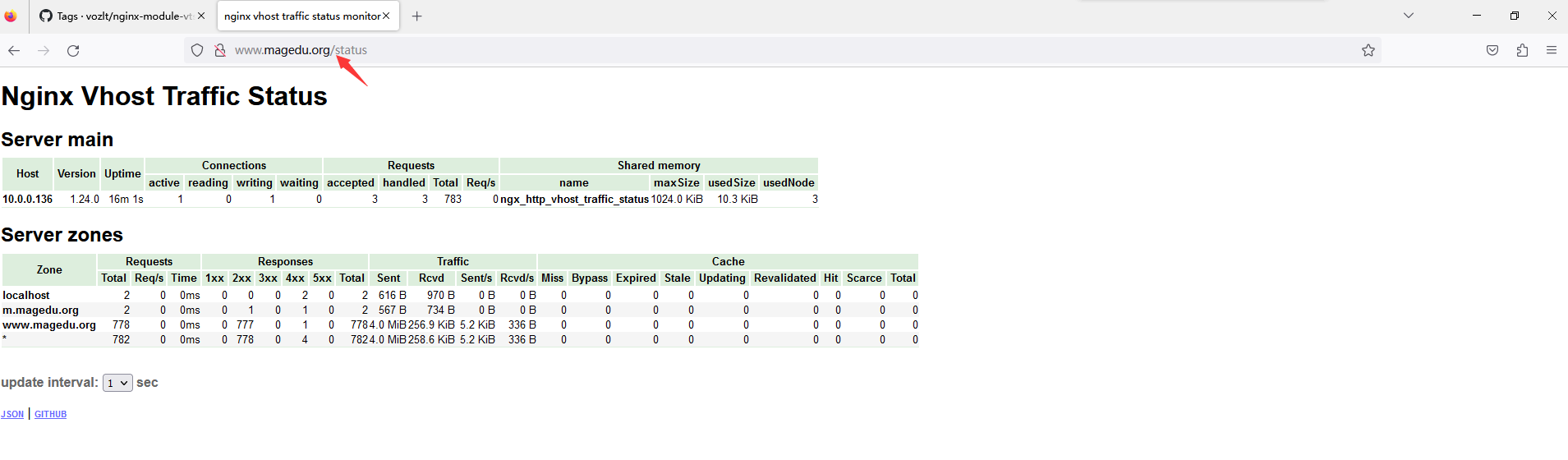
浏览器访问验证www.magedu.org/status 可以看到下面显示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号