第四周作业
一、自定义写出10个定时任务
1、0 3 * * 3 data
每周三凌晨三点执行data
2、*/30 * * * /root/check_disk2.sh
每30分钟执行一次该脚本
3、0 9 * * 1-5 backup.sh
每周一至周五的早上9点进行备份
4、0 3 * * 6 cleanup.sh
每个星期六的凌晨3点执行清理任务
5、*/10 * * * 1-5 disk_space_check.sh
每10分钟就执行一次磁盘空间检查脚本
6、0 */2 * * * meminfo_script.sh
每两小时运行该脚本
7、0 4 1 * * systemctl restart httpd
每月1号的4点重启http服务*
8、0 5-11/2 * * * cat /dev/null > /var/www/html
早上5点到晚上11点之间,每隔2个小时清理/var/www/html目录一次
9、30 8-18/2 * * * date
每天早上8点到下午18点每隔2小时的每30分钟 查看时间
10、30 23 * * * reboot
每天晚上11点30重启主机
以上10条需加入vim crontab -e
二、图文并茂说明Linux进程和内存概念
进程是一个其中运行着一个或多个线程的地址空间和这些线程所需要的系统资源。一般来说,Linux系统会在进程之间共享程序代码和系统函数库,所以在任何时刻内存中都只有代码的一份拷贝。
进程状态
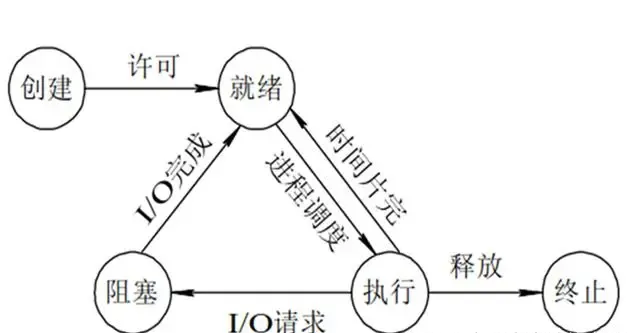
创建状态:进程在创建时需要申请一个空白PCB,向其中填写控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态。
就绪状态:进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行。
执行状态:进程处于就绪状态被调度后,进程进入执行状态。
阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用。
终止状态:进程结束,或出现错误,或被系统终止,进入终止状态,无法再执行。进程优先级
进程优先级
优先级是指CPU为进程分配资源的先后顺序,优先权高的进程有优先执行的权利(数字越小优先级越高)。
系统优先级取值范围 0至139
nice优先级取值范围 -20至19
可以手动在取值范围内修改优先级,在top后按r,输入pid,再输入nice值
内存模型
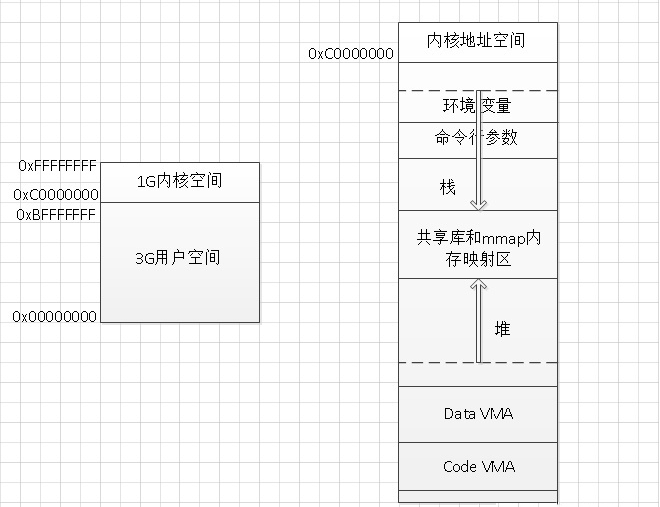
在一个32位的操作系统中每一个进程的虚拟地址空间位4GB。其中1G为内核空间3G为用户空间,每一个进程的用户空间又可以分为:用户栈、共享库、用户堆、数据段和代码段五个部分。
用户栈:用户栈用来保存各种了临时数据,包括函数中的参数传递,和函数内的局部变量。栈的扩展方向是自顶向下,栈底地址为高地址,栈顶为低地址,栈的出入遵循先进后出原则。
共享库:共享库用来保存程序执行时所需要依赖的共享代码库(比如libc),这些代码库文件的实际地址会被会被映射到用户栈下方的虚拟地址,并被标记为只读。
用户堆:用户堆管理的是用户程序在运行过程中动态分配的内存,当用户需要时可以通过手动申请,用完之后在手动清空。堆的扩展方向与栈相反为自底向上,堆底在低地址,堆顶在高地址,当用户申请内存,堆顶指针会向上生长。
数据段:数据段主要保存的是程序中的全局变量、静态变量以及字符串常量,这些变量的生存周期通常是伴随程序的整个运行周期。
代码段:代码段主要保存的是编译完成的二进制代码。
内核地址空间:内核地址空间在进程用户态运行时通常是不可见的,只有进程进入到内核态时才能进行内核内存访问。
进程内存关系
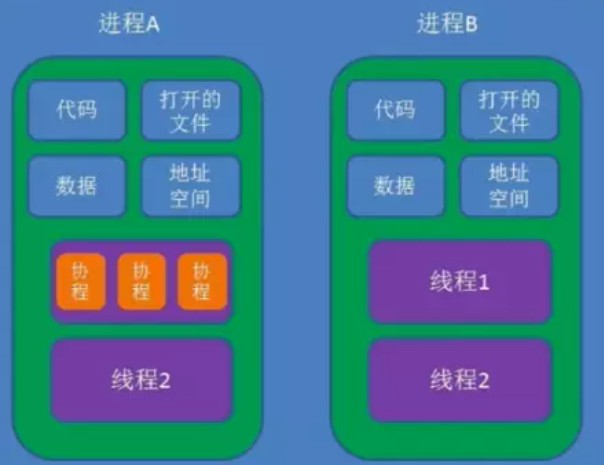
进程即值执行的程序,都必须占用一定数量的内存,用来存放从磁盘载入的程序代码,还有存放取自用户输入的数据等等。不过进程对这些内存的管理方式因内存用途不一而不尽相同,有些内存是事先静态分配和统一回收的,而有些却是按需要动态分配和回收的。
进程组成:线程(协程) + 代码 + 数据 + 打开文件 + 地址空间
三、图文并茂说明Linux启动流程
linux开机启动流程图
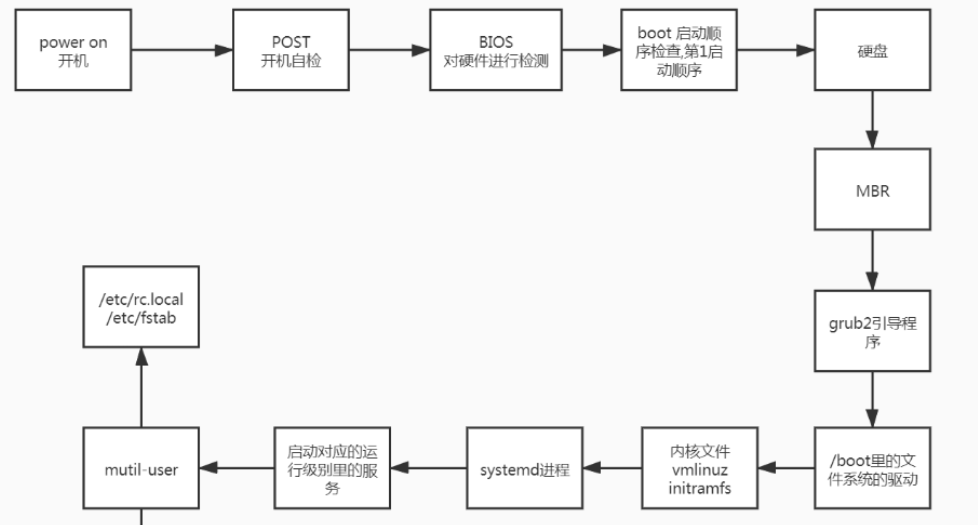
1、开机自检 (POST, Power On Self Test) 电脑通电之后,首先加载BIOS(basic input output system,基本输入输出系统)。而BIOS程序首先检查计算机能否满足运行的基本条件,这个叫做“硬件自检(Power On Self Test)”。
主要检查:主板,CPU,内存,磁盘,网卡,声卡,显卡,鼠标,键盘,显示器等
2、启动顺序 硬件自检完成后,BIOS把控制权转交给下一阶段的启动程序。这是,BIOS需要知道,“下一阶段的启动程序”具体存放在哪个设备里(磁盘,光盘,移动硬盘等)。也就是说,BIOS需要有一个外部存储设备的排序,排在前面的设备就是优先转交控制权的设备。这种排序叫做“启动顺序”(Boot Sequence)
3、主引导记录 MBR( master boot record) 主引导记录只有512个字节,位于0柱面,0磁道,1扇区,放不了太多东西。它的主要作用是,告诉计算机到硬盘的那一个位置去找操作系统
4、启动管理器 Grub 在这种情况下,计算机读取”主引导记录”前面446字节的机器码之后,不再把控制权转交给某一个分区,而是运行事先安装的”启动管理器”(boot loader),由用户选择启动哪一个操作系统。
Linux环境中,目前最流行的启动管理器是Grub
在centos7中的启动管理是grub25、 操作系统
5、操作系统
控制权转交给操作系统后,操作系统的内核首先被载入内存。开始运行第一个程序systemd,执行默认target配置文件/etc/systemd/system/default.target
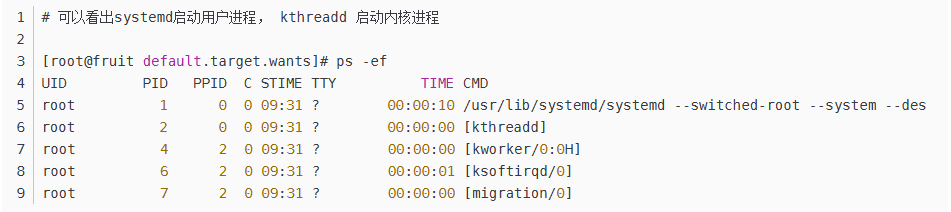
6、运行级别


7、用户登录
登录shell
首先读取/etc/profile配置文件,加载/etc/profile.d/*.sh,再去用户的家目录,读取~/.bash_profile,然后去~/.bashrc,最后读取/etc/bashrc。进行初始环境变量
非登录shell
四、自定义一个systemd服务定时去其他服务器上检查/tmp/下文件的个数,如果发现数量有变化就记录变化情况到文件中
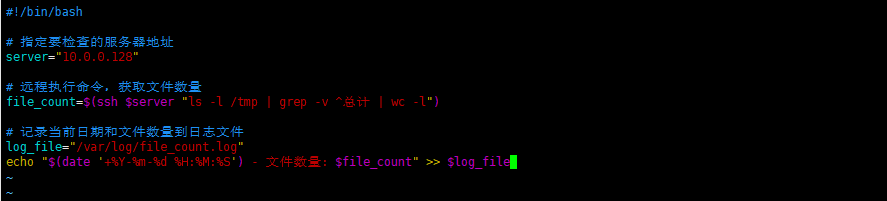
首先,创建一个脚本来执行文件数量检查并记录变化情况。创建一个名为check.sh的文件
touch check.sh
编辑 check.sh添加以下内容
创建一个systemd服务单元配置文件。使用文本编辑器创建一个名为file_count.service的文件
编辑vim /etc/systemd/system/file_count.service

为/var/log/file_count.log文件创建权限
touch /var/log/file_count.log
chown root: /var/log/file_count.log
chmod 644 /var/log/file_count.log
加载并启用该systemd服务
systemctl daemon-reload
systemctl enable file_count.service
五、写Linux内核编译安装博客

安装需要的包
yum -y install gcc make ncurses-devel flex bison openssl-devel elfutils-libelf-devel bc perl
tar xf linux-5.18.9.tar.xz -C /usr/local/src
cd /usr/local/src/linux-5.18.9
cp /boot/config-$(uname -r) .config
vim .config
#修改下面三行
CONFIG_MODULE_SIG=y#注释此行
CONFIG_SYSTEM_TRUSTED_KEYS=" "此行需修改
CONFIG_DEBUG_INFO_BTF=y 更改内核版本名称
编译
make bzImage
make modules_install
make installreboot
六、总结5个自我觉得比较有用的awk的使用场景,比如在什么情况下用awk处理文本效率最高,发散题,至少写1个。
1、数据提取和转换:awk非常适合用于处理文本数据中的特定字段。它可以根据特定的分隔符或正则表达式提取数据,并对其进行转换、格式化或重组。例如,你可以使用awk从CSV文件中提取特定列的数据并输出到新的文件中。
2、数据过滤:awk可以根据指定的条件过滤数据。你可以使用awk对文本数据进行筛选,只保留满足某些条件的行或字段。这在处理大型日志文件或数据抽取时非常有用。
3、统计分析:awk具有内建的计数和聚合功能,可以轻松地进行数据统计和分析。你可以使用awk计算行数、求和、平均值,或者根据数据的某个字段进行分组和聚合。这在生成汇总报告或数据摘要时非常实用。
4、文本格式化和报告生成:awk可以根据特定的规则对文本进行格式化,并生成报告或摘要。你可以使用awk在输出文本中添加标题、页眉、页脚,或者对数据进行排序和对齐。
5、数据处理流水线:awk可以与其他UNIX工具(如grep、sed和sort)结合使用,构建强大的数据处理流水线。你可以使用awk在数据处理管道中的不同步骤中筛选、转换和分析数据,实现复杂的数据处理任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号