Python爬取猎聘网的数据进行分析
前言:
一、选题的背景
近年来,越来越多的年轻人在寻找工作这个方面呢的事情上会出现各种问题,而好的工作非常难找,差的工作很多年轻人也不想做,所以我选择做一份数据分析一下招聘网站上各个工作的情况。
二、项目目标分析
本项目是对猎聘网的数据进行爬取分析,主要分析的目标是招聘信息,学历要求等;
分析在猎聘网中寻找的工作招聘信息,薪资以及其他福利待遇,以及对求职者的学历要求要多高进行分析。
三、网络爬虫设计方案
(1)爬虫名称:爬取猎聘网的数据进行分析
参考书籍:
- 《Python3网络爬虫开发实战》-崔庆才
- 《Python数据可视化》-Kirthi Raman
- 《深入浅出MySQL》
参考文档:
- python 3.6官方文档;
- Requests:让HTTP服务人类;
- Beautiful Soup documentation;
- pyecharts;
四、python爬虫抓取IT类招聘信息的实现
2.1、代码
1 mport requests 2 import lxml 3 import re 4 import pymysql 5 from bs4 import BeautifulSoup 6 from multiprocessing import Pool 7 8 def getTableName(ID): 9 """ 10 有些分类标识符ID中带有MySql数据库表名不支持的符号,该函数返回合法表名 11 """ 12 replaceDict={ 13 "Node.JS":"NodeJS", 14 ".NET":"NET", 15 "C#":"CC", 16 "C++":"CPP", 17 "COCOS2D-X":"COCOS2DX" 18 } 19 if ID in replaceDict: 20 return replaceDict[ID] 21 else: 22 return ID 23 24 def parseWage(wage): 25 """ 26 该函数实现了解析工资字符串wage,如果是'面议'或者其它则返回列表[0,0](代表工资面议),否则返回 27 相应工资(数值类型,单位为万) 28 """ 29 parsedResult=re.findall('(.*?)-(.*?)万.*?',wage,re.S) 30 if not parsedResult: 31 return [0,0] 32 else: 33 return [parsedResult[0][0],parsedResult[0][1]] 34 35 36 """ 37 该函数实现判断某一个表是否在数据库方案里存在,存在返回True,不存在返回False 38 """ 39 sql = "show tables;" 40 cursor.execute(sql) 41 tables = [cursor.fetchall()] 42 table_list = re.findall('(\'.*?\')',str(tables)) 43 table_list = [re.sub("'",'',each) for each in table_list] 44 if table_name in table_list: 45 return True 46 else: 47 return False 48 def isUrlValid(url): 49 """ 50 由于在爬虫运行过程中发现有些类别招聘信息中含有的详细招聘信息的入口地址在获取响应的时候会抛出Missing Schema异常, 51 发现是url中有些是.../job/...(往往是猎聘网自己发布的招聘信息),有些是.../a/...(这类招聘信息通常是代理发布), 52 导致无法解析,从而使爬虫运行到此处时停止抓取数据。 53 该函数实现对代理发布的URL进行过滤,若为代理发布的信息,则跳过该条招聘信息,函数返回False,否则返回True。 54 """ 55 isValid=re.search('.*?www\.liepin\.com/job/.*?$',url,re.S) 56 if isValid: 57 return True 58 else: 59 return False 60 61 def getPageHtml(url,headers=None): 62 """ 63 返回服务器响应页面的html,不成功返回None 64 """ 65 if not headers: 66 headers={ 67 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36", 68 } 69 70 try: 71 response=requests.get(url,headers=headers) 72 if response.status_code==200: 73 return response.text 74 else: 75 return None 76 except requests.RequestException as e: 77 #debug 78 print('Exception occur in funciton getPageHtml()') 79 80 return None 81 def getEntry(html): 82 """ 83 解析Html,该函数为生成器类型,每一次迭代返回某一子项目的入口地址URL和description组成的字典entry 84 """ 85 86 if not html: 87 #html为None则返回None,无法从该html中解析出子项目入口地址 88 #debug 89 print('html is None in function getEntry()') 90 return None 91 92 soup=BeautifulSoup(html,'lxml') 93 for items in soup.find_all(name='li'): 94 for item in items.find_all(name='dd'): 95 for usefulURL in item.find_all(name='a',attrs={"target":"_blank","rel":"nofollow"}): 96 yield{ 97 "URL":'https://www.liepin.com'+usefulURL.attrs['href'], 98 "URL_Description":usefulURL.text 99 } 100 101 102 def getCountryEntry(entry): 103 """ 104 entry为子项目地址URL和描述URL_Description组成的字典,该函数实现了从子项目页面信息中获取响应,并 105 且最终返回全国子项目地址CountryURL和CountryURLDescription(实际上就是URL_Description)组成的字典 106 """ 107 108 if not entry: 109 #debug 110 print('ERROR in function getCountryEntry:entry is None') 111 return None 112 113 headers={ 114 "Host":"www.liepin.com", 115 "Referer":"https://www.liepin.com/it/", 116 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36" 117 } 118 119 countryHtml=getPageHtml(entry['URL'],headers=headers) 120 soup=BeautifulSoup(countryHtml,'lxml') 121 citiesInfo=soup.find(name='dd',attrs={"data-param":"city"}) 122 123 if not citiesInfo: 124 #debug 125 print('ERROR in function getCountryEntry():citiesInfo is None.') 126 return None 127 128 db=pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='spider') 129 cursor=db.cursor() 130 if not table_exists(cursor,entry['URL_Description']): 131 createTableSql="""CREATE TABLE IF NOT EXISTS spider.{} like spider.positiondescription;""".format(getTableName(entry['URL_Description'])) 132 try: 133 cursor.execute(createTableSql) 134 print('--------------create table %s--------------------' % (entry['URL_Description'])) 135 except: 136 print('error in function getCountryEntry():create table failed.') 137 finally: 138 db.close() 139 140 141 142 return { 143 "CountryURL":"https://www.liepin.com"+citiesInfo.find(name='a',attrs={"rel":"nofollow"}).attrs['href'], 144 "CountryURLDescription":entry['URL_Description'] 145 } 146 147 def getCountryEmployeeInfo(CountryEntry): 148 """ 149 CountryEntry是getCountryEntry函数返回的由全国招聘信息CountryURL和地址分类描述 150 CountryURLDescription构成的字典,该函数提取出想要的信息 151 """ 152 153 if not CountryEntry: 154 #debug 155 print('ERROR in function getCountryEmpolyeeInfo():CountryEntry is None.') 156 return None 157 158 db=pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='spider') 159 cursor=db.cursor() 160 161 indexOfPage=0 162 theMaxLength=0 163 164 #遍历该类招聘信息的每一页 165 while indexOfPage<=theMaxLength: 166 URL=CountryEntry['CountryURL']+'&curPage='+str(indexOfPage) 167 pageHtml=getPageHtml(URL) 168 soup=BeautifulSoup(pageHtml,'lxml') 169 170 #提取出该类招聘信息总共的页数,仅需要提取一次即可 171 if indexOfPage==0: 172 prepareReString=soup.find(name='a',attrs={"class":"go","href":"javascript:;"}).attrs['onclick'] 173 pattern=re.compile('Math\.min\(Math\.max\(\$pn,\s\d\),(.*?)\)') 174 theMaxLength=int(re.findall(pattern,prepareReString)[0]) 175 176 #debug,检测访问到第几页 177 print('Accessing page {} of {}'.format(indexOfPage,CountryEntry['CountryURLDescription'])) 178 #进入下一页 179 indexOfPage+=1 180 181 """ 182 这里代码实现对信息的有效信息的提取 183 """ 184 for detailedDescriptionURL in getDetailedDescriptionURL(soup): 185 #如果详细招聘信息入口URL是代理发布(即无效,这里不爬取这类信息),则跳过该条招聘信息 186 if not isUrlValid(detailedDescriptionURL): 187 continue 188 detailedDescriptionHtml=getPageHtml(detailedDescriptionURL) 189 #将分区标识符(例如java、php等)添加进返回的字典 190 result=detailedInformation(detailedDescriptionHtml) 191 result['ID']=CountryEntry['CountryURLDescription'] 192 """ 193 if 'ID' in result: 194 print(type(result['ID']),'>>>',result) 195 """ 196 if result['Available']: 197 #获取工资最小值和最大值 198 min_max=parseWage(result['wage']) 199 #有些公司没有福利tag 200 reallyTag='' 201 if not result['tag']: 202 reallyTag='无' 203 else: 204 reallyTag=result['tag'] 205 206 insertSql="""insert into spider.{} values(0,'{}','{}','{}',{},{},'{}','{}','{}','{}','{}','{}','{}');""".format(getTableName(result['ID']),result['position'],result['company'],result['wage'],min_max[0],min_max[1],result['education'],result['workExperience'],result['language'],result['age'],result['description'],reallyTag,result['workPlace']) 207 208 try: 209 cursor.execute(insertSql) 210 db.commit() 211 except: 212 db.rollback() 213 #debug 214 print('ERROR in function getCountryEmployeeInfo():execute sql failed.') 215 #爬取完该类招聘信息之后关闭数据库连接 216 db.close() 217 218 def getDetailedDescriptionURL(soup): 219 """ 220 soup为全国招聘信息列表页面解析的BeautifulSoup对象,该函数为生成器,每一次迭代产生一条招聘信息 221 详细内容的URL字符串 222 """ 223 if not soup: 224 #debug 225 print('ERROR in function getDetailedDescroption():soup is None.') 226 return None 227 228 for item in soup.find_all(name='div',attrs={"class":"job-info"}): 229 detailedDescriptionURL=item.find(name='a',attrs={"target":"_blank"}).attrs['href'] 230 yield detailedDescriptionURL 231 232 233 def detailedInformation(detailedDescriptionHtml): 234 """ 235 该函数实现对具体的一条详细招聘信息的提取,detailedDescriptionHtml为一条详细招聘信息网页的 236 HTML,该函数返回值为职位具体要求构成的字典positionDescription 237 """ 238 if not detailedDescriptionHtml: 239 #debug 240 print('ERROR in function detailedInformation():detailedDescriptionHtml is None.') 241 return None 242 243 soup=BeautifulSoup(detailedDescriptionHtml,'lxml') 244 245 #提取出招聘职位和公司,类型为str 246 positionItem=soup.find(name='div',attrs={"class":"title-info"}) 247 #有时候招聘信息被删除了但是招聘信息的入口仍然留在招聘列表中,这里就是防止这种情况导致运行失败 248 if not positionItem: 249 return { 250 'Available':False 251 } 252 position=positionItem.h1.text 253 company=soup.find(name='div',attrs={"class":"title-info"}).a.text 254 255 #提取出工资水平(类型为str,有些是面议)、工作地点、学历要求、工作经验、语言要求和年龄要求 256 items=soup.find(name='div',attrs={"class":"job-title-left"}) 257 wage=items.find(name='p',attrs={"class":"job-item-title"}).text.split('\r')[0] 258 workPlace=items.find(name='a') 259 #有些工作地点在国外,该网站不提供该地区招聘信息的网页,没有标签a,这里就是处理这样的异常情况 260 if not workPlace: 261 workPlace=items.find(name='p',attrs={"class":"basic-infor"}).span.text.strip() 262 else: 263 workPlace=workPlace.text 264 265 #这里返回一个大小为4的列表,分别对应学历要求、工作经验、语言要求、年龄要求 266 allFourNec=items.find(name='div',attrs={"class":"job-qualifications"}).find_all(name='span') 267 268 #有些招聘信息中带有公司包含的福利tag,这里也提取出来,所有tag组成一个由-分隔的字符串,没有则为空字符串 269 tagItems=soup.find(name='ul',attrs={"class":"comp-tag-list clearfix","data-selector":"comp-tag-list"}) 270 tags='' 271 if tagItems: 272 tempTags=[] 273 for tag in tagItems.find_all(name='span'): 274 tempTags.append(tag.text) 275 tags='-'.join(tempTags) 276 277 #提取出详细的职位技能要求 278 descriptionItems=soup.find(name='div',attrs={"class":"job-item main-message job-description"}) 279 description=descriptionItems.find(name='div',attrs={"class":"content content-word"}).text.strip() 280 281 positionDescription={ 282 "Available":True, 283 "position":position, 284 "company":company, 285 "wage":wage, 286 "workPlace":workPlace, 287 "education":allFourNec[0].text, 288 "workExperience":allFourNec[1].text, 289 "language":allFourNec[2].text, 290 "age":allFourNec[3].text, 291 "tag":tags, 292 "description":description, 293 } 294 295 return positionDescription 296 if __name__=="__main__": 297 startURL='https://www.liepin.com/it/' 298 startHtml=getPageHtml(startURL) 299 300 #多进程抓取数据 301 pool=Pool(4) 302 for entry in getEntry(startHtml): 303 countryEntry=getCountryEntry(entry) 304 pool.apply_async(getCountryEmployeeInfo,args=(countryEntry,)) 305 pool.close() 306 pool.join() 307 print('All subprocesses done.')
2.2 代码的部分补充说明
2.2.1 getEntry(html)
爬虫初始入口地址startURL对应于猎聘网下图所示的页面

在该页面对应于代码中的函数getEntry(html),下面是子项目入口地址于HTML中所在的位置:

2.2.2 getCountryEntry(entry)
对应于如下页面:

不仅仅只抓取当前地区,需要抓取全国的招聘信息,因此要进入全国招聘信息的URL,位置如下所示:

第一条href即为全国的入口URL。
除此之外在该函数中还根据每一个招聘信息子分类创建了各自的表,由于有些分类名中含有MySQL数据库表名不支持的特殊符号,所以函数getTableName(ID)功能就是根据分类名ID返回合法表名。
2.2.3 getCountryEmployeeInfo(CountryEntry)
对应如下页面:
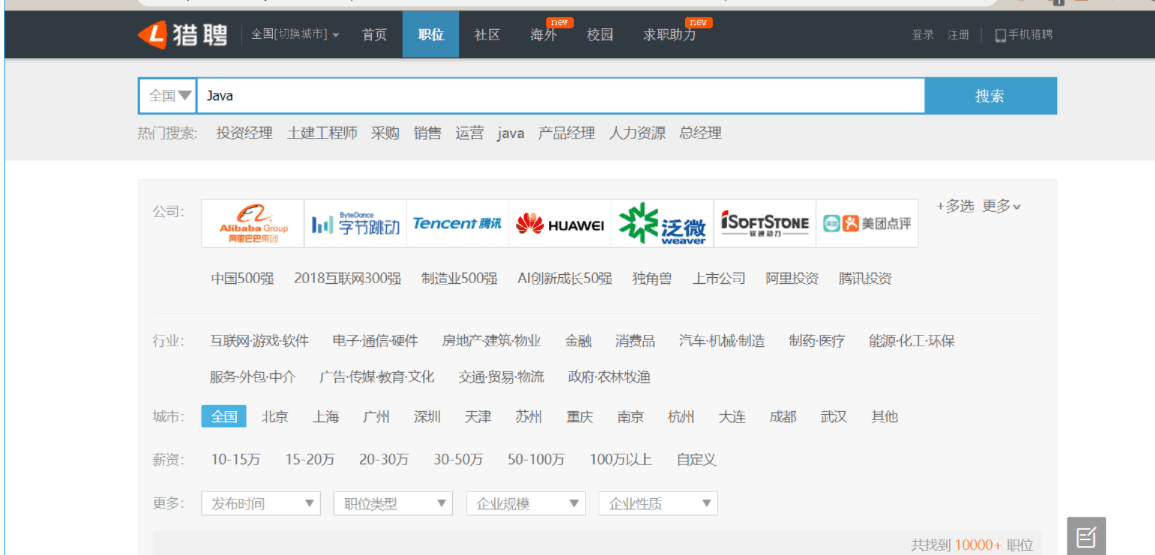
在该页面可以抓取到每一条招聘信息详细信息的入口地址URL,以及该分类(在上图中就是Java)中总页面数量:
招聘信息详细信息的入口地址URL位置如下所示:

总页面数所在位置如下所示(即div class="pager"那一个标签中):

2.2.4 detailedInformation(detailedDescriptionHtml)
对应于如下所示的页面结构:

具体在该页面上抓取的信息所在位置在函数detailedInformation(detailedDescriptionHtml)中表示得很明白。
五、数据库部分
在上面给出的代码中,在函数getCountryEntry中对每一类招聘信息都在数据库spider中(spider是我事先已经建立好的一个schema)建立了相应的表,其中有一个positionDescription表是我在抓取前建立的一个模板表,目的是为了便于各分类表的创建,各分类表的结构都和positionDescription表一样,其字段类型如下所示: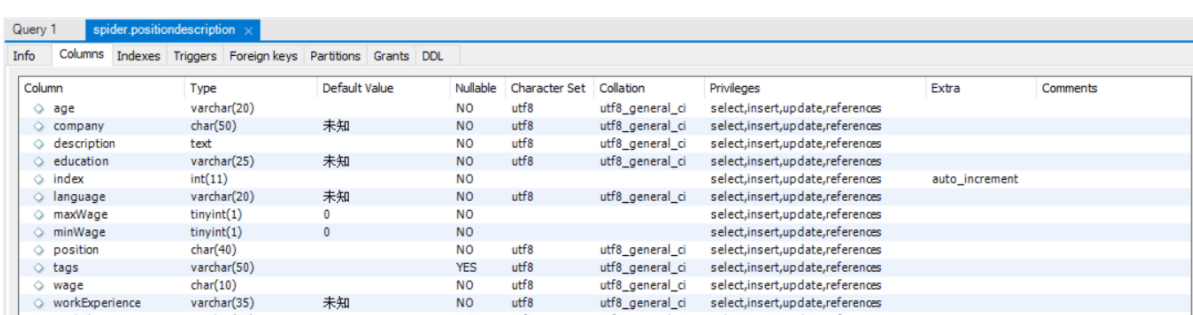
然后抓取之后就会生成各分类的表,这些表的结构和positionDescription表结构完全一样,例如(未完全显示):
六、数据可视化的实现
6.1 直方图
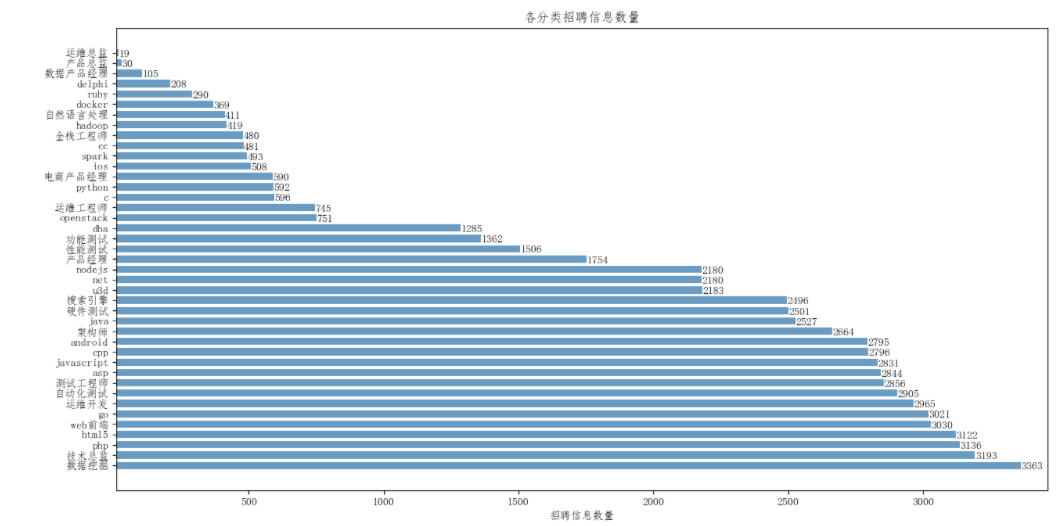
6.1.1 各分类招聘信息数量直方图
import matplotlib.pyplot as plt
import matplotlib
import pymysql
def drawPic():
db=pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='spider')
cursor=db.cursor()
try:
cursor.execute("select table_name as 表名,table_rows from information_schema.tables where table_schema='spider' order by table_rows desc;")
results=cursor.fetchall()
#print(results)
tags=[]
amount=[]
for item in results:
if item[1]:
tags.append(item[0])
amount.append(item[1])
except:
print('failed')
db.close()
#解决中文显示乱码问题
plt.rcParams['font.sans-serif']=['FangSong']
plt.rcParams['axes.unicode_minus']=False
plt.barh(range(len(tags)),amount,height=0.7,color='steelblue',alpha=0.8)
plt.yticks(range(len(tags)),tags)
plt.xlim(min(amount)-10,max(amount)+100)
plt.xlabel("招聘信息数量")
plt.title("各分类招聘信息数量")
for x,y in enumerate(amount):
plt.text(y+1,x-0.4,'%s' % y)
plt.show()
if __name__=='__main__':
drawPic()
效果如下所示:
6.2 圆饼图
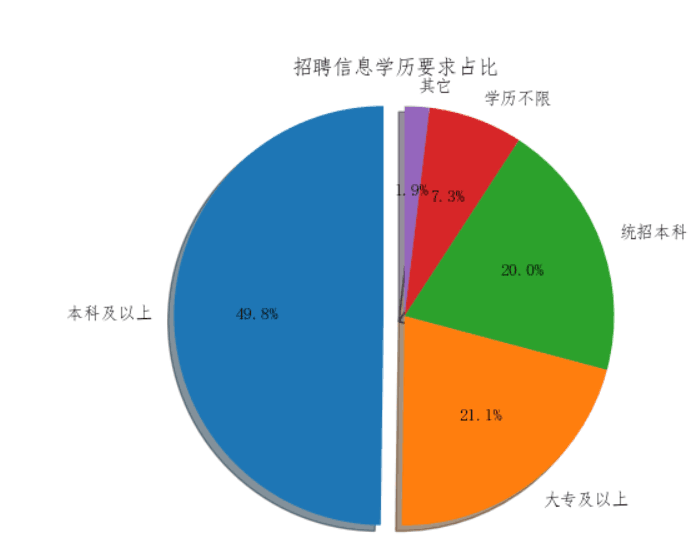
6.2.1 按照学历要求分类绘制圆饼图
代码如下:
import matplotlib.pyplot as plt
import matplotlib
import pymysql
#根据学历要求绘制圆饼图
def drawPic():
plt.rcParams['font.sans-serif']=['FangSong']
plt.rcParams['axes.unicode_minus']=False
labels='本科及以上','大专及以上','统招本科','学历不限','其它'
sizes=[39519/79380*100,16726/79380*100,15844/79380*100,5781/79380*100,(1102+211+197)/79380*100]
explode=(0.1,0,0,0,0)
fig1,ax1=plt.subplots()
ax1.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=True,startangle=90)
ax1.axis('equal')
ax1.set_title('招聘信息学历要求占比')
plt.show()
效果如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号