第七周作业
1.1体系架构概览
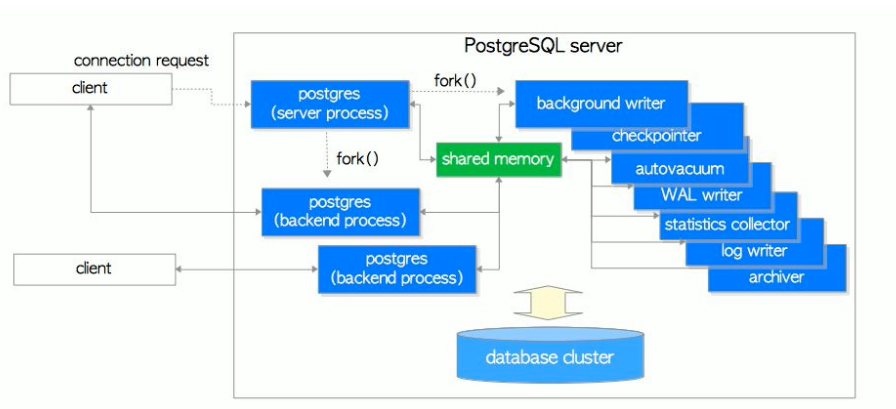
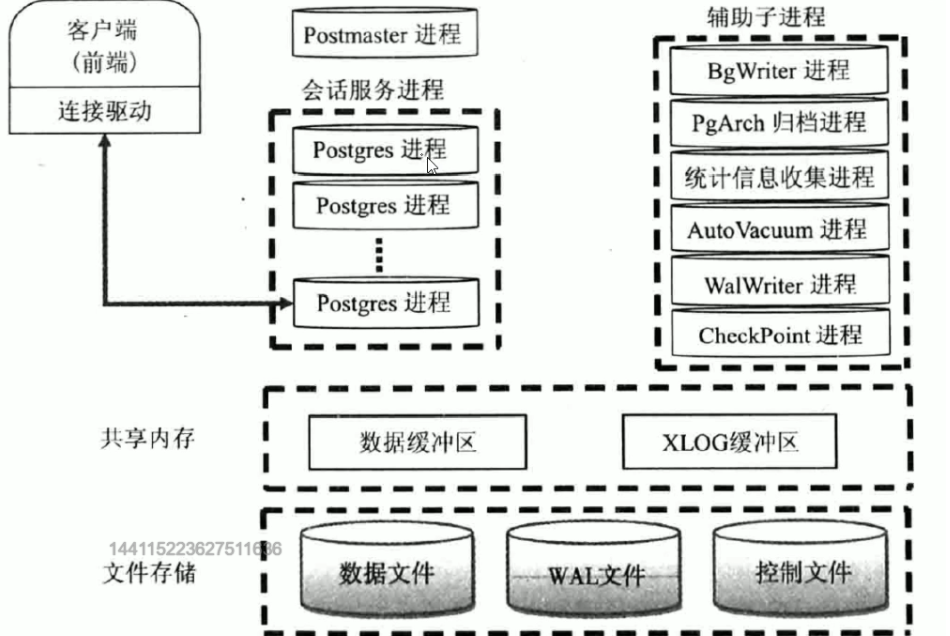
PostgreSQL和MySQL相似,也采用典型的C/S模型。 PostgreSQL体系结构分两部分
-
实例 instance(内存)
-
磁盘存储
-
进程(客户端的响应进程,服务端的处理进程)
-
内存存储结构
![]()
1.2 进程
Postmaster 主进程
BgWriter 后台写进程
WalWriter 预写式日志进程(类似于mysql的事务日志)有了日志优点安全、速度快,缺点磁盘空间大、IO多一次—日志追加写入比直接随机写入数据库快
Checkpointer 检查点进程(数据写入到磁盘)
AutoVacuum 自动清理进程
PgStat 统计数据收集进程
PgArch 归档进程
SysLogger 系统日志进程
startup 启动进程
Session 会话进程
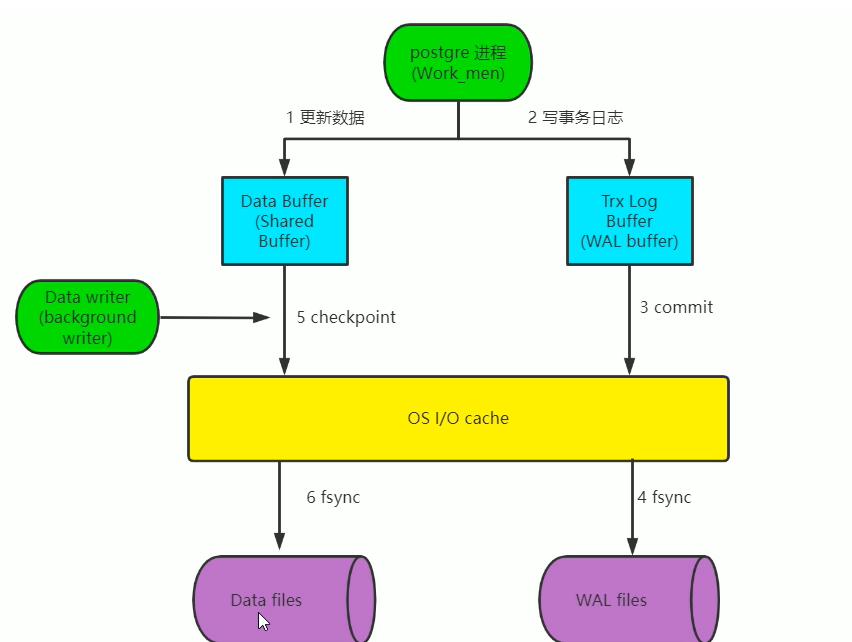
1.3 数据更新过程
-
先将数据库文件中的更改的数据加载至内存
-
在内存更新数据
-
将日志写入内存WAL的缓存区
-
将日志提交,将日志写入操作系统 cache
-
同步日志到磁盘
-
后台写数据库的更新后的数据到操作系统 cache
-
写完数据后,更新检查点checkpoint
-
同步数据到磁盘
二、基于流复制完成postgresql的高可用
2.1 基础环境准备
两个主机节点
10.0.0.136 Master 10.0.0.137 Standby
2.2 Master 节点配置
创建复制的用户并授权

修改pg_hba.conf进行授权

#修改配置(可选): [postgres@master ~]$vi /pgsql/data/postgresql.conf synchronous_standby_names = '*' #开启此项,表示同步方式,需要同时打开synchronous_commit = on,此为默认值,默认是异步方式 synchronous_commit = on #开启同步模式 archive_mode = on #建议打开归档模式,防止长时间无法同步,WAL被覆盖造成数据丢失 archive_command = '[ ! -f /archive/%f ] && cp %p /archive/%f' wa1_level = replica #设置wal的级别 max_wal_senders = 5 #这个设置可以最多有几个流复制连接,一般有几个从节点就设置几个 wal_keep_segments = 128 #设置流复制保留的最多的WAL文件数目 wal_sender_timeout = 60s #设置流复制主机发送数据的超时时间 max_connections = 200 # 一般查多于写的应用从库的最大连接数要比较大 hot_standby = on #对主库无影响,用于将来可能会成为从库,这台机器不仅仅是用于数据归档,也用于数 据查询,在从库上配置此项后为只读 max_standby_streaming_delay = 30s #数据流备份的最大延迟时间 wal_receiver_status_interval = 10s #多久向主报告一次从的状态,当然从每次数据复制都会向主报 告状态,只是设置最长的间隔时间 hot_standby_feedback = on #如果有错误的数据复制,是否向主进行反馈 wal_log_hints = on #对非关键更新进行整页写入
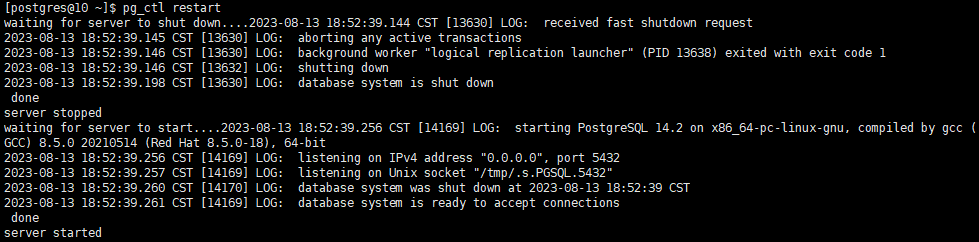
重启服务
2.3 Standby 节点配置
#清空数据和归档(此步骤已做,不重复) pg_ctl stop -D $PGDATA rm -rf /pgsql/data/* rm -rf /archive/* rm -rf /pgsql/backup/* #备份主库数据到备库 pg_basebackup -D /pgsql/backup/ -Ft -Pv -Urepluser -h 10.0.0.101 -p 5432 -R #还原备份的数据,实现初始的主从数据同步(此步骤已做,不重复) tar xf /pgsql/backup/base.tar -C /pgsql/data tar xf /pgsql/backup/pg_wal.tar -C /archive/
修改postgresql.conf文件

#修改配置(可选): hot_standby = on #开启此项,此是默认项 recovery_target_timeline = latest # 默认 max_connections = 120 # 大于等于主节点,正式环境应当重新考虑此值的大小 max_standby_streaming_delay = 30s wal_receiver_status_interval = 10 shot_standby_feedback = on max_wal_senders = 15 1ogging_co1lector = on 1og_directory = 'pg_log' 1og_filename = 'postgresql-%Y-%m-%d_%H%M%S.1og'
在主库查看状态
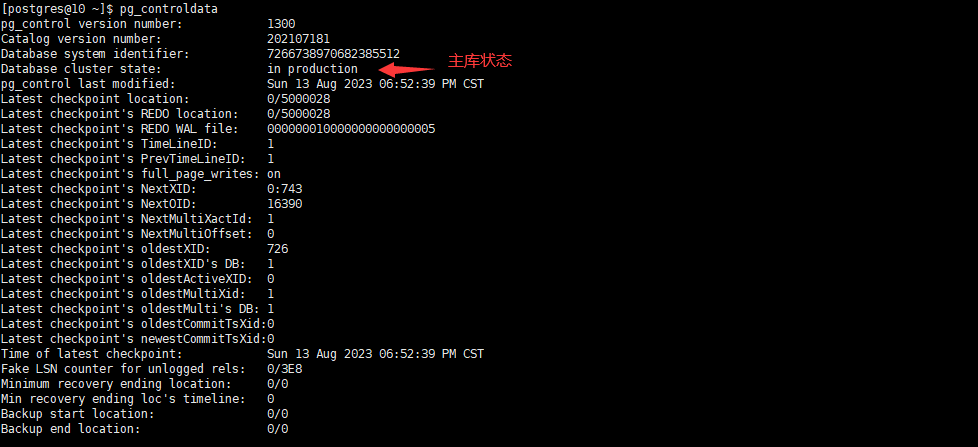


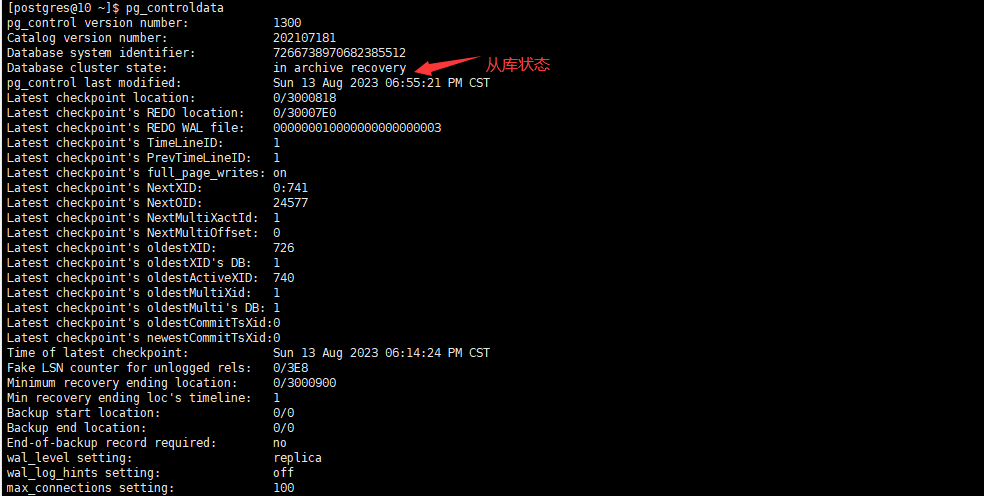
在从库查看状态
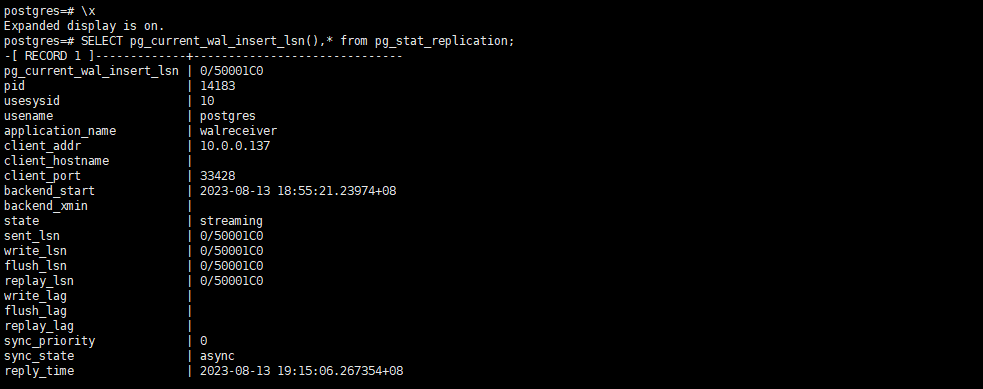
查看同步状态

三、实现postgresql的时间点还原
.1 利用PITR实现误删除的实战案例
场景说明 每天2:00备份,第二天10:00误删除数据库,如何恢复? 故障恢复过程 备份数据和归档 还原流程
-
还原完全备份
-
归档日志恢复:
-
备份中的归档
-
恢复2:00到10:00之间的归档
-
恢复在线redo
3.1.1 备份(备份时必须停止业务)
#在PG服务器开启归档
[postgres@pgserver ~]$ vim /pgsql/data/postgresql.conf
archive_mode = on
archive_command = 'test ! -f /archive/%f &&cp %p /archive/%f'
[postgres@gpserver ~]$pg_ctl restart -D $PGDATA
#在PG服务器上创建测试数据
postgres=#create database testdb;
postgres=#\c testdb
testdb=# create table t1(id int);
testdb=# insert into t1 values(1);
#在备份服务器对PG数据库进行远程完全备份
[postgres@backup ~]$pg_basebackup -D /pgsql/backup/ -Ft -Pv -Upostgres -h
10.0.0.200 -p 5432 -R
#在PG服务器上继续生成测试数据
testdb=# insert into t1 values(2);
#模拟数据库删除
postgres=# drop database testdb;
#发现故障,停止用户访问
#查看当前日志文件
postgres=# select pg_walfile_name(pg_current_wal_lsn());
-[ RECORD 1 ]---+-------------------------
pg_walfile_name | 000000020000000000000020
#查看当前事务ID
postgres=# select txid_current();txid_current --------------
521
(1 row)
-
-
3.1.2 故障还原
#在PG服务器上切换归档日志(好处是以后这个文件不再使用)
postgres=#select pg_switch_wal();
#在要还原的服务器停止服务,准备还原
[postgres@pgserver ~]$pg_ctl stop -D $PGDATA
[postgres@pgserver ~]$rm -rf /pgsql/data/*
#在测试的还原服务器进行还原
[postgres@backup ~]$tar xf /pgsql/backup/base.tar -C /pgsql/data/
#此步可以不执行
[postgres@backup ~]$tar xf /pgsql/backup/pg_wal.tar -C /archive/
#复制PG服务器的归档日志到还原的测试服务器
[postgres@pgserver ~]$rsync -a 10.0.0.200:/archive/ /archive/
#查看故障点事务ID
[postgres@backup ~]$pg_waldump /archive/000000020000000000000020 |grep -B 10
"DROP dir"
rmgr: Database len (rec/tot): 34/ 34, tx: 521, lsn: 0/3D000828,
prev 0/3D0007B0, desc: DROP dir 1663/16445
#查看此指令的事务ID为521,前一个事务为520
#修改配置文件postgresql.conf,或者postgresql.auto.conf文件也可以
[postgres@backup ~]$vi /pgsql/data/postgresql.conf
#加下面两行
restore_command = 'cp /archive/%f %p'
#指定还原至上面查到的事务ID
recovery_target_xid = '520'
#也可以通过下面方式指定还原至的位置
recovery_target_name = 'restore_point' #指定还原点名称
recovery_target_time = '2021-01-17 16:26:12' #指定还原至时间点
recovery_target_lsn = '0/3E000148' #指定还原到LSN号的位置
#启动服务
[postgres@backup ~]$pg_ctl start -D $PGDATA
#验证数据
[postgres@backup ~]$psql
psql (12.9)
Type "help" for help.
postgres=# \c testdb
You are now connected to database "testdb" as user "postgres".
testdb=# select * from t1;id
\----
1
2
(2 rows)
#验证数据是否还原,恢复后读取正常
testdb=# select * from t1;id
\----
1
2
3
(3 rows)
#当前无法写入
testdb=# insert into t1 values(4);
ERROR: cannot execute INSERT in a read-only transaction
[postgres@pgserver ~]$pg_controldata
pg_control version number: 1300
Catalog version number: 202107181
Database system identifier: 7064396403376562327
Database cluster state: in archive recovery
#恢复正常模式
postgres=# select pg_wal_replay_resume();
[postgres@pgserver ~]$pg_controldata
pg_control version number: 1300
Catalog version number: 202107181
Database system identifier: 7064396403376562327
Database cluster state: in production
#恢复正常写入
testdb=# insert into t1 values(4);
四、规划高可用的LAMP,要求wordpress网站放在NFS共享存储上,并且用户可以正常发布博客,上传图片。尝试更新wordpress版本,测试网站仍可用
主备两台主机:10.0.0.136(部署LAMP)10.0.0.135(做nfs服务器,为了防止服务器故障,文件丢失)
1、10.0.0.136主机搭建LAMP,配置如下:
使用yum安装httpd、php、php-mysqlnd php-json mysql-server
开机启动mysql、httpd


进入此网站https://cn.wordpress.org/download/下载wordpress,右击复制此链接,使用wget下载复制的链接
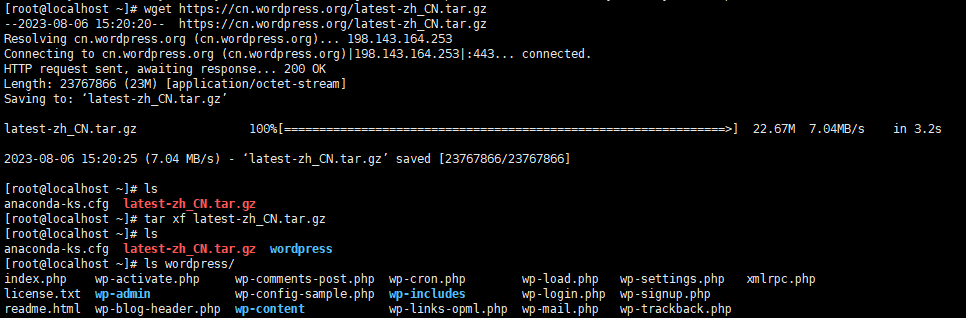
把wordpress文件移到/var/www/html下,并授权

进入mysql,创建数据库,创建账号并授权



进入已搭建的LAMP主机ip地址查看(下图是我已经搭建好的,刚搭建好的需要输入账号密码等步骤)
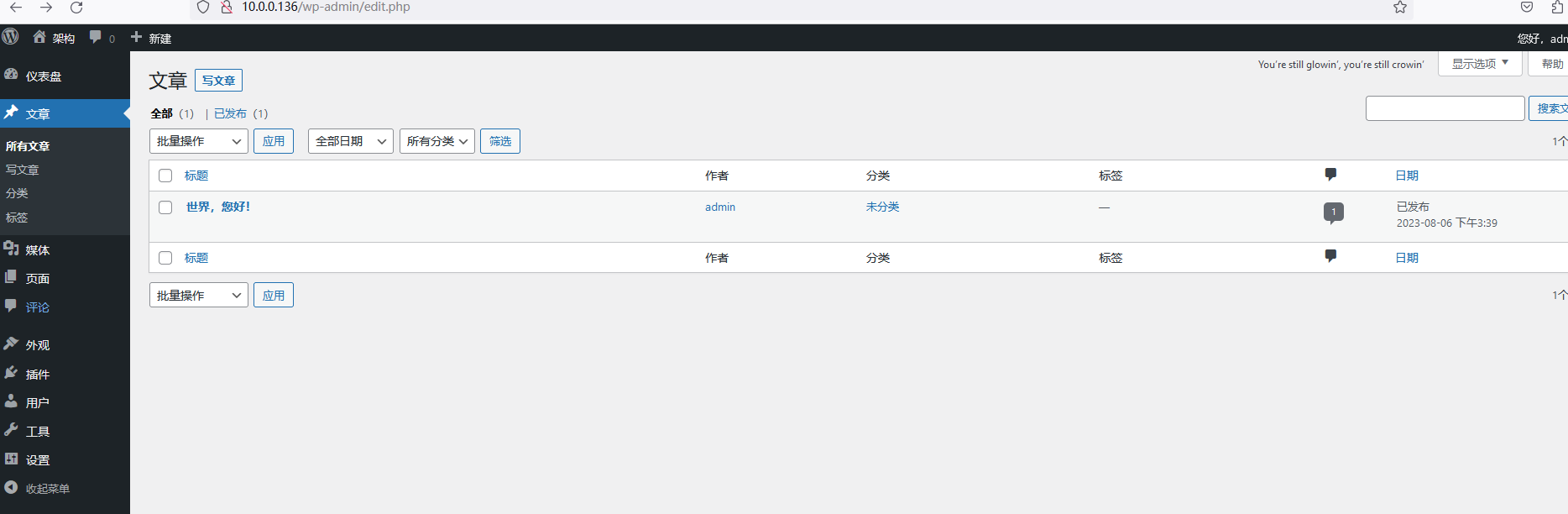
网址文件所放目录

2、部署nfs共享服务器
建目录存放共享文件
mkdir /data/zz
编辑vim /etc/exports文件共享

建账号,都映射为同一个账号,授权


安装nfs,启动服务

使用showmount查看是否看到共享

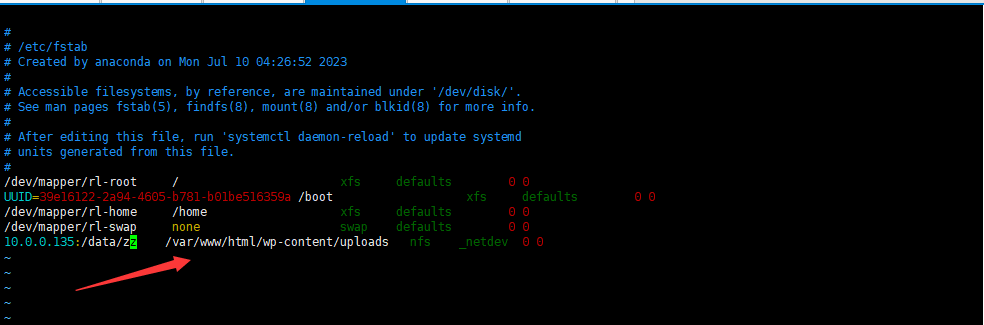
永久挂载进入vim /etc/fstab

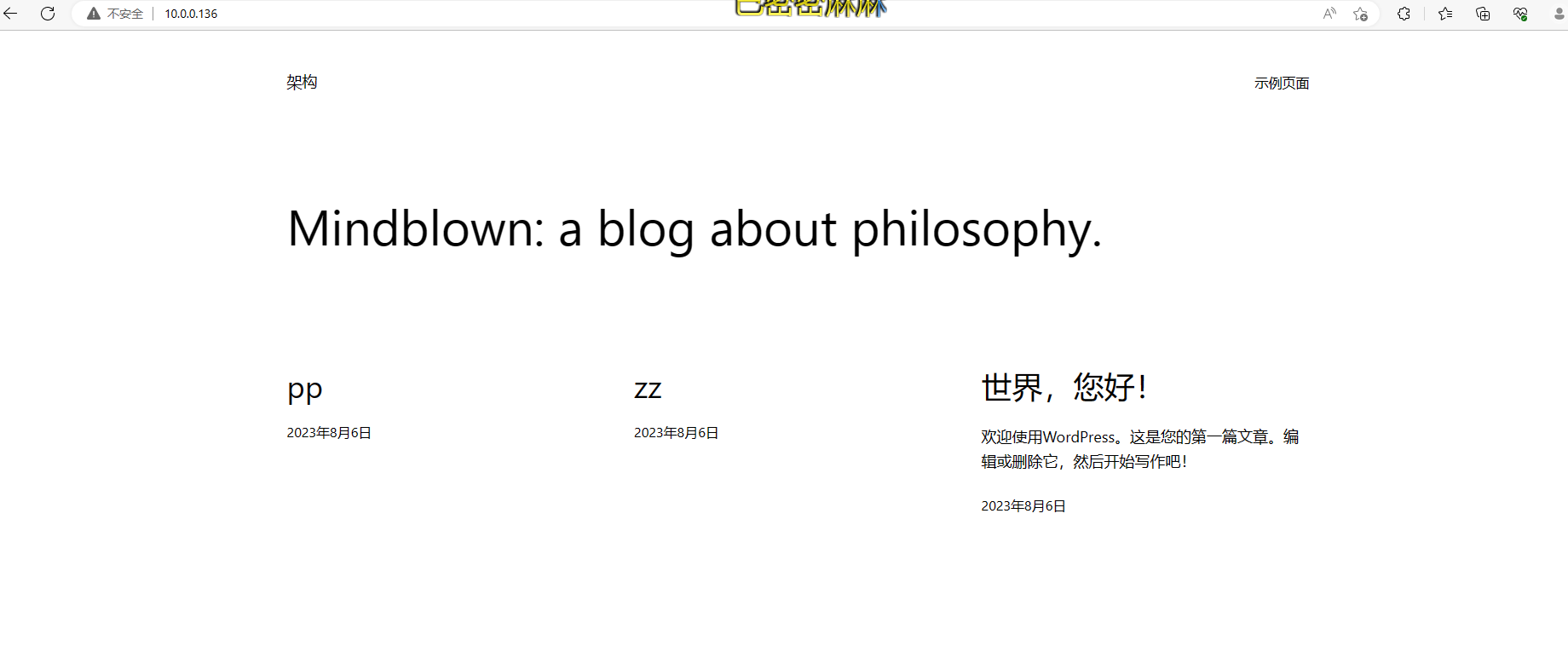
再写一篇文章查看是否共享成功,下图为之前写的
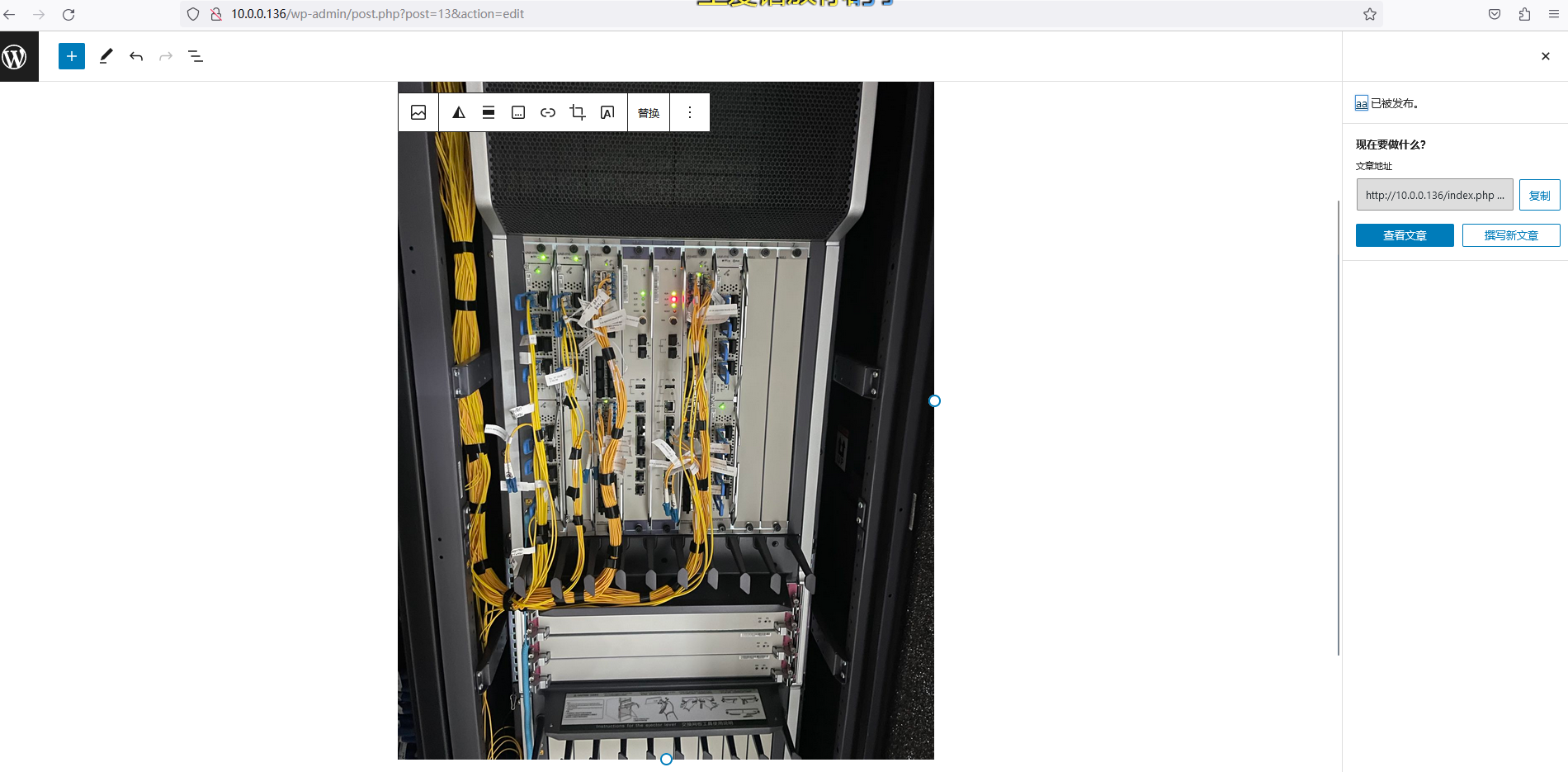
已发布的新文章,在nfs服务器上查看

五、redis数据类型有哪些?
参考资料:http://www.redis.cn/topics/data-types.html 相关命令参考: http://redisdoc.com/

5.1 字符串 string
字符串是一种最基本的Redis值类型。Redis字符串是二进制安全的,这意味着一个Redis字符串能包含任意类型的数据,例如: 一张JPEG格式的图片或者一个序列化的Ruby对象。一个字符串类型的值最多能存储512M字节的内容。Redis 中所有 key 都是字符串类型的。此数据类型最为常用
数字递增 利用INCR命令簇(INCR, DECR, INCRBY,DECRBY)来把字符串当作原子计数器使用。 博客点赞、评论用此方法比较简便,像mysql需要update
5.2 列表 list

5.3 集合 set**
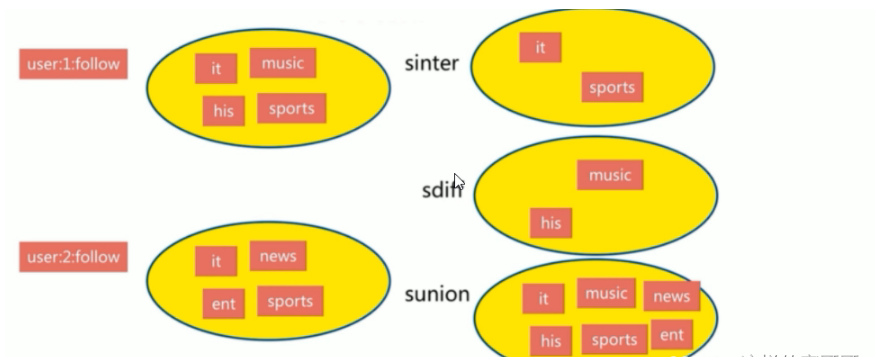
集合特点
-
无序
-
无重复
-
集合间操作
交集
-
可以实现共同的朋友 差集
-
可以实现我的朋友的朋友 并集
5.4 有序集合 sorted set
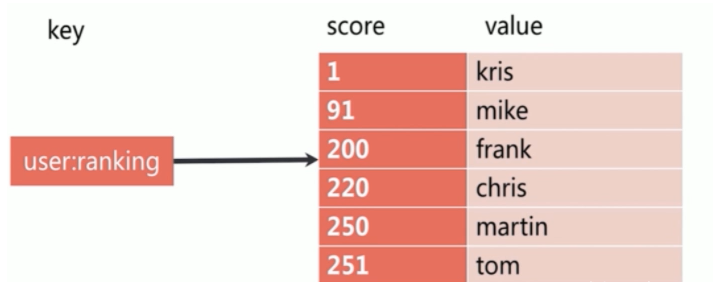
Redis有序集合和Redis集合类似,是不包含相同字符串的合集。它们的差别是,每个有序集合的成员都关联着一个双精度浮点型的评分,这个评分用于把有序集合中的成员按最低分到最高分排序。有序集合的成员不能重复,但评分可以重复,一个有序集合中最多的成员数为 2^32 - 1=4294967295个,经常用于排行榜的场景
有序集合特点 有序 无重复元素 每个元素是由score和value组成 score 可以重复 value 不可以重复
5.5 哈希 hash
hash 即字典, 用于保存字符串字段field和字符串值value之间的映射,即key/value做为数据部分,hash特别适合用于存储对象场景. 一个hash最多可以包含2^32-1 个key/value键值对 哈希特点
-
无序
-
k/v 对
-
适用于存放相关的数据
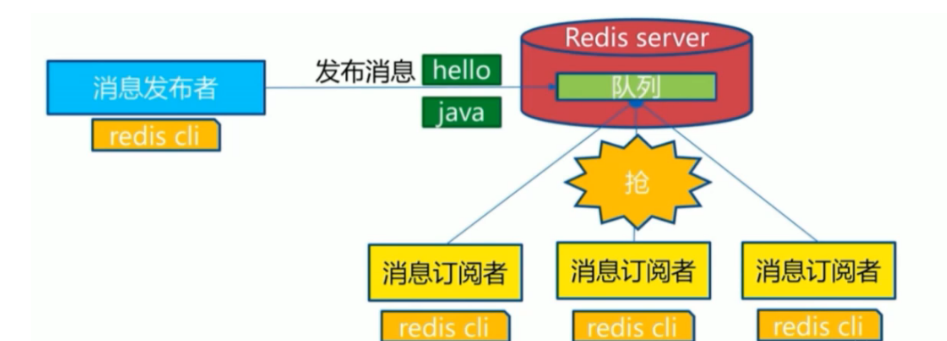
5.6 消息队列
消息队列: 把要传输的数据放在队列中,从而实现应用之间的数据交换 常用功能: 可以实现多个应用系统之间的解耦,异步,削峰/限流等 常用的消息队列应用: Kafka,RabbitMQ,Redis 消息队列分为两种
生产者/消费者模式: Producer/Consumer
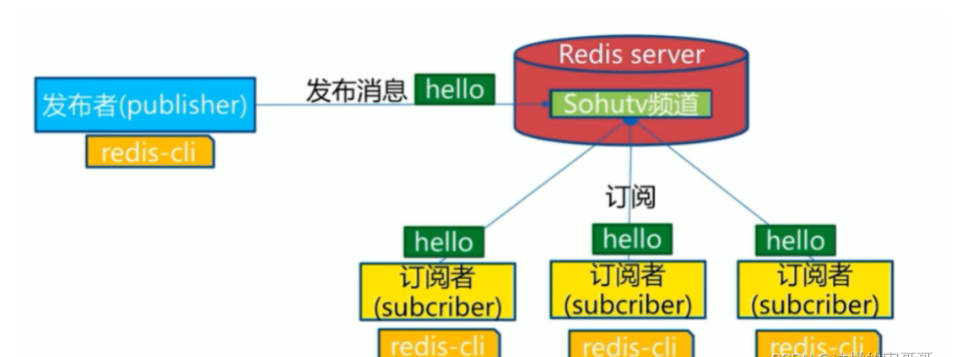
发布者/订阅者模式: Publisher/Subscriber
六、redis RDB和AOF比较?
Redis是一个开源的内存数据存储系统,它提供了两种持久化机制:RDB(Redis Database)和AOF(Append-Only File)。
RDB是一种快照方式的持久化机制,它会定期将内存中的数据保存到磁盘上的一个二进制文件中。RDB的优点是通过将整个数据集写入磁盘,可以获得非常高的性能和压缩率。此外,RDB文件也非常适合备份和恢复数据,因为它是一个紧凑的文件,可以在不加载整个数据集的情况下进行快速恢复。然而,RDB的缺点是,如果Redis发生意外崩溃,可能会丢失最后一次快照之后的所有数据。
AOF是一种日志方式的持久化机制,它会将Redis服务器执行的每个写操作追加到一个文件的末尾。AOF的优点是可以提供更高的数据安全性,因为它记录了每个写操作,可以在Redis重启时重新执行这些操作以恢复数据。此外,AOF也具有更好的故障恢复能力,因为它可以通过重放AOF文件来修复潜在的损坏。然而,AOF的缺点是日志文件比RDB文件要大,因此在磁盘使用和恢复时间方面可能会更慢。
综合来说,RDB适用于对性能和备份恢复要求较高的场景,而AOF适用于对数据安全性和故障恢复要求较高的场景。在实际使用中,也可以同时启用RDB和AOF,以实现更好的持久化和数据保护。
七、redis配置文件详解。
Redis的配置文件(redis.conf)是用来配置Redis服务器的各种参数和选项的。下面是一些常见的Redis配置项的解释:
-
bind:指定服务器监听的IP地址。默认是127.0.0.1,表示只接受本地连接。如果要让其他机器可以连接到Redis服务器,可以将该项设置为服务器的IP地址。 -
port:指定Redis服务器监听的端口号。默认是6379。 -
requirepass:设置连接Redis服务器时需要的密码。如果没有设置密码,可以将该项注释掉或者留空。设置密码可以提高服务器的安全性。 -
daemonize:指定是否以守护进程模式运行,默认为no。如果设置为yes,Redis将后台运行,并将日志输出到指定的文件中。 -
logfile:指定服务器的日志文件路径。默认是标准输出(stdout)。 -
dir:指定数据库的存储路径。默认是当前目录。 -
maxmemory:指定Redis服务器使用的最大内存量。默认是无限制。当达到最大内存限制时,Redis可以使用一些策略来处理数据,如LRU(最近最少使用)等。 -
maxclients:指定Redis服务器能同时接受的最大客户端连接数。默认是无限制。 -
timeout:指定客户端连接超时时间,默认是0,表示不超时。 -
appendonly

 浙公网安备 33010602011771号
浙公网安备 33010602011771号